河海大学 商学院学院 江苏常州 213022
摘要:在我国大力提倡退耕还林的前提下,森林资源得到了有效地保护。由于近几年来森林火灾不断发生,导致森林资源受到巨大的破坏,影响了人们正常的生活以及社会发展。做好目前的森林防火工作,是保护自然生态环境最有效的手段。
关键词: 人工神经网络;森林火灾预警;数据挖掘
森林火灾,是指失去人为控制,在林地内自由蔓延和扩展,对森林、森林生态系统和人类带来一定危害和损失的林火行为。森林火灾是一种突发性强、破坏性大、处置救助较为困难的自然灾害。在各种威胁森林资源的因素中,森林火灾是破坏自然及社会平衡的首要灾害,加之近年来由于人口剧增与工业化速度的加快,以及受厄尔尼诺现象的影响,自然灾害与人为灾害频率增加,互相影响,不仅影响人类生存的环境质量,同时带来巨大的经济损失,引起了世界各国的普遍关注。
在我国大力提倡退耕还林的前提下,森林资源得到了有效地保护。但是随着经济的不断发展,生态环境遭受了严重的破坏。森林作为生态环境中最重要的资源,能够对生态环境起到较好的保护作用。由于近几年来森林火灾不断发生,导致森林资源受到巨大的破坏,影响了人们正常的生活以及社会发展。做好目前的森林防火工作,是保护自然生态环境最有效的手段。 因此,森林火险气象等级的研究有利于森林火灾的预测预防,能为森林防火工作人员针对不同区域不同时间采取不同防火措施提供参考及决策支撑。森林火险气象等级模型能够利用气象部门的天气预测适时显示出目标区域的森林火险等级,能够帮助林业部门有针对性的制定防火策略,分配防火资源,具有重要的实用价值。
在森林火灾灾害风险管理中,灾害风险的评估是其核心部分,森林火灾风险评估主要是运用科学合理的评估方法和手段,对当前森林火灾风险状况进行准确的评估和分析,并有针对性地提出建议和对策以减小风险。在评估的基础上进行风险预测有利于森林火灾风险的预防和预报,从而降低森林火灾风险,减少火灾损失。
森林火灾风险主要取决于致灾因子、承灾体以及防灾减灾能力。致灾因子主要包括气象条件、地形条件、人类活动、植被状况等方面,森林火灾的发生与气候和天气条件密切相关。一般情况下,气温高、降水少、湿度小、风力大,发生森林火灾的风险就越大。
所以我们尝试从气候条件的角度来建立一个森林火灾风险评估模型和指标体系,通过处理历史森林火灾高风险地区的气象信息来完善模型,并预估未来气候变化对对我国森林火灾风险的影响,为大兴安岭林业管理部门进行林火管理提供参考价值。
ANN(Artificial Neural Network)是指由大量的处理单元(神经元) 互相连接而形成的复杂网络结构,是对人脑组织结构和运行机制的某种抽象、简化和模拟。人工神经网络,以数学模型模拟神经元活动,是基于模仿大脑神经网络结构和功能而建立的一种信息处理系统。
人工神经网络具有自学习、自组织、自适应以及很强的非线性函数逼近能力,拥有强大的容错性。它可以实现仿真、二值图像识别、预测以及模糊控制等功能。是处理非线性系统的有力工具。
森林火灾预测模型是根据火灾历史、天气条件 (温度、相对湿度、降水、风速等) 、植被物候状况、可燃物含水量和火源等进行森林火灾预测预警。
首先我们将进行数据的采集工作,获取历史上曾经发生森林火灾的地区的历史气象数据数据,然后进行数据的清洗工作,提取出我们能够使用的数据信息,并将数据集分为测试集、训练集和验证集。
然后我们将结合现有模型及训练集,运用ANN算法和KNN算法构建出多个新的森林火灾预测模型,继而使用各个模型对验证集数据进行预测,并记录模型准确率,选出效果最佳的模型。最后使用测试集进行模型预测,来衡量最优模型的性能。整个研究构想如下图所示。

在火灾等级评测中,我们采用ROC曲线进行二分类分析,即将所有数据划分为高风险和低风险两类。
ROC曲线是指受试者工作特征曲线 / 接收器操作特性曲线, 是反映敏感性和特异性连续变量的综合指标,是用构图法揭示敏感性和特异性的相互关系,它通过将连续变量设定出多个不同的临界值,从而计算出一系列敏感性和特异性,再以敏感性为纵坐标、(1-特异性)为横坐标绘制成曲线,曲线下面积越大,诊断准确性越高。在ROC曲线上,最靠近坐标图左上方的点为敏感性和特异性均较高的临界值。具体ROC曲线的解释根据分析结果进行相关说明。
AUC被定义为ROC曲线下的面积,显然这个面积的数值不会大于1。又由于ROC曲线一般都处于y=x这条直线的上方,所以AUC的取值范围在0.5和1之间。使用AUC值作为评价标准是因为很多时候ROC曲线并不能清晰的说明哪个分类器的效果更好,而作为一个数值,对应AUC更大的分类器效果更好。
数据来源:
①大兴安岭地区历史发生的森林火灾情况统计(2011年——2016年火灾等级、火灾发生次数、火灾发生范围、火灾造成的损失,数据来自中国林业统计年鉴)
②大兴安岭地区历史气象信息(2007年4月——2018年4月每日平均温度、大气压、露点温度、能见度、降雨量、风向、风速、最高温度、最低温度,数据来自NOAA美国国家气象局)
③大兴安岭地区历史火险等级(2011年4月——2018年4月历史每日的火险气象等级,数据来自大兴安岭森林防火网)
数据清单:
①站点选取:大兴安岭地区呼玛气象站。
②站点气象信息:
NO: 表示本条记录的编号,每条记录以天为单位记录信息。
YEARMODA:监测日期,该条记录发生的时间,具体到年月日。
TEMP:表示所检测的站点空气冷热程度的物理量,即每日气温定时观测值中的平均值,该单位为摄氏度(℃)
DEWP:露点温度,即每日露点温度定时观测值中的平均值。露点温度是指空气在水汽含量和气压都不改变的条件下,冷却到饱和时的温度。形象地说,就是空气中的水蒸气变为露珠时候的温度叫露点温度。露点与气温的差值可以表示空气中的水汽距离饱和的程度。
STP: 本站气压,即每日气压定时观测值中的平均值。气压是作用在单位面积上的大气压力,即等于单位面积上向上延伸到大气上界的垂直空气柱的重量。气压大小与高度、温度等条件有关。
WDSP: 风向风速,即每日风向风速定时观测值中风向的结果和风速的平均值。
MXSPD: 最大风速,即每日风速定时观察值中的最高值。
MAX: 最高温度,即每日气温定时观测值中的最高值,单位℃。
MIN: 最低温度,即每日气温定时观测值中的最低值,单位℃。
RCP: 降雨量,即每日20:00.20:00时降水量的综合值。
监测日期:即大兴安岭森林防火官方网站中对于森林火险等级有预报日期,具体到年月日,一个日期对应一条火险等级信息。
火险等级:即大兴安岭森林防火官方网站中气象信息中对于火险等级的预测值,用于火险预报和森林防火保护工作。
④数据范围:从2007年1月到2018年4月,其中每年2月,8月,11月,12月无火险等级信息,部分天数的火险信息缺失,时间越往前,信息缺失的天数越多,火险信息数据表中包含所有可能获取的等级信息;从2007年1月到2018年4月,包括每一天的气象信息,具体到每个气象指标,部分气象指标数据有缺失。
站点气象信息采集:下载自美国国家海洋和大气管理局网站,格式为Excel,每条记录包含气温,露点温度,气压,风向风速,最高最低气温等气象指标。
站点气象信息处理:
①整理下载表格,按照时间顺序由近到早进行排序。
②删除缺失指标数据,例如阵风和雪深度指标基本全部缺失,对此类数据进行删除。
③删除含有错误数据的指标,比如在一段时间内,突然出现温度或者其他指标有特别明显大幅度变化的数据,核查比对,如果错误进行删除。
站点火险等级信息采集:大兴安岭森林防火网,用八爪鱼采集器获取每一期气象信息,采集到的表格包括每一期火险等级信息发布的时间具体到秒钟,以及描述该等级的相关文字描述。
站点火险等级信息处理:
按照时间顺序重新排列数据,顺序由现在到以前。
②由于采集到的等级信息是文本信息,加上格式不齐整,无法直接用来分析,所以我们一条一条的修改成为我们需要的格式
③由于采集得到的时间具体到秒,与气象信息不匹配,因此修改日期准确至天,也是人工修改
④删除缺失等级信息,有部分天数的等级信息存在缺失,可能是网站没有发布或是采集过程中出现错误导致
⑤删除采集器采集的重复信息,同样是因为采集过程或是原始网站信息出现错误。
信息整合:
删除整合表中火险等级缺失的记录,部分天数的信息中,气象数据信息是完整的,但是火险等级信息缺失,对此类记录进行删除操作,人工处理
②将火险等级1-2级替换成低风险,火险等级3-5级替换成高风险。
森林火险气象等级预测模型的主要输入变量为气温、风速、气压等气象要素,输出结果为火险等级。
首先我们采用随机抽样的方法对777条火险天气数据进行抽样并建立训练集和测试集,抽样比例为7:3。
levels(Sonar$CLASS)<-c(0,1)
#随机抽样,建立训练集和测试集,抽样比例是7:3
set.seed(777)
select<-sample(1:nrow(Sonar),nrow(Sonar)*0.7)
train<-Sonar[select,]
test<-Sonar[-select,]
然后对数据进行中心化和标准化处理,得到均值为0,标准差为1的服从标准正态分布的数据,中心化的目的是为了增加基向量间的正交性,标准化的目的是为了消除特质值之间的差异性。下图是对训练集集中平均气温进行中心标准化前后的对比情况。
train[,1:9]=scale(train[,1:9])
test[,1:9]=scale(test[,1:9])
图1. 中心标准化前的平均气温散点图
图2. 中心标准化后的平均气温散点图
由图可见,对数据进行中心标准化后,数据在每个维度上的尺度都是一致的。
之后,使用R语言的nnet包中的nnet()函数构建人工神经网络模型。
library(nnet)
mynnet<-nnet(CLASS~., linout =F,size=14, decay=0.0076, maxit=200,
data = train)
out<-predict(mynnet, test)
out[out<0.5]=0
out[out>=0.5]=1
summary(mynnet)
下图为人工神经网络训练的结果,通过输入TEMP、 DEWP 、SLP、 STP、 VISIB、 WDSP 、MXSPD 、MAX、 MIN ,可以得到当前天气状况下的森林火险等级CLASS。

图3. 人工神经网络模型结果
将ANN模型训练的结果与测试集的结果进行对比,可以得到下图所示的ROC曲线:
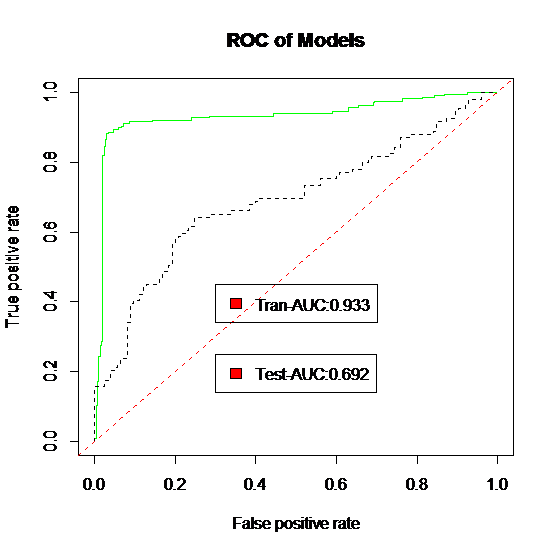
图4. ROC曲线
结果显示,经过ANN训练过的模型的预测准确率可以达到0.933,而未经训练的预测准确率只有0.692,说明此ANN模型有较高的准确性,可以供林火管理部门进行森林火险气象等级的预测。
为了形成对照,我们引入KNN算法对本案例进行预测模型构建,对比两种模型准确度。
KNN算法的主要原理是根据距离函数计算待分类样本X和每个训练样本的距离(作为相似度),选择与待分类样本距离最小的K个样本作为X的K个最邻近,最后以X的K个最邻近中的大多数所属的类别作为X的类别。
在研究不同气象条件影响森林火险等级的问题中,我们没有将气象数据和火险等级数据一起进行聚类分析,而是先对气象信息进行聚类分析,将所有的气象信息分为5类,然后将聚类结果与这些气象信息所对应的火险等级进行比较,以此来判断是否适合用聚类算法对气象信息进行分类,进而构建森林火险气象等级预测模型。
首先我们将777条数据中的前555条取为训练集,后222条作为测试集。然后调用class包中的knn()算法对训练赛的数据进行分类,分类结果见下。
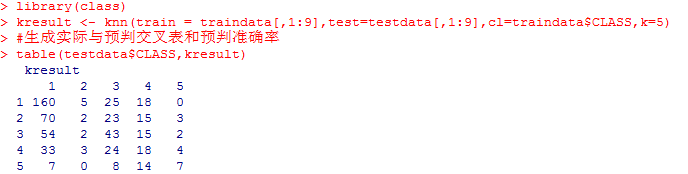
图5. KNN分类结果
图6.结果条形图
然后我们用测试集的数据来检验KNN分类算法的结果。
![]()
结果表明运用KNN聚类算法对火险天气进行聚类分析的准确度仅为44.32%。
ANN预测模型 | KNN聚类预测 | |
模型的预测准确度 | 93.3% | 44.3% |
通过对比三个模型的预测效果,可知ANN预测模型的预测效果要更好,其预测的准确度达到93.3%,所以选择ANN预测模型来预测不同气象条件下发生森林火灾的风险程度
研究结果显示整个大兴安岭地区的森林火灾发生次数正呈逐年下降的趋势,每年因森林火灾而导致的受灾森林面积和伤亡人数也呈逐年下降的趋势,但是每年因森林火灾而导致的直接经济损失基本趋于平稳,并没有明显的变化趋势。
大兴安岭地区的气候主要呈现4-6月平均气温高、平均风速大、平均气压低,其他月份平均气温低、平均风速小、平均气压高的气候特征。同时4到6月也是大兴安岭地区森林火灾的高发时期,主要有4-6月间空气较为干燥、气温偏高且变化速率大、平均风速大、受积雪融化而导致枯草落叶裸露等原因。
在影响森林火灾的各种气象因子中,森林火险的风险程度与平均温度、平均风速呈正相关的关系,与平均气压呈负相关的关系,温度越高,风速越大,气压越低,出现高风险的火险天气的概率也就越大。
通过ANN算法构建的森林火险天气预测模型,能够较好地根据大兴安岭地区的气候状况来预测当前天气状况下发生森林火灾的风险程度,可以较好地为林火管理部门在进行防火工作中提供建议。
参考文献:
[1]毛国君,段立娟,王室等.数据挖掘原理与算法[M].北京:清华大学出版社,2005
[2]Jiawei Han,Micheline Kamber.数据挖掘:概念与技术[M].范明,等,译.北京:机械工业出版社,2007
[3]赵健宇.基于机器学习方法的森林火灾预测研究.自动化应用.2019年(09):6-8
[4]蔡奇均;曾爱聪;苏漳文;郭福涛.基于Logistic回归模型的浙江省林火发生驱动因子分析.西北农林科技大学学报(自然科学版).2020年(02):108-115
作者简介:李络绎(1999-),男,福建龙岩人,河海大学本科在读,信息管理信息系统方向
徐宁馨(1999-),女,江苏常州人,河海大学本科在读,信息管理信息系统方向

客服QQ:30444492琼网文【2021】1550-113号
增值电信业务经营许可证:琼B2-20210322
出版物经营许可证:新出发龙华出字第(2021)009号
广播电视节目制作经营许可证:(琼)字第00779号
版权所有 ©2002-2024 期刊网(www.qikanchina.com) 琼ICP备2021005105号



