国网内蒙古东部电力有限公司通辽供电公司 内蒙古 赤峰 024000
摘要:我国智能化电网的发展迅速,电力系统经常性会更换和升级,在处理海量数据的时候,也会遇到较大挑战,为更好发展智能化电网,电力企业需要充分注重电力大数据平台优化,促使提取数据的最大化价值,提升数据立体的效率。本文主要基于作者实际工作经验,简要的分析智能电网大数据的降维管理,希望对有关从业人员带来帮助。
关键词:大数据;智能电网;降维管理
前言:对于智能电网数据比较多,维度比较高,难以识别技术问题,提出降低大数据维度的构想,设计出基于随机森林算法的物联网智能化电网大数据管理的系统。经过采用Bagging算法,对数据的样本实施训练、学习,建立多个决策树构型,按照少数多数投票法原则,确定出建立成熟随机森林算法的模型,经过随机森林算法模型把智能电网大数据就高纬度到低纬度,下面主要对大数据处理难度的减少,优化数据处理效率,为智能化电网健康和有序运行奠定坚实的基础。
1 智能化电网电力大数据概述
1.1智能电网信息数据
如今是个信息化时代,信息技术在随着科技的进步而发展,人们的生活水平也逐渐提高,对电力的需求越来越大,电力系统的正常运行会有大量信息的数据产生,这些数据信息的内容是比较丰富的,在智能电网在电力行业的发展也是越来越快。通常智能电网数据信息分为电力企业内部数据和电力企业外部数据两种,一般内部数据通过电力系统在数据信息采集和配电管理以及提供服务过程中产生的,然而外部数据就是指地理信息和气象信息等,获取数据信息的方法是多种多样的,所以会在一定程度上增加职能电网数据的处理难度。
1.2建立一个智能大数据电网平台
在人们用电需求量不断增加过程中,多元化的用电套餐供人们选择,电网在运行的数据信息产生的就会逐渐增多,那么采集数据和工作分析的难度也有所增加,对于复杂的情况,电力企业对于这项工作已经不能完全应对。智能电网的应用主要是在信息技术构建的网络大数据平台中,能够快速的处理大数据信息,并且确保数据信息的准确性。在电力企业中运用了大数据关键技术,能够合理分类与高效的处理数据信息,有利于电力企业信息处理效率的提高。1.3云计算,智能化电网和大数据的关联
智能电网大数据、云计算和大数据的联系是非常重要的,智能电网主要是整合了计算机技术和信息技术。在协调配合使用原有的输配电设施,有利于让电网能够安全、高效的运行,同时还能够对供电带来的不利影响的环境因素有所缓解,便于新型电网的建立。其中云计算和大数据主要是对网络技术进行利用,从而便于采集、监控网络数据信息。然而建立大数据主要是要使用云计算功能,其中云计算具有强大的数据储存功能和分析功能,能够为大数据业务提供了更好的方式,所以大数据的前提条件就是云计算的运用。总而言之,大数据、云计算以及智能电网之间的关系是相互帮助相互制约的,结合使用能够有效提高其他技术性能。
2 方案的构架设计
智能化电网通常是聚集发电、输电、配电、变电、用电、调度等环节综合电网,结构比较繁杂,数据库较大。在用户获取大量高纬度数据库的时候,难以直观认识,难以发现数据之间隐含的关系。经过降纬能够发现肉眼不能发现的规律,进而利于用户对智能化电网数据的分析、研究,及时的解决低纬发现问题。在本文的设计阶段,就对智能电网数据实施降纬管理架构大致如图所示:系统包含了数据采集层、数据传输层、数据处理层、数据分析层、数据应用层,下面就将其各层次进行说明。
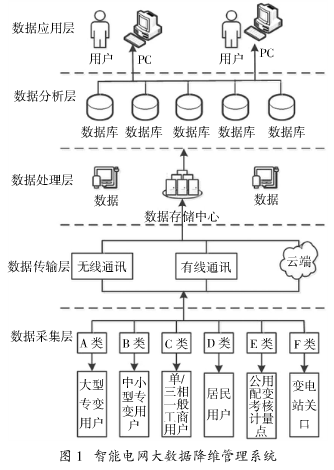
数据采集层中,应用TMS20F2812作为运算控制的核心,控制电网的数据采集,以IEC61970为智能电网的数据采集平台,采集各数据,并且实现和上层设备数据通讯、传递。在该数据采集层中可以实现A类、B类、C类、D类、E类、F类等设备的数据采集,提供直测数据、复制数据、定制数据等服务类型。
在数据传输层可以采用IEEE C37.118通讯协议实现底层数据采集、数据处理层之间的数据传输、通讯,采用基于TCP/IP的Socket技术完成底层与上层数据的通讯,因为智能电网数据信息采集涉及面广,不同用户出于成本考虑,还需采取RS232、CAN、以太网等三个方式将其数据信息经过数据传输层传递到数据处理层中,在该层中,直接测量出的数据能够经
过上传云端实现数据永久性的存储。
在数据的处理层中,数据存储中心就接收到底层传递的各数据,因为数据繁多和类型的不等,对用户来讲,增加识别难度,应用效率的低下,还需对其数据实施预处理,进而增加可识别度,提升数据读取的质量。通常采用方式是数据清理、数据集成、转换、数据规约,数据清理主要是填补数据缺失值,使得数据的噪声平滑,将其离散点识别出来,纠正数据中不一致信息。数据集成、转换通常是对多源数据集成,采用大数据机器学习规律、算法对其实施学习,训练成容易处理的方式,可以便于对其数据之间潜在的规律进行发现。数据规约主要是在接近、保持原始数据完整性的过程中,将其数据集规模逐渐减小,促使数据分析更加有效。
在数据分析层中,对于电网大数据的信息进行减维处理,因为在数据分析层中接收到的数据是经过预处理后的数据,在计算数据的过程中,效率比较高。在本数据层,选取随机森林算法的模型,对其预处理后的数据进行处理。随机森林作为一种特殊的bagging方法应用在智能电网大数据处理阶段,实现数据不同的分类,增加数据分类的能力,经过用户按照需求设定出不同属性,促使用户可以快速从浩瀚的智能电网大数据库中找出期望数据,主要算法主要是在下文进行说明:
在数据应用层中,用户按照计算结果直接可用到各用途,数据应用层可以为计算机、计算机用户、集成在计算机上的各应用程序、显示器,在应用层中,直接、间接的向用户提供各种处理后的数据服务,使得用户便利的应用该数据,实现从数据采集层到接收最终处理,用户按照来自底层数据信息,获得设备底层的情况,进而进行快速干预,利于智能化电网健康和高效的运行。
3 基于算法模型降维的方法
把随机森林算法模型应用在智能化电网大数据中,将给实现对智能电网的大数据降维,实现电网数据时间的复杂度、空间复杂程度的降低,电网各数据集中所夹杂的数据、噪声数据等被过滤,为电网健康运行提供良好的工作条件。随机森林主要是经过有放回方式,将其原始样本中随机抽取的部分样本产生新的样本集合,重复操作会产生多样本的集合,各样本的集合后续会产生一棵决策树。
第一,数据的选择。在智能化电网数据采集层生产大量数据的时候,按照用户的需求选取样本数据库。
第二,预处理。因为数据集包含大量不平滑的信息,其中包含过多数据的噪声,这些噪声会干扰造成算法的误差存在,使得计算的不准确,在数据降维的时候,需要移除不准确的信息量,或是清除和用户无关的数据。执行不便识别数据转化成易于识别规范数据信息的处理过程,在预处理的时候,采用bagging集成学习方法进行学习数据集,比如说在学习的过程中,就原始样本训练集合中随机采样固定个数样本,每采集的一个样本,就需要放回一个样本,之后进行重新采样,若是对有N个样本训练集做T次随机的采用,因为采用随机性,T次采样结果就是各不相同的,每次结果的输出频率最多数据,是最终数据的模型,把该点设置成当前节点为叶子节点。
结束语:
总而言之,为了满足大数据时代的相关需求,要促进产品服务的提高,电力企业需要对大数据相关技术和驱动系统进行充分利用,不断创新和发展,让智能电网的地位得到有效提升,并且促进电力企业竞争力的提高。在大数据信息时代中,在电力行业运行中,大数据的作用是非常大的,所以电力公司需要对现代技术进行充分利用,推动电力行业健康可持续的发展。 参考文献: [1]乔茂斌.面向智能电网应用的电力大数据关键技术[J].资源节约与环保,2015(8):2-2. [2] 刘杰.智能电网中的电力大数据应用[J].电子技术与软件工程. 2018(23). [3] 任莉.浅论大数据时代数字资源对智能电网发展影响[J].通讯世界. 2018(06). [4]王孝亮.面向智能电网应用的电力大数据关键技术应用[J].工程技术:全文版,2017(02):189-189.

客服QQ:30444492琼网文【2021】1550-113号
增值电信业务经营许可证:琼B2-20210322
出版物经营许可证:新出发龙华出字第(2021)009号
广播电视节目制作经营许可证:(琼)字第00779号
版权所有 ©2002-2024 期刊网(www.qikanchina.com) 琼ICP备2021005105号



