1. 国家消防工程技术研究中心 天津 300380 2. 天津盛达安全科技有限责任公司 天津 300380
摘要:本文涉及一种用数字音频水印进行语音信号篡改检测与恢复的方法,该方法将原始信号的压缩版本作为水印信号,因此该水印信号不包含其他的冗余信息,在恢复时也不需要其他与原始信号相关的信息,因而该水印具有自恢复性。根据数字水因信号的冗余性,水印信息被嵌入到信号最低有效位中(least significant bits, LSBs)。水印信号可以准确定位信号破碎区域并对其进行恢复。水印信号在能保持较高的信噪比的同时还能够有令人满意的恢复 效果。
关键词:音频;篡改;检测;恢复
一、引言
数字水印技术的原理为利用图像及声音等媒体信号的冗余性,在原始信号中嵌入有关的信息来保护原始信息,根据使用范围和意义的不同,这种嵌入的信息可以是关于数字信号的版权信息,也可以是由原信号压缩得到的码率比较小的水印。嵌入的信号能很好的隐藏在原始信号下不易被察觉,不会对原始水印造成影响。这种技术能够在一定程度上保护数字信号的版权,也能利用嵌入水印的特性尽可能的对受到破坏的信息进行恢复,由此达到抵挡恶意攻击的目的。
二、算法解析
本算法分为水印的嵌入过程和水印的提前恢复部分
1、水印的嵌入过程为:
(1)将原始信号分帧,该发明采用的方法是将信号相邻n个采样点分为一帧,帧与帧之间没有重叠部分。
(2)对帧进行分组,记每一个帧组中包含m个帧。记原始信号中共有N个采样点,而通常情况下N并不是 的整数倍,对于这种情况,为了简化后面的处理,对原始信号进行补零。
(3)分帧结束后,将原始数据进行压缩,使用的方法是对原始信号的幅度值除以系数c,得到压缩后的数据。
(4)通过随机数算法,打乱帧的顺序,并将相邻的m个帧组成一个帧组。
(5)对上述数据向量进行线性变换,得到未量化的参照值。而随机的帧序列是又一个随机数种子生成的,在嵌入水印过程又提取水印过程中,双方采用同一个种子,则可以保证嵌入/提取过程中操作的帧组是同一的帧组。
(6)对参照值进行量化操作。
(7)把一帧的序号(64bits表示),320bits的五层最高有效位,以及345bits的参照值放入一个哈希函数中,来产生一个31位长的哈希序列。随机生成一个哈希序列,对于每一帧,使用自身数据相关的哈希序列与随机序列异或生成定位数据。
(8)随机生成一个31位长的哈希序列,对于每一帧,使用自身数据相关的31位哈希序列与随机序列异或生成的31位数据作为定位数据。
(9)将31位定位数据与前文中提到的345位参照值数及8位补零数据一同组成384位替代六层最低有效位数据的水印数据。
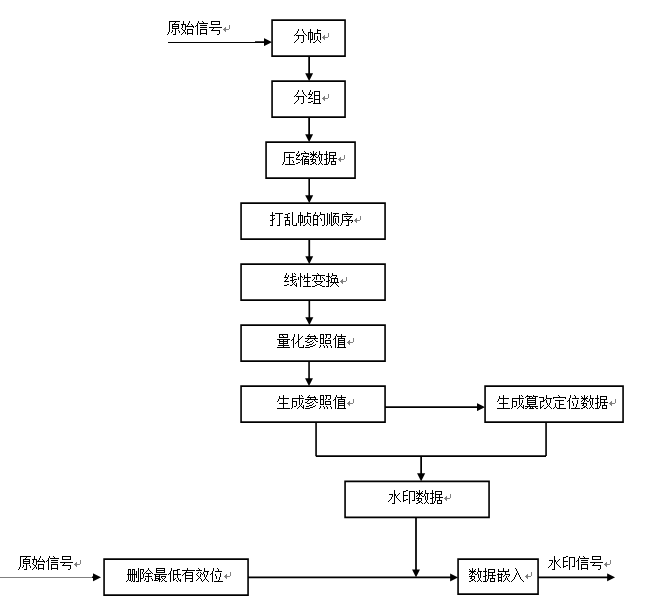
图1 水印的嵌入流程图
2、水印的提取恢复过程为:
(1)对信号进行分帧分组后,提取信号六位最低有效位,并将每个帧中的最低有效位数据分为两组,一组是用于恢复数据的参照值,另外一组是定位篡改区域的定位数据。每帧中的六位最低有效位共计384位,而其中用于恢复数据的参照值共计345位,而定位数据有31位,篡改区域定位的第一步就是抽取原始数据中31位定位数据。
(2)得到31位定位数据后,抽取十层最高有效位640位内的内容,与这帧的序号64位,以及345位参照值一同,放入哈希函数中计算出一个31位长的哈希序列。通过定位数据判断某帧是否被破坏
(3)经过哈希函数得到的31位哈希序列再与提取的31位哈希序列进行异或运算,得到最终31位定位数据。如果在受损定位后发现某个帧组的全部帧都没有受损,那么恢复过程将跳转到下一个帧组。
(4)判断某帧是否被破坏。
(5)接收方接收一个信号后,通过与嵌入方相同的随机种子生成嵌入方嵌入水印的帧分组排序,进而获得分组信息。
(6)如果在受损定位后发现某个帧组的全部帧都没有受损,那么恢复过程将跳转到下一个帧组。
(7)将提取方提取出的量化参照值经过处理后得到未量化的参照值。
(8)通过计算得出受破损区域内的信号数据。
(9)标准化篡改恢复信号。
图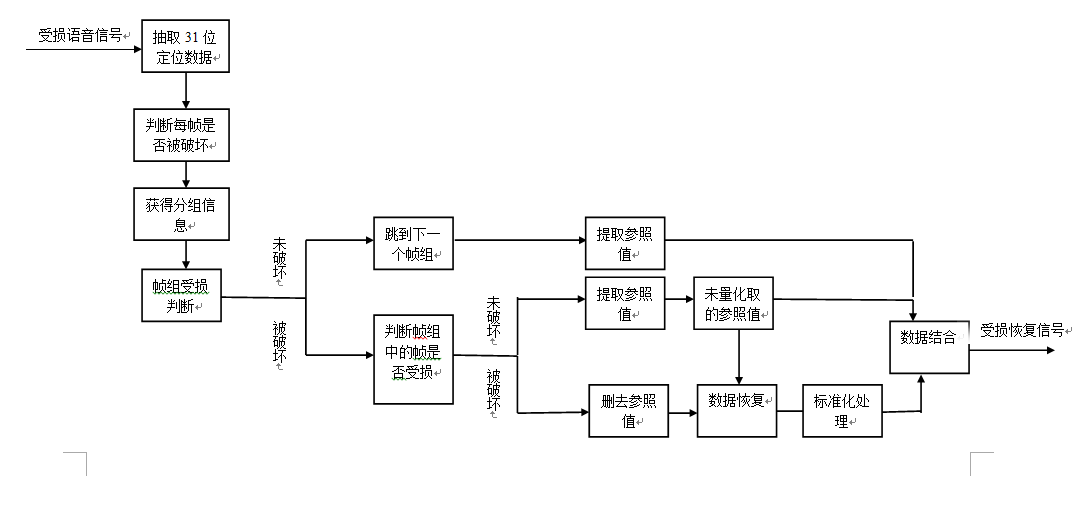 2 水印的提取恢复流程图
2 水印的提取恢复流程图
三、总结
水印技术在图像领域有一定程度的发展,但是同类算法在音频领域内并不多见。传统的水印认证技术着重于检测信号是否遭受过破坏,测试信号的完整性,不能进一步准确高效的处理音频信号并将其修复。此算法可准确定位语音受损部分,并进行恢复。
参考文献:
[1] Cox IJ, Mliier ML,The first 50 years of electronic watermarking, J Appl Signal Process 56(2):225-230, 2002
[2] Ozer H, Sankur B, Memon N, An SVD-based audio watermarking technique, In:Proceedings of the 7th ACM workshop multimedia security, New York:51-56, 2005
[3] El-Samie EFA, An efficient singular value decomposition algotithm for digital audio watermarking, Int J Speech Technol 12(1):27-45, 2009
作者简介:李建(1990—),女,汉族,河北人,软件工程师,研究方向:软件研发、算法设计。

客服QQ:30444492琼网文【2021】1550-113号
增值电信业务经营许可证:琼B2-20210322
出版物经营许可证:新出发龙华出字第(2021)009号
广播电视节目制作经营许可证:(琼)字第00779号
版权所有 ©2002-2024 期刊网(www.qikanchina.com) 琼ICP备2021005105号



