武钢集团昆明钢铁股份有限公司 云南省昆明市安宁市 650302
【摘要】Excel是各行统计人员必不可少的工作软件,利用好Excel强大的数组公式组合可以大大提升统计人员的工作效率,本文从个人经验介绍几个Excel数组复合公式在人力资源薪酬业务数据统计中的卓越运用。
【关键字】Excel软件;人力资源;薪酬统计;数组公式
笔者就职于一家国有大型企业,在册职工近12000人,日常工作中经常要对这些人员进行各种类型的薪酬数据统计分析,如果对Excel还停留在加减乘除及SUM、AVERAGE、IF等简单公式的应用水平,那么对于12000人复杂的薪酬数据分析将会是一个费时费力、效率低下甚至无法完成的工作。现笔者根据多年的工作经验,通过一些实例对几个有用的Excel数组公式用法进行分享。
笔者接到一项工作任务,首先有这么一个Excel表格,我们把这个表叫“原始数据表”:
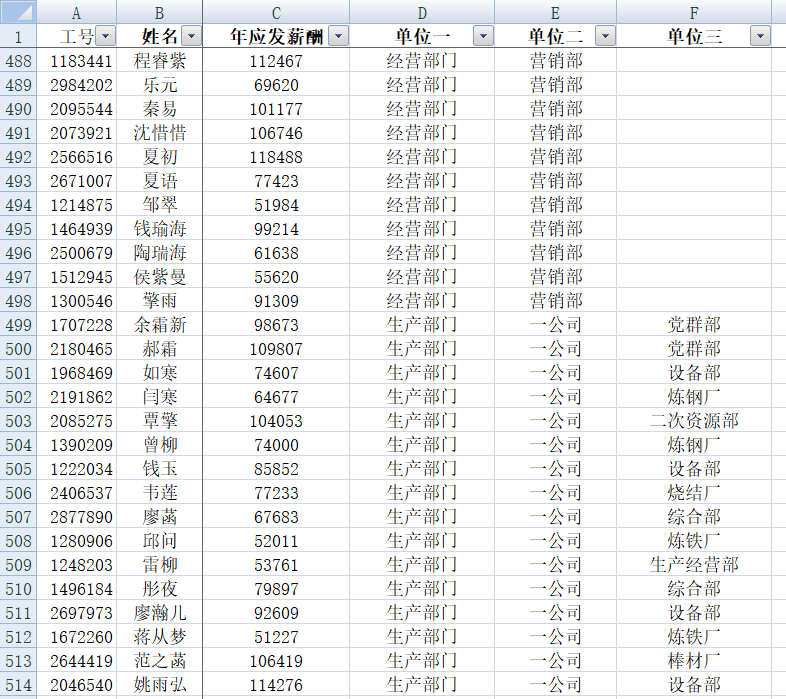
此表为笔者单位所有11962人的一年内的应发薪酬信息(表格中的所有信息均为随机化名),每人分别对应单位一、单位二、单位三共3个单位类别,现要求将该表:
1、分别以“单位一”“单位二”为分类字段,按各单位所有年人均薪酬进行排序;“单位二”中包含有三个大单位分别为“一公司、二公司、三公司”, 三个公司人数占整个公司总人数81%,于是还要单独将这三个公司的年人均薪酬进行排序;也就是按照不同类别的单位排序,并将结论填在下表:
xx公司/部门年人均薪酬情况排序 | |||
排序 | 单位 | 统计人数 | 年人均薪酬 |
1 | | | |
2 | | | |
3 | | | |
4 | | | |
5 | | | |
6 | | | |
8 | | | |
…… | | | |
| | | |
| 合计 | | |
2、除了按单位排序,还要根据相同单位分类字段对个人薪酬排名的“前10后10”进行排序,并填入下表:
xx单位/部门员工年应发薪酬前10后10排序 共统计人数 人 平均年应发薪酬 元/人
名次 | 前10排序 | 工号 | 姓名 | 单位 | 备注 | 后10排序 | 工号 | 姓名 | 单位 | 备注 |
1 | ||||||||||
2 | ||||||||||
3 | ||||||||||
4 | ||||||||||
5 | ||||||||||
6 | ||||||||||
7 | ||||||||||
8 | ||||||||||
9 | ||||||||||
10 |
笔者一开始使用排序、分类汇总、复制粘贴等常规方法进行操作,但是由于人数非常多,实际操作起来非常麻烦,稍有不慎就全盘重来,而且以上常规的方法是在当前工作表中进行操作,会同步改变原始数据位置,非常不利于按单位/部门的排序表进行原始数据取数。
这时笔者发现了一个日常很少使用到的Excel功能——数组公式。数组公式和函数的结合可以解决很多复杂的数据统计分析。那么,什么是数组公式呢?
一、数组公式
数组公式可以认为是Excel公式的一种扩充,是Excel公式在以“组”为参数的复合型应用。当要对某一组数据进行两次以上的计算分析,数组公式就显得特别重要。同普通公式一样,数组公式也必须选择单元格来存放结果,同样以“=”开头,最主要的不同是输入或修改数组公式后必须同时按“Ctrl+Shift+Enter”组合键(简称“数组三键”)来结束,否则会出现错误提示或错误结果,没有使用组合键会产生不同的数据。下边我们由简到繁,从普通公式到数组公式来介绍大幅提高薪酬统计工作效率的Excel功能。
二、使用数组公式进行数据分析
(一)以“单位一”为分类字段,按各单位所有年人均薪酬进行排序
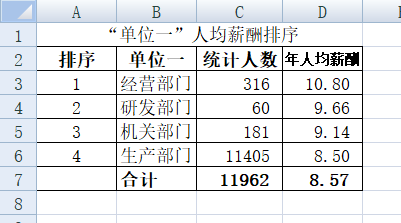
“单位一”类别中共有4个部门,我们首先设计好表样,把4个部门名称输入到工作表,如下图所示:
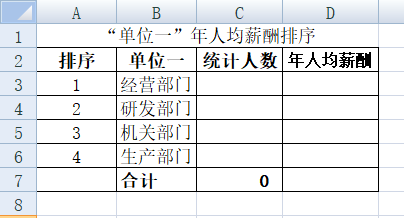
C列的公式设置比较简单,只需要计算出“原始数据表D列”中包含有匹配字段的单元格数目有多少,所以我们使用COUNTIF函数,语法结构 COUNTIF(range,criteria),表示在range范围内满足criteria条件的单元格数目,criteria的形式可以为数字、表达式或文本。在C3单元格输入公式“=COUNTIF(原始数据!D:D,B3)”,计算在“原始数据”这张工作表中的整个D列包含有B3单元格字段“机关部门”的单元格数目,也就是计算机关部门有多少人数,回车后下拉单元格,Excel会自动变更关键字段的单元格进行计算填充。
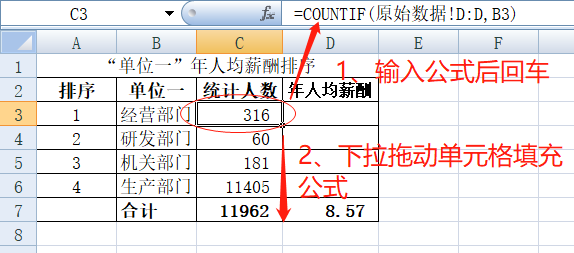
完成C列的计算后,再来看D列。D列的步骤要分两步:第一步在“原始数据C列”中找到匹配B列字段的单元格是哪些,第二步对这些数据进行平均求值。非常典型的数组公式应用场景,在这里我们使用Average+If数组公式实现指定条件求平均值,Average表示在指定区域内对同时满足多个条件的值进行求平均值,而IF用来设定条件。D3单元格中输入“=AVERAGE(IF(原始数据!$D:$D=B3,原始数据!$C:$C))/10000”,同时按Ctrl+Shift +Enter“数组三键”,返回所求平均值结果,继续把鼠标移到D3 单元格右下角并进行填充。如下图所示:
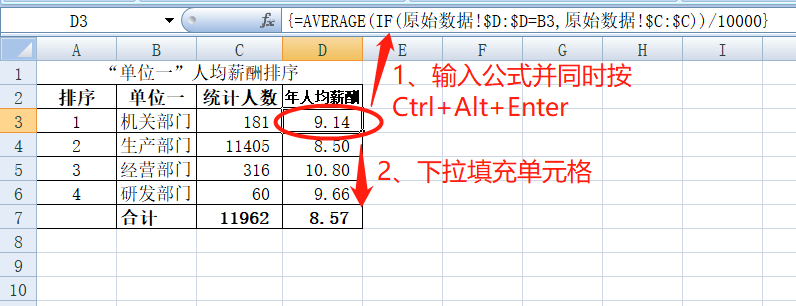
下边我们重点将对此数组公式“{=AVERAGE(IF(原始数据!$D:$D=B3,原始数据!$C:$C))/10000}”进行分析:
1、$D:$D 是对D列数据绝对引用,无论怎么复制拖动公式都不会变,而且对于复杂型表格例如有合并单元格格式时,都会强制指定提取整个D列数据。
2、“原始数据!$D:$D”以数组形式返回原始数据工作表中D列中的所有值, If 的条件“原始数据!$D:$D=B3”等同于“原始数据表D列”所有数据是否等于"机关部门",如果相等定义为 True,否则定义为 False;
3、定义为 True,返回“原始数据!$C:$C”同行号对应的数据,否则返回"";
4、对定义True而返回所有数据求平均值,这里需要精确到万元来表示年人均收入,而我们原始数据表中的单位为元,所以在公式结尾添加一个“/10000”来转换。注意最后必须同时按“数组三键”Ctrl+Shift +Enter结束,从而返回原始数据表中“机关部门”的所有人年平均收入为9.14万元。
在完成以上操作后,选中B3:D6区域,以D列的“年人均薪酬”进行降序排序,就得到了最终结果(表中合计行中C7和D7的数据就是简单的求满足条件的单元格数量和所有单元格的求平均值,这里就不再过多赘述):
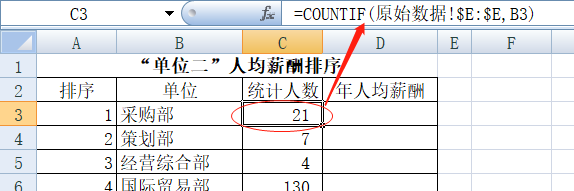
(而)以“单位二”为分类字段,按各单位所有年人均薪酬进行排序
首先把所有单位名称排在B列,C列同样以“COUNTIF”普通公式来计算相关单位的人数有多少,C3单元格输入“=COUNTIF(原始数据!$E:$E,B3)”,表示在“原始数据”表E列中和B3单元格相同的数据个数,即等于“采购部”人数,直接回车然后下拉单元格填充公式,得出C列数据。
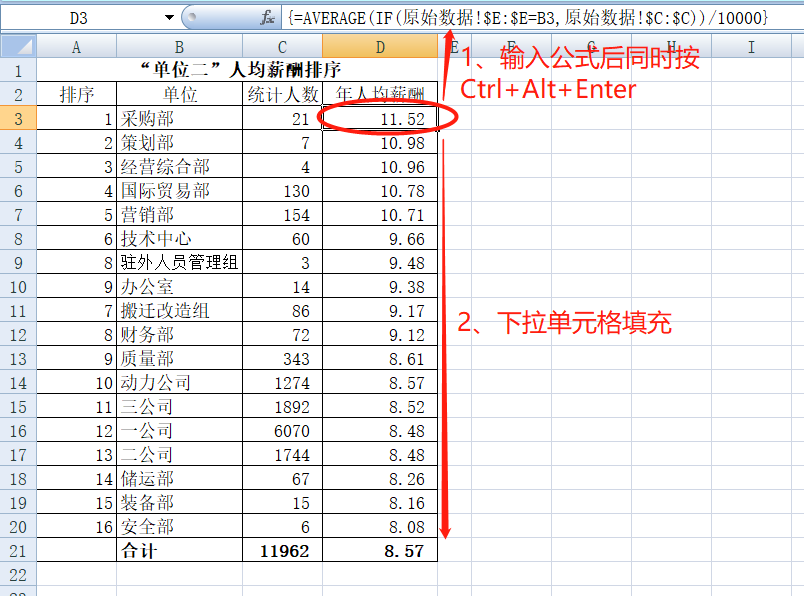
同样,D列我们使用AVERAGE+IF 来直接得出相关部门的年人均薪酬。D3单元格输入公式“=AVERAGE(IF(原始数据!$E:$E=B3,原始数据!$C:$C))/10000”,表示提取“原始数据E列”中和B3单元格相等的数据,返回“原始数据C列”同行号数据,再求平均值并转换为万元单元,数组三键结束,下拉单元格填充公式,并选中A2:D20区域,以D列“年人均薪酬”降序排序,得到最终结果:
(三)对所有单位员工年应发薪酬进行“前10名后10名”排序
我们回看任务表样:
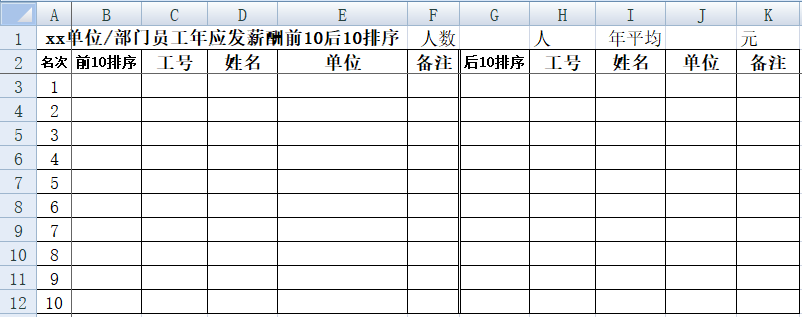
对于此项工作任务,我的思路是首先把各单位/部门的年应发薪酬从高到底进行排序,取前10名填入B列,再以此为条件去自动检索相对应的工号、姓名、单位等信息。要注意的是,碰到并列数据,取第一个作为目标取数。所以我们第一步需要对数据进行去重处理,在这里我们使用IF+FREQUENCY数组公式来对数据进行去重。
语法结构:IF(FREQUENCY(data_array,bins_array),data_array),FREQUENCY表示将data_array中的数值以bins_array为间隔进行分组,计算数值在各个区域出现的频率。FREQUENCY函数只对data_array中首次出现的数字返回其统计频率,其后重复出现的数字返回的统计频率都为0。之后再利用if函数对出现次数大于0的返回区域中对应单元格里的数值。
完成数据去重以后,要取该组数据的第k个最大值,最方便的是Large函数。语法结构:Large(Array,k),表示在Array区域中从大到小排列的第k个数值。在这里不能简单设为数字“1、2、3……” ,因为往下拖动时这些数字并不会进行自动填充,于是需要把“1”替换成一个可自动填充的函数。这里我们又使用到“ROW(A1)”,表示返回A1单元格的行号,即返回“1”,向下拖动会自动变“ROW(A1)、ROW(A2)、ROW(A3)……”,返回结果“1、2、3……”。最终得出B3单元格完整公式“=LARGE(IF(FREQUENCY(原始数据!$C$2:$C$11963,原始数据!$C$2:$C$11963),原始数据!$C$2:$C$11963),ROW(A1))”并同时按数组三键Ctrl+Shift +Enter,得到“原始数据工作表中C2到C11963数据区域排列第1的最大值”,再往下拖动单元格填充,完成了B列数据填充。需要留意的是,需要留意的是,我们把之前公式中的$X:$X替换成$X$2:$X$11963,不仅可以更精确定位数据区域,减少计算量,还可以避免返回相应行号对应的数据时出错。在此也建议在使用复杂型的公式时,尽量精确选择数据区域确保快速、精准定位到所需数据。具体如下图:
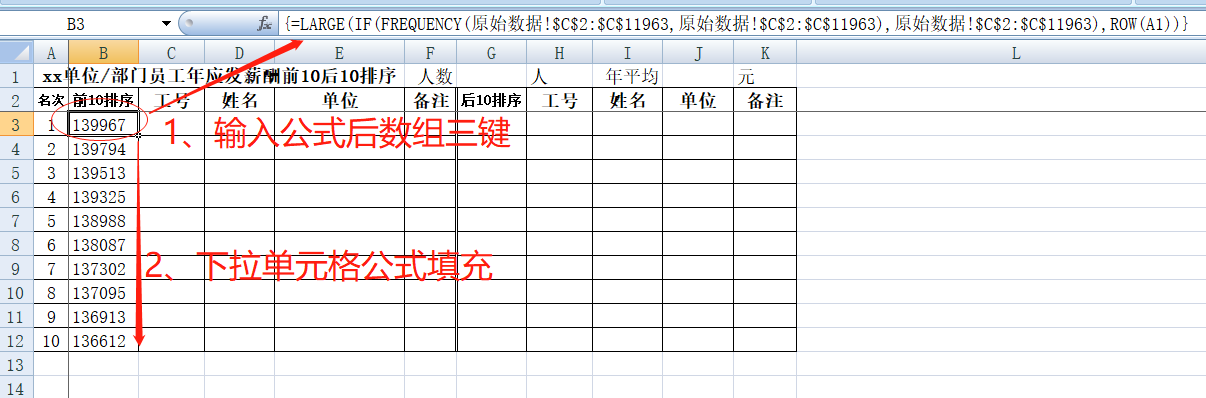
接着我们以B列为条件去填充C列。这里需要使用B列数据去“原始数据C列”中找到对等数据,再把“原始数据”表A列同行号的数据填充到C列相应位置,如果碰到相同数据,就默认自上而下取第一个数据。我们选用INDEX+MATCH来进行查询,同时添加“ROW”函数作为数据选取条件。
语法结构:
1、MATCH(查找值,查找范围,查找模式),其中查找模式有0、-1、1三种, 0为精准查找,-1位降序查找,1位升序查找,当参数为1或-1时,查找范围内的值必须是升序或降序排序,否则无法得到正确的位置。
2、INDEX(查询范围,行,列),INDEX+MATCH即利用MATCH函数提取查找值所在的行号,再用INDEX函数提取不同列的同行号数据。
完整公式:=INDEX(原始数据!$A:$A,MATCH(B3,原始数据!$C:$C,0),ROW($A$1)),公式解读:MATCH(B3,原始数据!$C:$C,0)用来查询B3单元格数据在“原始数据C列”中的行号,“0”表示精确匹配, ROW($A$1)表示当遇到并列数据时取第一个数的位置行号,INDEX提取出“原始数据A列”中同行号的数据。这个公式相当于告诉了Excel B3单元格的数据“139967”在“原始数据C列”的201位;最后INDEX函数从“原始数据A列”中提取第201位数据。公式完成后数组三键确认,即得出薪酬为139967的工号是1191446,再往下拖动单元风格填充,得到整个C列数据。
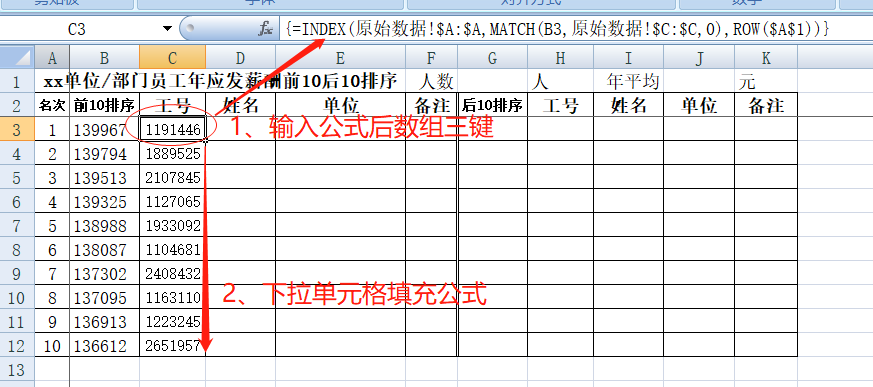
我们再以C列数据为条件,去“原始数据”表中查找到相应的D、E列数据,由于工号具有唯一性,所以D、E列直接用INDEX+MATCH公式组合简单查到,我们在D3和E3单元格分别输入公式“=INDEX(原始数据!B:B,MATCH(C3,原始数据!A:A,0))”“=INDEX(原始数据!E:E,MATCH(C3,原始数据!A:A,0))”,可直接回车确认不需要数组三键,再拖动单元格自动填充公式,得到结果如下图所示:
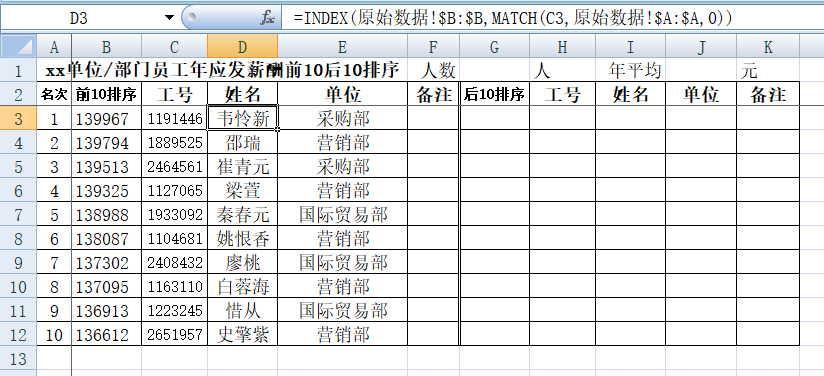
同理在填充“后10排序”的数据时,我们使用和Large相反的Small函数来取某组数据的第k个最小值,语法结构:Small(Array,k),表示在Array区域中从小到大排列的第k个数值。于是只需将B列公式中的“Large”替换成“Small”并将公式复制粘贴在G列,后面的H、I、J、K操作则和前面一样,可直接复制粘贴公式会自动变更关键单元格。
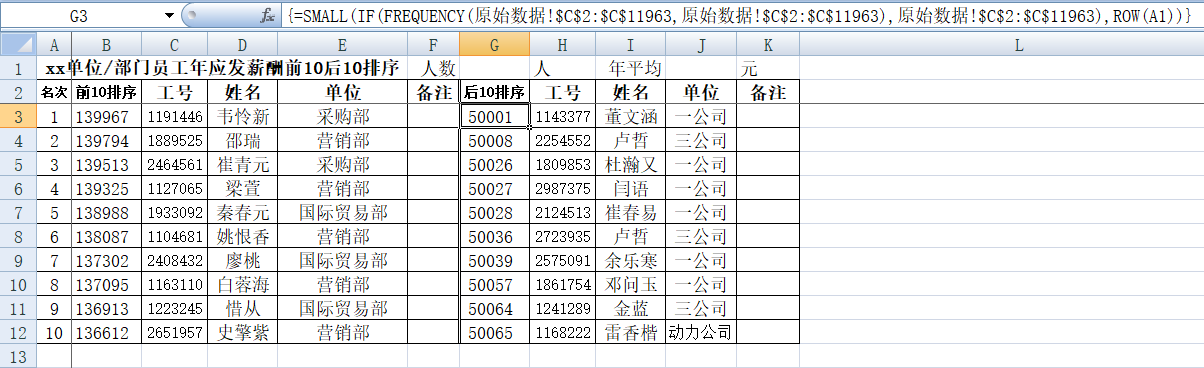
(四)对各单位/部门员工年应发薪酬进行“前10名后10名”排序
之前我们是将所有员工一起进行薪酬排序,而现在我们要分单位和部门进行员工薪酬排序,那就在上面的“前10后10”数组公式中加入一个IF条件函数,表示如果数据属于所需要分析的单位则提取,如果不是则不提取。现在我们按照“部门”分类来写公式,首先按“机关部门”分类排名,在之前FREQUENCY去重的公式中添加一个IF函数:FREQUENCY(IF(原始数据!$D$2:$D$11963="机关部门",原始数据!$C$2:$C$11963),原始数据!$C$2:$C$11963),表示如果“原始数据D2到D11963”若等于“机关部门”,则返回“原始数据表C2到C11963”相同行号的数据,并用IF+FREQUENCY进行去重,公式其它部分则和之前所有单位排序的一样,注意变更单位部门名称所在“原始数据”表中的列号。具体为:“=LARGE(IF(FREQUENCY(IF(原始数据!$D$2:$D$11963="机关部门",原始数据!$C$2:$C$11963),原始数据!$C$2:$C$11963),原始数据!$C$2:$C$11963),ROW(A1))”,完整公式解读:提取“原始数据D2到D11963”等于“机关部门”数据的行号,再对“原始数据C2到C11963”同行号的数据进行去重,最后对去重后的数据按从大到小排序。公式完成后数组三键确认,再往下拖动单元格进行格式填充,得到所有“机关部门”人员薪酬前10名不重复的数据。
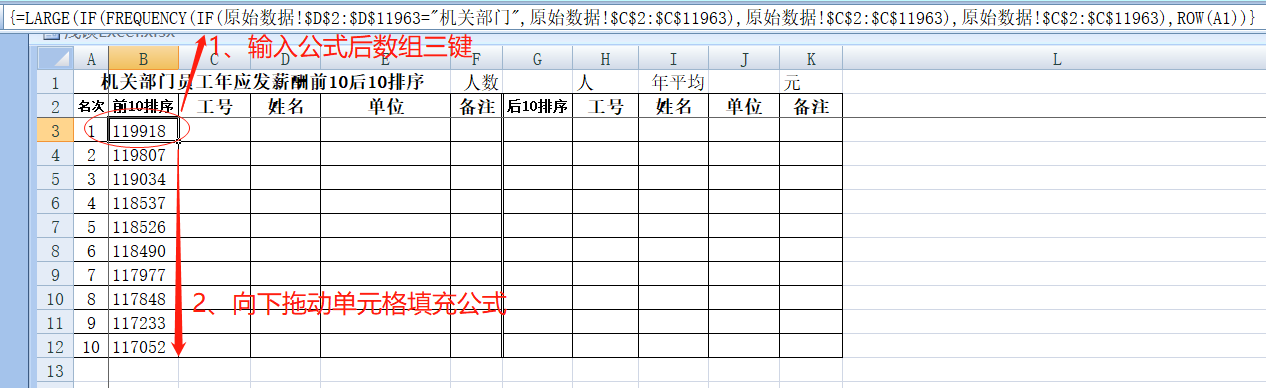
下边继续以B列数据为基础来查找相关人员的工号。和之前思路不同的地方在于,我们现在只需要在属于“机关部门”中查找匹配的工号,同理只需在之前的公式中再添加一个IF函数即可:“=INDEX(原始数据!$A$2:$A$11963,MATCH(B3,IF(原始数据!$D$2:$D$11963="机关部门",原始数据!$C$2:$C$11963),0),ROW($A$1))”,公式解析:首先在“原始数据D2到D11963”单元格中找到等于“机关部门”数据的行号,再提取“原始数据C2到C11963”相同行号的数据,该数据如果和B3单元格精确匹配,则返回“原始数据A2到A11963”相同行号的数据,最后结尾的ROW($A$1)则表示碰到重复数据值取第一个。输入公式完成后数组三键,并下拉单元格填充公式。
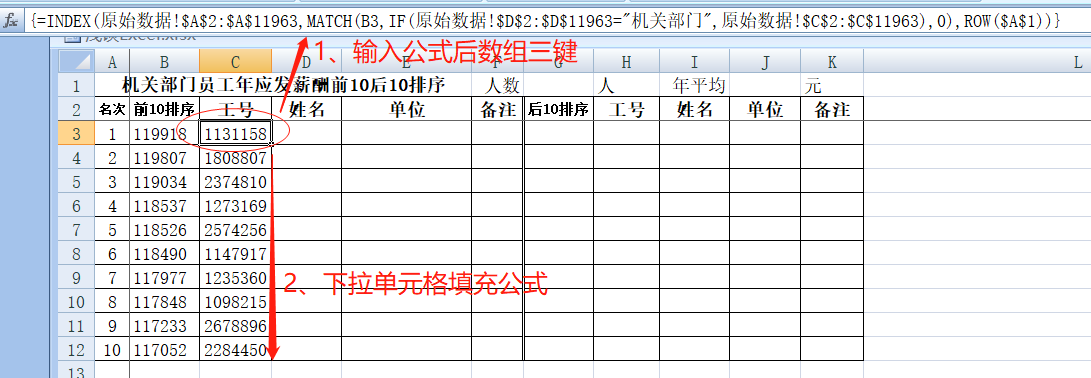
因为“工号”具有唯一性,所以“姓名”“单位”的提取公式和所有单位排序表一致,无需有任何变动。G列“后10排序”也同理将“前10排序”数组公式中的“Large”换成“Small”即可,后面的H、I、J、K操作则和前面一样。
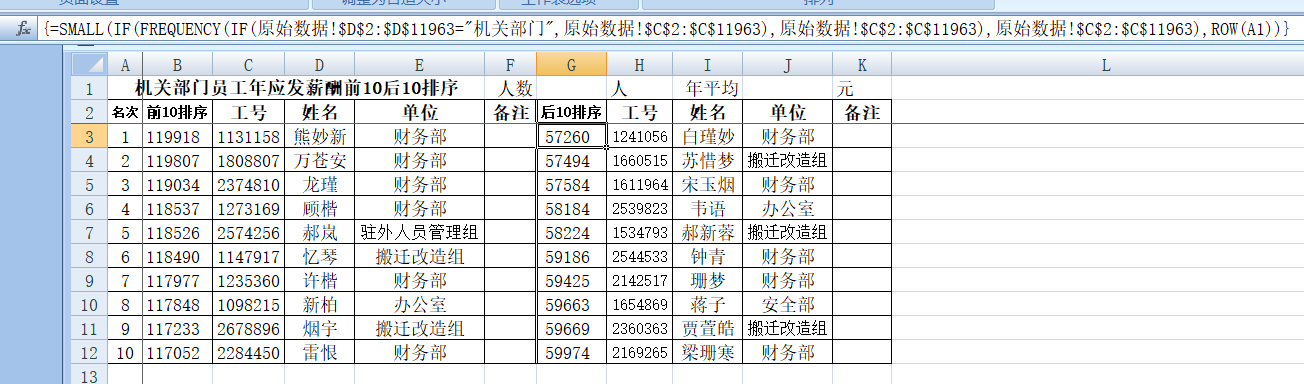
对于其它单位的排序,我们只需复制以上表格,然后替换B 、G列的单位名称,例如把上面“机关部门”替换成“生产部门”“技术部门”……等,就能得到所替换单位的薪酬排序数据。需要注意,“原始数据”表中共有三个单位类别,如果需要分析的单位名称不在同一列,那么也需要将相应的行列位置一并替换,例如需要分析“一公司”的数据,因为“一公司”单位名称位于E列,所以我们需要把上面公式中的“原始数据!$D$2:$D$11963="机关部门"”替换为“原始数据!$E$2:$E$11963="一公司"”。
至此我们已经掌握了所有单位和指定单位的排序方法,当然在设计公式阶段会花一定的精力和时间,在公式设置好之后,无论多少家单位的排序,哪怕是要排前10、前100甚至前500名,笔者之前至少花三天才能完成的共工作现在都可以在拖动数组公式后一瞬间出结果,成倍提升了工作效率,而且涉及到其它统计数据排序、一对多条件查找数据并提取等都可以使用此方法去解决。
三、结语
古人云:“工欲善其事,必先利其器。”在既定的薪酬业务统计目标和有限的工作时间内,若想不断提升工作效率,就需要我们不断去完善和探索新的工作方式。Excel具有强大的处理能力,同一种结果可以由多种方法实现,比如上面介绍的利用先去重后排序、一对多查找数据提取公式,还可以使用LARGE+IF+MATCH+ROW及INDEX+SMALL+IF+ROW等数组公式来实现,方法上相当灵活。虽然各种数组公式确实不易理解,但只要我们多做练习,将理论实践不断结合,最终我们将会对这个强大的生产工具运筹帷幄,使我们的薪酬统计工作事半功倍,增加无穷乐趣。
13

客服QQ:30444492琼网文【2021】1550-113号
增值电信业务经营许可证:琼B2-20210322
出版物经营许可证:新出发龙华出字第(2021)009号
广播电视节目制作经营许可证:(琼)字第00779号
版权所有 ©2002-2024 期刊网(www.qikanchina.com) 琼ICP备2021005105号



