江苏城乡建设职业学院 公用事业学院 江苏常州 213147
关键词:轨道交通;出入口分类;k-means聚类;PCA降维;长三角区域一体化
中图分类号: 文献识别码:A
引言
2018年11月,习近平总书记在中国国际进口博览会开幕式演讲提到“将支持长江三角洲区域一体化发展并上升为国家战略”。2019年2月,政府工作报告明确提出将长三角区域一体化战略上升为国家战略。党的十八大以来,以习近平总书记为首的党中央高度重视“区域一体化”发展战略。在顶层设计上,总书记指出 “要着力加强顶层设计”,“明确功能定位、产业分工、设施配套、综合交通体系等重大问题”。
近年来,轨道交通行业飞速发展,轨道站点逐步成为多种出行方式换乘及社会活动集聚的场所,是客流的吸引及城市发展的辐射中心,也是未来城市规划、设计与建设的研究重点。轨道交通站点周边的土地利用情况、土地开发强度不同,所以轨道交通车站在线网中的功能与定位不同。同时,每个轨道交通车站不同的出入口周边的土地利用情况不同,对客流的吸引量也会有显著差别。为了建立基于土地利用的客流预测模型,需要对各车站的出入口进行分类。本文对常州市1号线29个车站、100个出入口、14个变量的矩阵进行降维处理,得到14个综合变量的贡献度,通过PCA分析法提取出主成分,将数据降维2维,然后依据k-means聚类方法,对100个出入口进行分类,得到最终的聚类结果。
数据降维处理
1.1数据降维基本原理
数据降维是指通过线性或者非线性映射将高维数据转变成低维数据,数据降维的主要目的是在保持原始矩阵的分类和决策能力的前提下,去掉数据中的冗余信息,通过数据降维可以减轻数据中的冗余信息,通过数据降维可以减轻维数灾难和高维空间中不相关属性,促进高维数据的分类和压缩。本文采用PCA(Principal Component Analysis)主成份分析法进行数据降维的操作。
PCA是一种典型的线性降维方法,通过对原始变量的相关矩阵进行研究,用少数几个综合变量(即提取出的主成份表示原始的多个变量),进而达到降维的目的。PCA并不是直接对原始数据进行删减,而是将原始数据映射到一个新的特征空间中继续表示,即提取出来的主成份可以反映原始变量的绝大部分信息,通常用原始变量的线性组合来表示。1
假设有m个样本,每个样本有n个变量,构成一个m×n的数据矩阵:
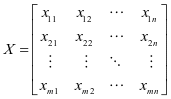
当变量个数n较大时,在n维空间中处理问题会比较繁琐,因此需要对数据进行降维处理,即用较少的综合变量来代替原始较多的变量,并且在相互独立的前提下使得这些少数综合变量尽可能多的反映原始变量的信息。
记V1, V2, …, Vn为原始变量,C1, C2, …, Ck (k≤n)为新的少数变量,则有线性变换:
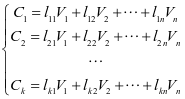
其中:
Ci与Cj(i≠j;i,j=1,2,…,k)彼此不相关;
C1是V1, V2, …, Vn所有线性组合中方差最大的,C2是与C1不相关的V1, V2, …, Vn所有线性组合中方差最大的,Ck是与C1, C2, …, Ck-1都不相关的V1, V2, …, Vn所有线性组合中方差最大的。
满足以上条件的C1, C2, …, Ck分别称为V1, V2, …, Vn的第1、第2至第k个主成份。
1.2数据降维
为了建立基于土地利用的客流预测模型,需对各车站入口进站客流进行聚类分析。常州地铁1号线29个车站、124个出入口,而本次调查涉及的交通方式有14种,即原始数据为包含124条样本、14个变量的矩阵,考虑部分交通方式之间的相关性及冗余数据需要对原始数据进行PCA降维处理,作为聚类分析的基础。
利用Matlab进行原始数据的降维操作,将包含样本协方差矩阵本征值的向量各元素总和归为100后,得到14个综合变量的贡献度,综合变量贡献度和累积贡献度如表1和图1所示。
表1 综合变量贡献度
C1 | C2 | C3 | C4 | C5 | C6 | C7 |
88.144 | 9.902 | 0.840 | 0.321 | 0.196 | 0.177 | 0.110 |
C8 | C9 | C10 | C11 | C12 | C13 | C14 |
0.091 | 0.082 | 0.052 | 0.036 | 0.026 | 0.014 | 0.007 |
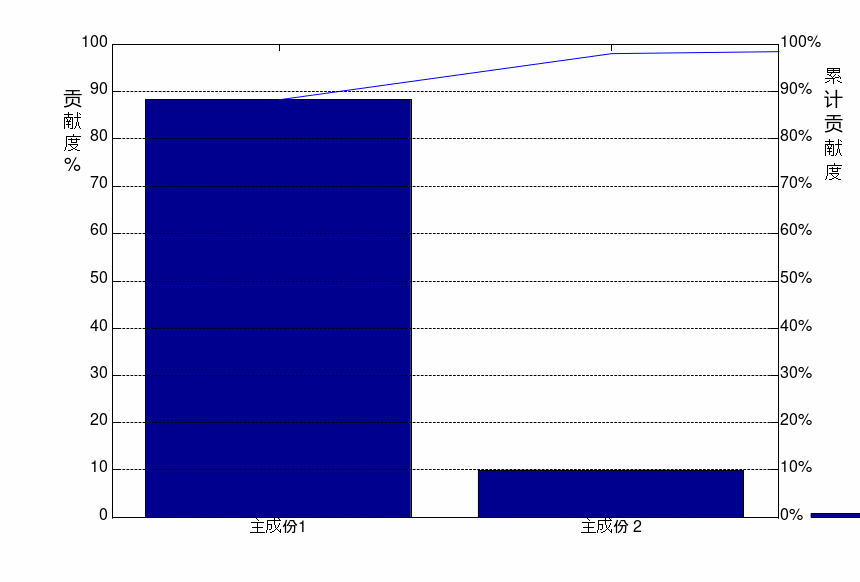
图1 PCA累计贡献率分布图
由表1和图1可知,前两个综合变量的贡献度分别为88.144%和9.902%,累积贡献度达到98.046%,大于95%,可认为综合变量1和2能够体现原始数据矩阵的特征,即通过PCA分析法提取出综合变量1和综合变量2作为主成份,将原来的14维数据降低至2维。
聚类分析
2.1聚类原理
在聚类分析中,K-均值聚类算法(k-means algorithm)是无监督分类中的一种基本方法,K-均值算法,其基本思想是通过迭代的方法,逐次更新各聚类中心的值,直至得到最好的聚类结果。K均值聚类算法的一般步骤如下:
1)初始化。输入基因表达矩阵作为对象集X,输入指定聚类类数K,并在X中随机选取K个对象作为初始聚类中心。设定迭代中止条件,比如最大循环次数或者聚类中心收敛误差容限。
2)进行迭代。采用欧式距离作为变量之间的聚类函数,根据相似度准则将数据样本分配到最接近的聚类中心,从而形成一类。初始化隶属度矩阵。
3)更新聚类中心。然后以每一类的平均向量作为新的聚类中心,重新分配数据对象。
4)反复执行第二步和第三步直至满足中止条件。
聚类算法的评价标准如下式所示:
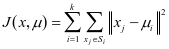
式中:
k表示聚类总数,即将样本聚为k类;
μi表示第i类的聚类中心;
Si表示第i类中包含的样本集合;
xj表示样本集合Si中第j个样本。
该公式表示将每个类中的数据与每个聚类中心做差的平方和,J越小,意味着聚类的效果越好。
2.2聚类过程
(1)样本数据分布
以降维后的数据作为聚类基础,其二维平面分布如图2所示。
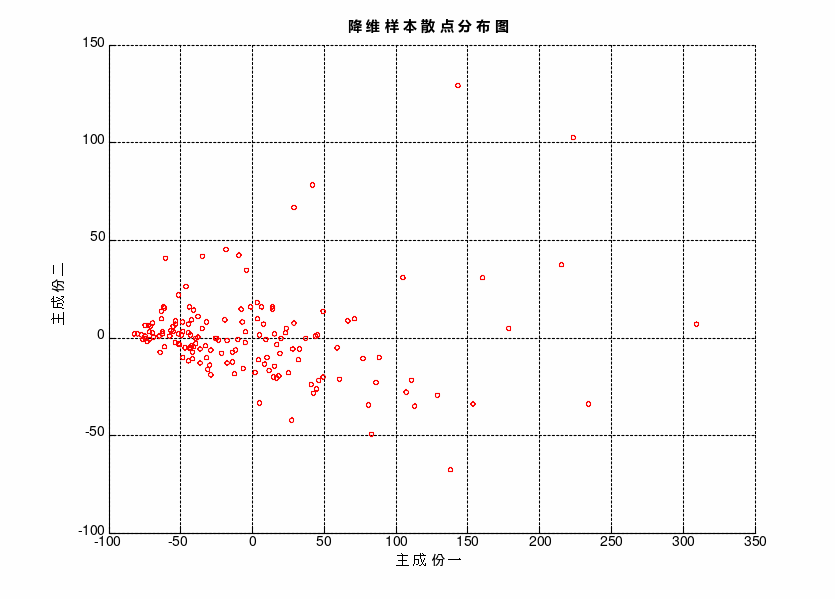
图2 样本散点分布图
从散点分布图可以看出样本数据多集中于[-100,100;-50,50]区域范围内,没有明显的聚类中心,因此在聚类时应当首先确定一个合适的聚类数。
(2)确定聚类数
利用Matlab对样本数据做聚类谱系树状图,如图3所示
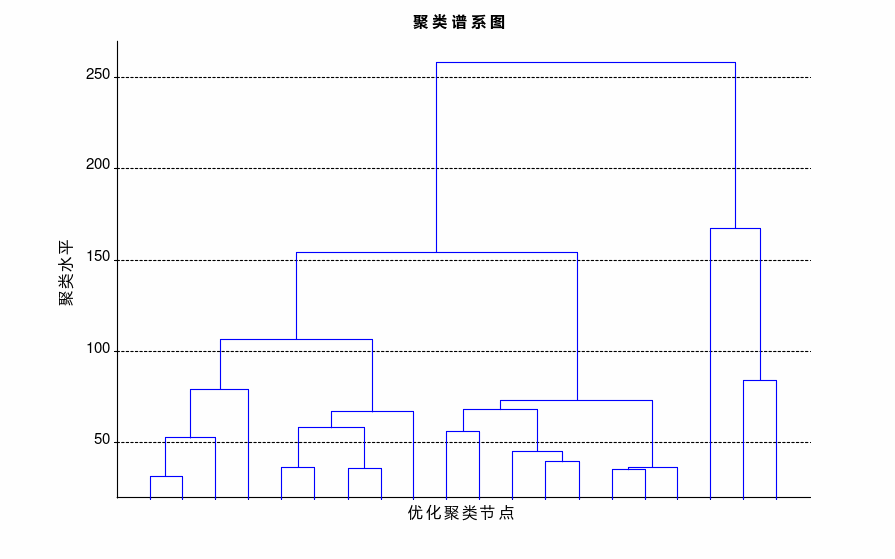
图3 聚类谱系图
从上图可以看出,为了保证聚类结果相对均衡合理,最佳聚类数量应在2~4之间,因此选取3为最佳聚类数,即使用K-均值聚类时,初始化3个聚类中心。
(3)聚类结果
使用Matlab进行聚类分析,将聚类结果显示在散点分布图中,如图4所示。
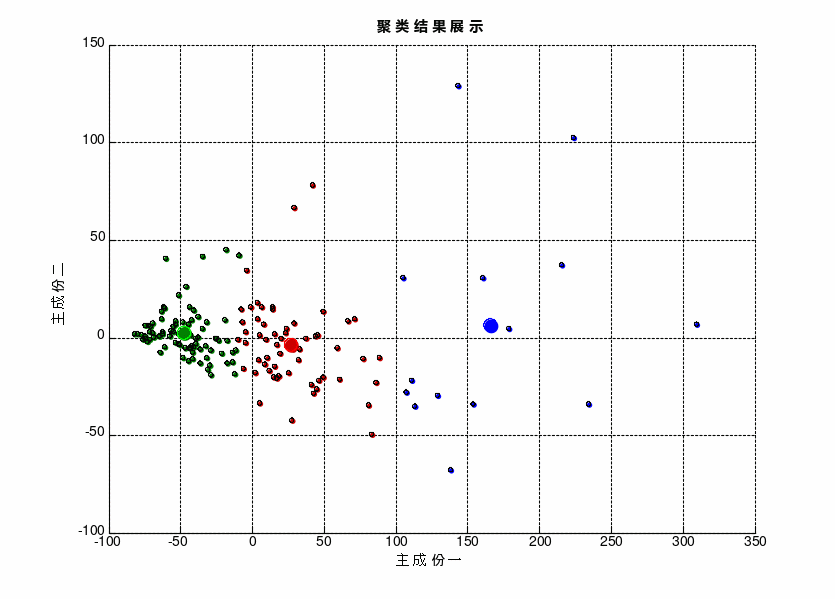
图4聚类结果分布图
表2 聚类结果统计
类别 | 样本数目 | 聚类中心 | 离差平方和 |
第1类(绿) | 84 | [-47,2] | 4.15×104 |
第2类(红) | 174 | [28,-4] | 6.67×104 |
第3类(蓝) | 28 | [166,6] | 8.73×104 |
从离差平方和的数值大小可以看出,第一类的聚类效果最好、第二类次之,第三类最差。即第一类和第二类的样本之间距离差异小、聚类特征较为明显,第三类样本之间的离散性较大、聚类特征不明显。
(4)聚类检验
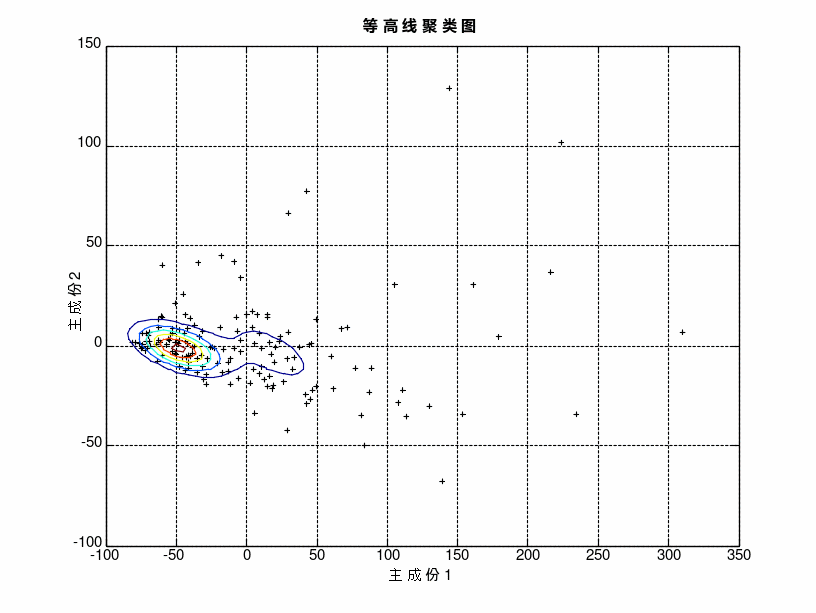
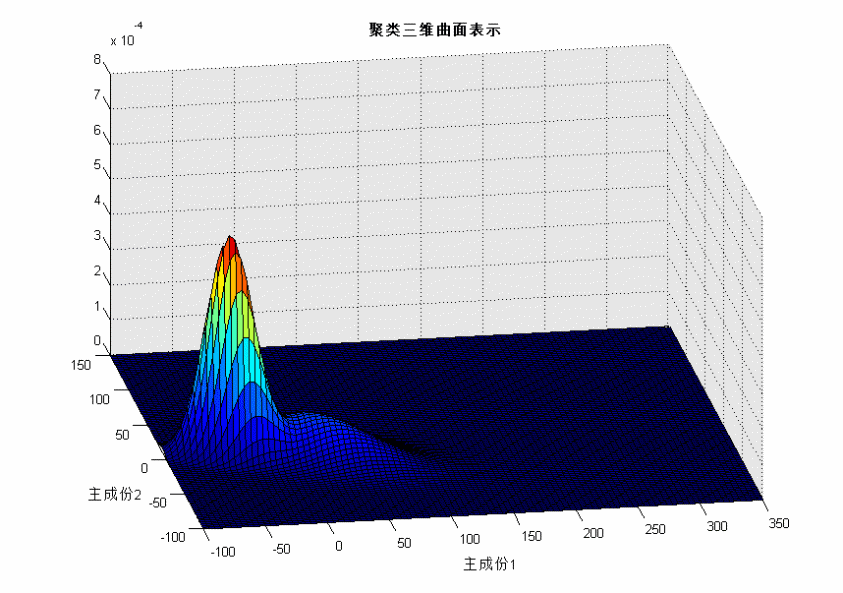
利用高斯混合模型拟合样本数据进行聚类做出样本等高线图和三维曲面图,对聚类结果进行检验,如下图所示。
|
图5 等高线聚类图 |
|
图6 高斯混合聚类三维曲面 |
根据高斯混合聚类的模拟结果,第一类和第二类的聚类特征较为显著,而第三类并不明显,原因在于第三类的样本点过于分散且样本数量较少。总体上聚类结果合理可行。
2.3结果分析
第一类包含的入口有:
森林公园站1口 | 森林公园站2口 | 森林公园站3口 | 森林公园站4口 | 新龙站1口 |
南夏墅站1A口 | 南夏墅站1B口 | 南夏墅站2A口 | 南夏墅站2B口 | 阳湖路站1A口 |
阳湖路站2口 | 武进沿江城际站1口 | 武进沿江城际站2口 | 武进沿江城际站4口 | 科教城南站1口 |
科教城北站1口 | 科教城北站2口 | 延政大道站1口 | 延政大道站2口 | 旅游学校站4口 |
新桥站3口 | 常州北站3口 | 常州北站4口 | 北郊中学站1口 | 北郊中学站3口 |
长虹路站2口 | 长虹路站3口 | 新天地公园2口 | 湖塘站4口 | 外国语学校1口 |
新区公园站4口 | 河海路站2口 | 聚湖路站1口 | 聚湖路站4口 | 聚湖路站3口 |
清凉寺站2口 | 奥体中心站4口 | 市民广场站3口 | 市民广场站4口 | 翠竹站2口 |
博爱路站2口 | 博爱路站3口 | 新龙站2口 | 清凉寺站1口 | 翠竹站3口 |
外国语学校2口 | 北郊中学站4口 | 阳湖路站1B口 | 旅游学校站5口 | 科教城南站3口 |
第二类包含的入口有:
新龙站3A口 | 新龙站3B口 | 武进沿江城际站3口 | 科教城南站2口 |
科教城北站3口 | 延政大道站5口 | 延政大道站6口 | 旅游学校站1口 |
旅游学校站3口 | 新桥站4口 | 常州北站1口 | 常州北站2口 |
北郊中学站2口 | 长虹路站1口 | 新天地公园站1口 | 湖塘站1口 |
湖塘站2口 | 外国语学校站3口 | 外国语学校站4口 | 环球港站2口 |
环球港站3口 | 新区公园站1口 | 新区公园站2口 | 河海路站4口 |
和平路站2A口 | 和平路站2B口 | 和平路站4口 | 奥体中心站1口 |
奥体中心站2口 | 市民广场站1口 | 市民广场站2口 | 同济桥站1B口 |
常州火车站3口 | 常州火车站4口 | 文化宫站11口 | 同济桥站2口 |
第三类包含的入口有:
新天地公园站3口 | 环球港站1口 | 新区公园站3口 | 聚湖路站2口 | 和平路站3口 |
常州火车站1口 | 常州火车站2口 | 文化宫站1口 | 文化宫站10口 | 同济桥站1A口 |
同济桥站4口 | 奥体中心站3口 | 和平路站9口 | 同济桥站3口 | |
3、结束语
依据居民出行调查数据,提出了采用PCA降维处理的方法,将100个样本、14个变量的矩阵降为包含两个主成分的2维数据,根据降维处理的结果,对100个出入口采用K-means聚类方法进行聚类研究,得到各出入口的聚类结果,并绘制等高新聚类图以及高斯混合聚类三维曲面图,使得结果更加形象的显示。
参考文献:
[1] 余丽洁,李岩,陈宽民. 基于谱聚类的城市轨道站点分类方法[J]. 交通信息与安全,2014,32(1):122-129
[2] 杜靖毅,张梦启,贺翔. 基于模糊聚类的城市轨道站点衔接策略研究[J]. 长沙大学学报,2014,28(2):62-65
[3] 贺鑫,李科. 基于聚类分析法的城市轨道交通站点分类[J]. 信息通信,2015,151(7):36-37
作者简介:艾倩楠,女,助教,硕士,从事轨道交通安全方面的研究.
基金项目:江苏省高校哲学社会科学研究课题2019SJA1199;常州市社会科学研究重点项目CZSKL-2019A025.

客服QQ:30444492琼网文【2021】1550-113号
增值电信业务经营许可证:琼B2-20210322
出版物经营许可证:新出发龙华出字第(2021)009号
广播电视节目制作经营许可证:(琼)字第00779号
版权所有 ©2002-2024 期刊网(www.qikanchina.com) 琼ICP备2021005105号