身份证号: 11010319960722****
摘要:随着统计学习方法的发展,越来越多的机器学习算法被逐渐广泛应用到各个学科和领域。本文聚焦于分类问题,通过对葡萄牙城市批发商客户的信息的研究,将所有客户分别按照食品购买渠道和城市地区的分布进行群体的划分,并建立感知机模型算法进行预测研究。从结果中发现批发商客户按照食品渠道进行分类,感知机的预测将更加准确,之后,我们又对数据进行主成分分析,达到对其降维的目的,之后对降维后的数据进行了建模。结果表明,将主成分分析与机器学习算法相结合,能够得到更好的分类预测效果。
关键词:客户分类、感知机算法、主成分分析、逻辑回归、模型预测
一、引言
本文涉及机器学习、多元统计分析中的多种方法,来对已有数据集建模并进行分类预测分析。感知机是机器学习领域非常简单、经典的算法,它曾被广泛应用于各类线性分类问题,其思想理论和方法是机器学习领域中很多算法的基础,如支持向量机和神经网络。而主成分分析是一种对数据进行降维的方式,相比于线性判别分析的有监督学习分类,它能够进行无监督降维,并在某些情况下在图像处理上往往能够得到比线性判别分析更好的结果。在分类问题中,将主成分分析与其他模型相结合,在通常情况下能够有更好的效果。
理论简介
(1)感知机
感知机是一种二分类的线性分类模型,它的输入是实例的特征向量,输出为实例的类别。定义样本集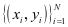 、
、 ,感知机的核心思想是错误驱动,旨在使
,感知机的核心思想是错误驱动,旨在使 中的样本数尽量少,求出将训练数据进行线性划分的分离超平面,导入基于错误分类的损失函数,并利用梯度下降的方法来最小化损失函数,从而求得模型。
中的样本数尽量少,求出将训练数据进行线性划分的分离超平面,导入基于错误分类的损失函数,并利用梯度下降的方法来最小化损失函数,从而求得模型。
(2)主成分分析
主成分分析是利用降维的思想,在损失很少信息的前提下,把多个指标转化为几个综合指标的多元统计方法。通常把转化生成的综合指标成为主成分,其中每个主成分都是原始变量的线性组合,且各个主成分之间互不相关,使得主成分比原始变量具有某些更优越的性能。
葡萄牙批发商客户信息的实证分析——基于感知机算法与主成分分析
数据来源于UCI机器学习数据库,它统计了葡萄牙440个批发经销商的客户对于不同类型食品的需求量以及客户来源的信息。批发经销商客户来自里斯本、波尔图等地,客户渠道分酒店、餐厅、咖啡馆或零售渠道。在后文中所有的模型构建、数据预测等分析全部都基于Python3实现。
对于客户群体的类别,有两种划分规则——既可按照城市区域分布来进行划分,也可以按照客户购买食品渠道来进行划分,通过不同的模型和算法的比较,我们可以看出那种分类的规则可以更好地将客户群体进行划分,从而更加清晰地描述客户信息数据的特征,并根据客户对于不同类别食品的需求来预测客户所属类别。
(1)感知机算法
考虑对来及不同地域的批发商客户数据按照购买渠道进行分类。
首先将原始客户信息数据随机分为30%的测试数据(共132个样本)以及70%的训练数据(共308个样本)。其次,对感知器模型参数进行初步设定(记为模型P1):设定最大迭代次数为40次,防止感知机算法不收敛(数据非线性可分的情况下);在极小化损失函数的过程中,设定步长即学习率为0.1;最后我们设定一个随机数种子来确保每次得到的结果一致。
最后经过感知机算法预测,在处理测试集132个样本时,出现了15次错误,可得在测试集上,分类器的分类错误率大约为11%,易知分类器的预测准确度为89%。也就是说,对于来自葡萄牙不同城市或地区的批发商客户来说,选取其在六类不同食品上的支出为特征,通过感知机算法将客户按照其购买食品渠道进行分类,我们预测每个顾客的购买渠道的准确率为89%。
接着考虑对购买渠道不同的批发商的客户按照城市或地区来源进行分类。同样的,首先对数据集进行相同的预处理。
感知机模型参数与上一个模型一致,利用python进行模型的构建并在测试集上检验模型预测精度。此次模型记为P2。迭代计算后,模型P2表现较P1而言在预测精度上有明显下降。在132个测试数据样本中,有47个样本被分类错误,分类器错误率36%,模型预测精度也仅有64%。对于客户的不同特征,购买渠道与城市地区分布两个属性在同一线性分类模型上的表现差异较大。
(2)将感知机算法与主成分分析结合
接下来我们对数据做主成分分析。根据感知机的分类结果,将城市也作为客户的特征之一。
在做主成分分析之前,首先对数据集进行标准化,这是因为一些特征没有经过标准化的话将自然会有更高的方差。标准化处理后拟合模型,并将我们的特征转换为主成分,即原始变量的线性组合。随后构建协方差矩阵,并根据协方差矩阵求的特征值及特征向量。特征值代表特征向量的大小,将其按照大小进行排序,找出前k个最重要的特征向量。
根据主成分分析结果,我们可以得到累计方差与独立解释方差,第一主成分的独立解释方差占总方差的40%左右,第二个主成分的独立解释方差占总方差的20%,前两个主成分已经几乎解释了数据集中60%的方差。
通过将批发商客户数据投影到二维平面上可看出不同购买渠道的客户可以通过线性分类器进行很好地分类,这里我们将继续采用感知机算法(记为模型P3),然后将两个主成分作为输入特征进行预测,模型P3的预测精度可以达到93%。
总结
通过对数据进行多角度建模,我们可以看出,相较于单纯地感知机模型,先利用主成分分析对数据进行降维后,在利用模型进行分类能够产生够好的效果,或者说能够在客户信息数据集上对客户进行更好的分类、对客户购买渠道能够进行更好的预测。
另外,相较于批发商客户的城市地区分布而言,客户的购买渠道这一特征将更加具有代表性,更能清晰地将客户按照固定群体进行划分与预测,正如上一章所讲,这可能是由于原始数据中各城市地区样本比例的系统性原因造成的,应对城市地区进行更细致的划分,将其当做客户的特征、或者说将其当做数据的新的一个维度可能会使预测有更好的结果。
参考文献
Ofer Dekel and Shai Shalev-Shwartz and Yoram Singer. The Forgetron: A Kernel-Based Perceptron on a Budget[J]. SIAM Journal on Computing, 2008, 37(5) : 1342-1372.
Nicolò Cesa Bianchi and Alex Conconi and Claudio Gentile. A Second-Order Perceptron Algorithm[J]. SIAM Journal on Computing, 2006, 34(3) : 640-668.
Cyril Voyant et al. Multi-layer Perceptron and Pruning[J]. Turkish Journal of Forecasting, 2017, : 1-6.
[4]Shovasis Kumar Biswas and Mohammad Mahmudul Alam Mia. Image Reconstruction Using Multi Layer Perceptron MLP And Support Vector Machine SVM Classifier And Study Of Classification Accuracy[J]. International Journal of Scientific & Technology Research, 2014, 4(2) : 226-231.
[5]陈佩. 主成分分析法研究及其在特征提取中的应用[D].陕西师范大学,2014.
[6]吴疆,尤飞,蒋平.基于回归分析和主成分分析的噪声方差估计方法[J].电子与信息学报,2018,40(05):1195-1201.

客服QQ:30444492琼网文【2021】1550-113号
增值电信业务经营许可证:琼B2-20210322
出版物经营许可证:新出发龙华出字第(2021)009号
广播电视节目制作经营许可证:(琼)字第00779号
版权所有 ©2002-2024 期刊网(www.qikanchina.com) 琼ICP备2021005105号



