1. 天津先进技术研究院 2. 天津财经大学
摘要:本文首先基于用同一个模板产生的动态网页其内容往往是属于同一个主题的且其URL是非常相似的这个规律,提出了一个在Linux系统上实现的Focused Crawler Knowledge Graph(聚焦爬虫知识图谱),再根据基于URL规则的聚焦爬虫(URL Rule Based Focused Crawl,简称UBFC)的算法,即从严格限定主题相关网页范围、排除关键字、域名范围限定出发产生的BNF表达式,并用这些正则表达式来指导聚焦爬虫的抓取的理论,对此爬虫进行改进,使其在领域类收获率、召回率上获得较大改进。
关键词:聚焦爬虫;URL正则表达式学习;知识图谱
1. Focused Crawler Knowledge Graph的系统架构
1.1系统概述
本系统是架设于Linux系列平台之上的基于Perl脚本语言的系统[5],具有免费、开源、灵活的特点,特别是对于聚焦搜索规则具有极高的可配置型,该系统旨在为中等规模的数据库(1000,000条记录左右)提供一套便捷、有效的聚焦搜索方式。它的爬取速度约为200URLs/分钟(是网络情况及爬取进程速度而定),且保证其每条存储记录平均仅占大约25KB存储空间。
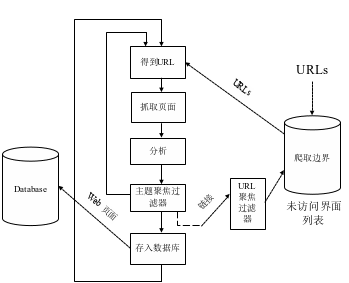
图2.1 Combine聚焦爬虫结构图
1.2系统主要特点
1可扩展的配配置能力
2为爬取模式集成主题过滤器(自动主题分类)
3在爬取模式中可使用任何主题过滤器(需以Perl插件形式提供)
4爬取限制基于URLs的通常表达式:具有包含列表与排除列表
5字符集侦测/标准化
6语言类型探测
7 HTML清理(Tidy)
8 Metadata(元数据)抽取
9网页副本探测
10将爬取页面转换为特定XML档案格式输出
11依靠插件可以支持多种文档(text,HTML,PDF,MS Word,MS Excel,MS PowerPoint,各种图片……)
12利用MySQL数据库存储数据,并可对其进行一定程度的管理
1.3网页爬虫的体系结构
该系统为了能够进行不间断爬取进行了专门设计。爬取收获进程(harvester)将分为多步对一个URL进行处理。在开始时要先为系统输入“种子”(seed)URL序列,所有爬取的URL链接将在出存入数据库之前被标准化。数据可以通过自定义的ALVIS XML文档格式进行输出。
1从URL列表中取出下一个URL
2爬取器依照REP(Robot Exclusion Protocol),爬取规则进行本地缓存
3通过GET, GET-IF-MODIFIED或HEAD HTTP请求获取页面
4将获取的HTML代码进行清理与标准化
5获取页面采用的字符集,并且将其标准化为UTF-8字符集
6(a)通过其他插件协助将text,HTML,PDF,MSWord,MSExcel,MSPowerPoint等格式转化为HTML
6(b)内部解析器进行HTML文本解析。在这一步将取出抽出metadata(title, keywords, description…),HTML链接,以及无标记的文本等信息
6将网页文本送至主题过滤器。一旦该网页与聚焦搜索主题相关,进行以下工作
7(a)启发式的相关性评价系统
7(b)进一步分析,例如类型与语言定义
7(c)更新数据库记录
7(d)将新爬取的HTML链接与提取出的URL放入URL列表
1.4 URL选择标准
为了成功的爬取所需的页面(即进行聚焦爬取)
1 URL需要依照列表算法进行选择
2 选择的URL需通过allow标记筛选
3 选择的URL不能处于exlcude列表中
4 REP协议允许爬取该URL
5 该地址所指向页面需要通过主题过滤器的筛选。
2、页面解析与分析
每个爬取的页面都会被爬虫自动进行解析和分析后,以标准的存储记录格式存储与内部的MySQL数据库中。
存储记录结构包括以下几个字段:
●Title:即页面文档标题
●Headings:HTML头
●Metadata:HTML元数据
●Plain text:纯TXT文本
●Original document:原始文档
●Links:HTML和纯文本的URLs
●Anchor:锚文本
●Mime-Type:多用途的网际邮件扩充协议类型
●Dates:数据变更, 过期数据, 将由Web Crawler做最后确认
●Web-server:辨认Web服务器类型
该系统中想要支持一种新格式的网络文档格式其实很简单,只要能够找到将该文档格式转化为HTML或纯文本格式的第三方Perl插件即可。
2.1 URL过滤机制
在URL被存入列表以前(无论是通过人工的载入还是自动爬取)都会进行标准化和有效性验证,这个过程包括以下几方面工作:
2.1.1标准化
1 名称标准化:服务器名缩略处理,端口号的替换,URL合理化
2 删除无用信息(例如IE中的’#’及其以后的信息)
3 清理CGI(Common Gateway Interface)中无关参量 清理路径中的‘.’符号(如‘./’,‘./’)
4 删除在会话中无用的CGI参量,这类参量通过配置项界定
5 标准化Web-server的名称。这种标准化过程将通过统一服务器别名的方式实现,识别模式会通过配置项界定这类识别模式会在使用系统管理例程(combineUtil)时自动生成并用来分析爬取的资料集。
2.2.2验证
1、获取的URL长度验证 其长度必须小于配置项中变量 maxUrlLength的值。
2、通过列表验证: URL必须符合配置项中 列表中的要求,列表中的规则以Perl 正则表达式描述。
3、排除列表验证:URL必须不满足配置项中 列表中的要求,列表中的规则以Perl 正则表达式描述。
2.3爬取策略
Focus Crawler被设计为可以不间断进行爬取,因此可以保证爬取的数据尽可能的做到随页面而更新。爬虫的启动与挂起都可以进行人工的管理。配置项中的 AutoRecycleLinks 用来决定爬虫是可以自行搜索已验证的新外链,还是只能爬取那些已经被标记过的链接。
2.3.1 URL标记机制
所有页面中的相关外链将被抽取,进行标准化后以结构记录的形式存储与数据库中。其中,通过选择、验证标准筛选后的链接将被标记,以供进一步爬取相关页面。
被标记的URL地址需满足:
1 被标记的URL必须源自主题相关的页面(即能够通过聚焦过滤器过率)
2 被标记的URL必须符合HTTP,HTTPS或FTP三种协议之一
3 被标记的URL不允许超出最大长度限制(默认为250个字符,可配置)
4 被标记的URL必须用过通过性列表测试(规则可配置)
5 被标记的URL必须通过排除性列表测试——可配置
2.3.2 爬取队列管理机制
在一次爬取计划中,每一个从主机获取的有效URL地址将构成一个就绪队列,它将为下一次的爬取提供新的地址列表。
每个从就绪队列中选出的URL地址必须满足:
1 被选出的URL必须首先是被标记的
2 该URL不能是锁定的——每个成功访问URL的爬虫将对其设定一个锁定时限,该时限可通过 WaitIntervalHarvesterSuccess参量进行设定
3 该URL所指向主机不能出于锁定状态——每个成功访问主机的爬虫将对其设定一个锁,该锁可通过 WaitIntervalHost参量进行设定
这一机制避免多个爬虫相互干扰冲突,造成脏数据情况。
3.内建主题过滤器——自动主题分类机制
一种简单的创建“种子”页面集的方式便是采用“主题定义”所用的词条作为关键字输入通用搜索引擎(Yahoo、Google…)并将其返回的结果作为种子页面导入爬虫系统中。
3.1本系统分类机制
爬虫系统的自动主题分类机制,可以在主题过滤器中决定主题的相关性。这种过滤方式是基于被爬取的页面文本,与预定义控制中的主题定义词条间的相互匹配而完成的。主题定义机制利用分级分类系统中的(与主题相符的)主题类和主题条目,组成每一个类的相关主题。一个条目可能是(一个单词、短语、或者是布尔“AND”(与)型表达式。而系统也允许采用布尔-“OR”(或)型表达式将几个不同的条目集合至同一个主题类型之下。
主题匹配所采用的算法是简单的“串对串”的方式,即将页面文档中的文本与列表中的各个条目进行匹配。每个匹配被从文档中找到后,将会获得一个“匹配分值”,这个分值是基于它所匹配的条目以及在所匹配条目在页面中的位置。匹配结束后,该页面所有的“匹配分值”将被求和得出这个页面的“相关性得分”,如果这个“相关性得分”超过了预先定义的“相关线分值”,则该页面连同包含其主题分类和条目的列表将一并存入MySQL数据库中。
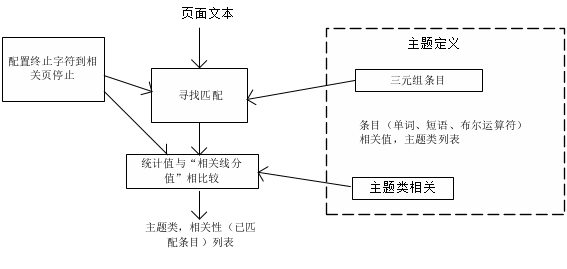 图2.3:自动主题分类算法示意图
图2.3:自动主题分类算法示意图
3.2一个基于URL规则的聚焦爬虫
基于上述事实,我们提出一个基于URL规则的聚焦爬虫的解决方案,该方案大致有二步组成:
1 实验爬虫阶段,主要是从每个主题相关站点中学习出一些URL规则。
2 聚焦爬虫阶段,该阶段利用从实验爬虫阶段学习出的URL规则来指导爬虫进行实际的网页抓取。
下面对这两步进行详细介绍。
3.2.1试验爬虫阶段
如下图所示,得到主题相关站点列表后,我们用一个爬虫从这些站点抓取页面,并用这些页面学习URL正则表达式。该爬虫采用广度优先搜索从每个主题相关站点中抓取最多N张页面,然后用一个页面分类器对这N张页面进行分类,分类之后选出与主题相关的页面的URL作为集合P,然后从P中学习出几个正则表达能基本上概括P中的URL。
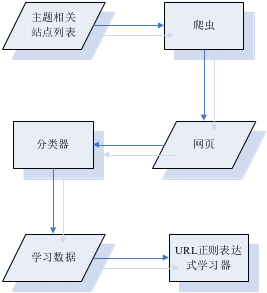
图3.1:实验爬虫阶段流程图
除了得到主题相关的网页之外,我们还从这N张网页中找出主题相关的目录页面集合D。然后用同样的方法学习出概括这些目录页面URL的正则表达式。寻找与主题相关的目录页面的算法是这样的:如果一张页面连出去的页面中有超过hl张页面是与主题相关的内容页面或者有超过h2张页面是与主题相关的目录页面,则认为它是与主题相关的目录页面。我们假定hl取5,h2取30
3.2.2聚焦爬虫阶段
从上一步我们可以得到每个网站的主题相关的目录页面和主题相关的内容页面的正则表达式,有了主题相关站点和URL正则表达式,我们就可以用他们来实现我们的聚焦爬虫。
1 判断新URL的domain是不是主题相关站点;
2 从URL正则表达式列表中寻找一条与之匹配的正例URL正则表达式;
3 从URL正则表达式列表中寻找一条与之匹配的反例URL正则表达式;
4 若P/N>h,则抓取,否则不抓取。
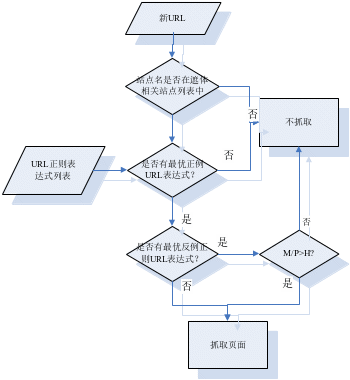
图3.2:正则表达式指导聚焦爬虫正确的抓取网页流程图
3.3系统表现
3.3.1速度表现
对于速度的评价——即系统每分钟可以处理的URL数量,很大程度上依赖于构建的环境:例如网络速度、机器存储量、选定爬取的URL页面大小、配置细节、爬虫进程的多少……但总的来说,在一个很系统资源宽裕的条件下,Combine Crawler系统可以做到每分钟处理多达200条的URL。这里的“处理”指的是包括将URL加入队列表、从网上抓取页面、页面解析、自动主题分类、再次找出新的外链,以及将结构型的记录存入关系型数据库这一系列的过程。这一过程无论对于一个小型的简单爬虫还是一个庞大、复杂,包含1000000条记录的主题相关爬虫都是适用的。
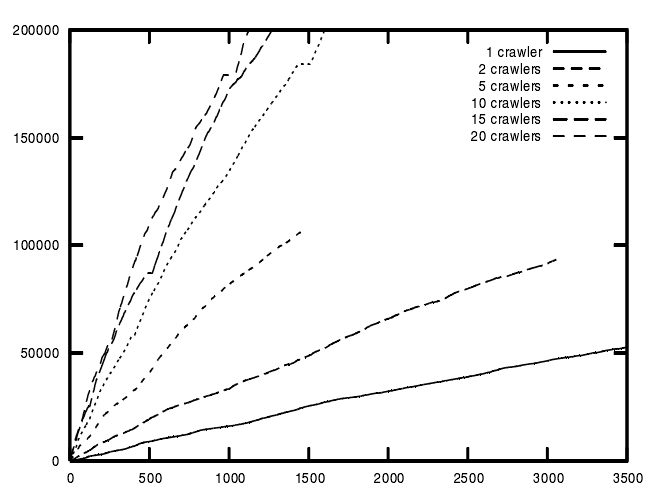
时间(以分钟计)
图3.8 聚焦爬虫效率/时间图,采用非聚焦方式及速度优先的配置[5]
3.3.2 爬虫进程效率
提升系统效率的最好办法便是在任务中采用多个爬虫进程。它可以通过使用命令 combineCtrl start 时的 –harvester 选项进行设定,例如:
combineCtrl –-jobname MyJob –harvester 5 这条命令将开启5个爬取进程一起完成“MyJob”这个任务。使用多个爬取进程对于效率的提高情况在图3.1及表3.1中皆可直观看到。
爬虫进程数 | 1 | 2 | 5 | 10 | 15 | 20 |
速度提升率 | 1 | 2 | 4.8 | 8.2 | 9.8 | 11 |
表3.1 采用多个爬虫时速度提升的比率[5]
3.3.3 空间使用效率
如果存储包含原始页面文档的结构记录将占据大量的磁盘空间,平均每条储存于MySQL中的记录将占掉大约25kB的空间,其中包括爬虫运行时产生的管理开支。由此推算,一个拥有100000条记录的数据库至少要占用2.5GB的硬盘空间。如果选择不在数据库中存储原始页面文档(saveHTML = 0)可以节省下客观的空间,这时每条记录平均只需要占用8KB左右的空间。
以ALVIS XML格式导出的文档记录平均会达到42KB,使用轻量级的XML格式每条输出记录会减少至27KB,此时100000条记录产生的输出文档将达到3、4GB大小,另外极为紧凑的DC(Dublin Core format)格式每条记录只会占用0.65KB空间。
3.3.4 爬取策略效率
本系统内建以下四种爬取策略[5]
BreadthFirst:最简单的爬取策略,它并不试探下一个要访问的URL地址,而是将边界列表当作一个FIFO(先进先出)的队列,按照URL得出对顺序爬取下一个链接。
BestFirst:基本想法是预先选出一组URL地址作为边界列表,其中根据某些评价机制筛选出的URL被爬取,而边界列表作为一个私有队列。在这种实现方式中,URL选择的过程由Combine系统在将页面的“主题相关性得分”统计后得出。
PageRank:与BestFirst方法基本一致,但是页面得分通过PageRank算法统计得出。
BreadthFirstTime:BestFirst的升级版,基本思想是不要在短期内重复访问同一台服务器,避免服务器过载。因此,某个页面只能在前一进程访问且经过一段延迟后,才能被另一进程抓取。
由下图可知,在刚开始抓取的阶段PageRank策略效率最佳,但是在后需运行过程中BreadthFirstTime(即本系统采用的策略)的效率慢慢将其赶超,尽管这个差距并不十分明显。
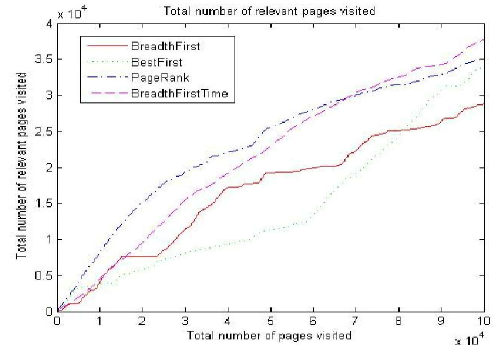
图3.10 各种策略总访问页面/相关页面比较图
4.设计工作总结及未来展望
由以上各项效率测定结果可知,本聚焦爬虫同一般的通用搜索引擎相比,在查询的准确率和效率上都有显著的提高,而且通过对“Search Engine”(搜索引擎)为关键字的聚焦搜索项目试验及对新浪的整站爬取项目试验,可知在优化后的搜索策略和配置方式下,其在收获率、召回率上获得较大改进,基本达到了本次设计的最初目的。
[1] Anders Ardo,Koraljka Golub Documentation for the Combine (focused) crawling system,March 29,2007
[2] 叶勤勇.基于URL规则的聚焦爬虫及其应用:[硕士学位论文]. 计算机与软件学院:浙江大学,2007-5-12
[3] 王晓伟.知识图谱引擎若干关键技术的研究. 计算机科学与技术学院:浙江大学,2007-5
[4] 韩吕飞.主题((topical)crawler及其应用一卞题搜索引擎:[博士学位论文].杭州:浙江大学,2005

客服QQ:30444492琼网文【2021】1550-113号
增值电信业务经营许可证:琼B2-20210322
出版物经营许可证:新出发龙华出字第(2021)009号
广播电视节目制作经营许可证:(琼)字第00779号
版权所有 ©2002-2024 期刊网 琼ICP备2021005105号



