广东美的制冷设备有限公司
摘要:本文主要研究了基于深度学习技术的设备信息提取方法。基于中文处理技术初步实现了面向特定领域的信息提取自动化构建,在构建实施中的字符与词汇表示联系学习、特定领域的中文分词、特定领域的知识实体识别、基于命名实体的全文检索方面重点开展研究,建立了电力行业的设备信息自动提取系统。
关键词:电力;非结构数据;深度学习;信息提取
在电力系统数据中,结构化数据与非结构化的数据有着不同的应用价值。结构化数据通过统计分析可以用来制定发展策略、预测动向。但实际上,与电力企业内目前用于记录、统计、控制的显性结构化数据相比,非结构数据占比高达80%,而且蕴含了更加持久和影响深远的价值。特别是因“重要的事情常常被记录”的大量文本数据,价值密度高,包含着大量可以提高企业效益的有利信息。对于电力企业来讲,通过再检索、共享分析这些数据,可以挖掘其中的隐藏价值,对电力公司的战略部署、发展方向将会产生深远影响。
结构化数据主要基于关系数据库存储,通过保存不同的业务数据到对应的表中,方便查询统计,操作便捷、易于维护。而非结构数据如设计图纸、合同、报告、说明书、标书等,这些数据文件格式多样、内容繁多、不易理解,数据含义比较隐性,无法使用关系数据库存储,只能通过不同文件形式存放。深度学习理论近年来在图片识别、人工智能等领域取得了重大突破[1]。鉴于非结构化数据的特点,对这些非结构化数据存储检索时难度会比较大。为了获得其中蕴含的价值,需要在使用这些非结构化数据时,必须根据具体需要对其进行预处理,将其标准化,建立更加智能化的系统来处理这些数据,深入挖掘其中的价值。
1.1设备信息提取的难点
在电力系统中,对非结构化数据的处理上存在以下问题:
文档中包含半结构化数据,如表格、标题等半结构字段,同时又包含非结构化文字的内容,没有预定的数据模型,无法直接提取到有用信息。
(2)可应用在电力行业中的中文分词技术不完善,目前行业中并没有适用于电力行业的专业词库,也就没有对行业中的专业词汇进行准确的切分词,直接影响信息提取结果。
(3)数据量大,干扰项多,如果是单纯的提取文档中的数据很容易,但是提取到之后要进行处理,从诸多文字和干扰项中筛选出需要的信息,是需要考虑数据的规范和清洗。
在对文本进行分析时,知识实体识别是首要任务。
建立电力行业专业词库
本文综合字符向量、词向量的优缺点,采用字符与词汇联合学习方法。如图2所示,我们首先通过学习大量无标签的文本数据来获得n-gram的高层表示,构建词向量,并输入到CNN卷积神经网络模型中。之后把CNN学习产生的特征图重新组织为序列窗口特征,输入到深度神经网络模型LSTM中,便可以从高层序列表示中学习序列相关性。
特征图中和窗口特征序列层中的相同颜色块对应同一个窗口的特征。我们用虚线连接窗口特征和其对应的特征图来源。整个模型最终的输出是LSTM的最后一个隐藏单元。
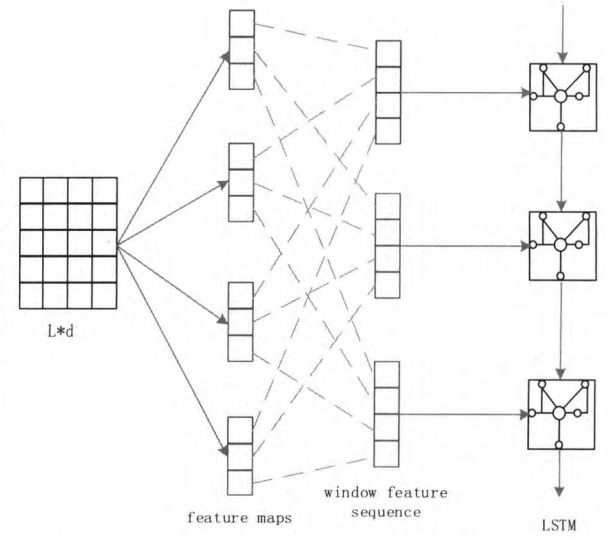
图2 C-LSTM网络结构
为了应用神经网络结构对句子进行语句建模,常用的方法是使用word2vec[2] [3],将句子转换成词嵌入序列。中文和英文语句建模方法存在差异,英文语句建模只需要使用词嵌入,但考虑到中文的单个汉字也包含重要的语义,因此我们分别训练词嵌入和字嵌入,使用词语和字作为文本序列的token。
面对电力行业的中文分词技术
针对目前主流分词工具领域适应性差的问题,本文对中文分词的自动化优化方法,其主要分为两个步骤:首先使用通用分词工具对语料进行初步分词,在初始分词基础上计算领域指标;然后使用分词自动优化算法对“散词”进行合并优化。
面向电力行业领域的知识实体识别
知识实体识别是对文本数据中能够表达知识实体的相应字串的识别和抽取。在中文自然语言处理中,知识实体识别是研究词法分析、句法分析、语义分析等领域的基础,只有做好知识实体识别的工作才能做好其他环节的工作。
知识实体识别常用的方法主要分为三种,分别为基于规则的方法、基于统计的方法以及规则和统计相结合的混合方法。
中文文本进行知识实体识别的第一步就是词法分析,改进的基于规则的分词器 ChemTok,主要从训练数据集中制定相关的规则抽取。针对传统的实体识别是依靠大量的人工特征和特定的领域知识这一问题,一种基于 BLSTM( Bidirectional Long Short-Term Memory)的神经网络结构的命名实体识别方法利用上下文的词向量和字的词向量,然后利用标注序列中标签之间的相关性对 BLSTM 的代价函数进行约束。
知识实体识别中基于统计的方法是利用一些统计方法和概率学的知识,通过对相关问题的分析来建立其对应的数学模型,然后利用已经收集的标注语料学习特征和训练模型来识别未标注语料集中的知识实体。
在自然语言处理过程中,如果单独使用统计的方法会使得状态搜索的空间变得十分庞大,因此必须借助知识规则对相关文本进行过滤修剪和处理。本文采用的就是规则和统计相结合的混合方法。
训练样本是电力行业专业词汇语料库的主要来源,包括电力国标、行标、企标,各设备说明书、手册、电力行业新闻、设备台账等,共有10万多个文件约120GB。
拟真测试样本是由互联网中收集到的各种电气设备的说明书,和制作的采购合同与设备台账组成,现共有拟真测试样本200多个,分别对应目前支持分析的三种文档类型。
电网行业内的专业词汇,尤其是涉及到设备名称的专业名词,是与我们日常用语有很大差别的,比如“接地刀闸”、“真空断路器”、“中性点电抗器”等等。行业词库的建立,很大程度的解决了未登录词的问题,让机器在读取文档时,识别出这些设备专业名词有了可能。
我们收集了行业文档,包括电力行业涉及到的行标、国标、设备说明书、手册、台账、新闻等,共10万多个文件约120G。将这些文件进行读取,识别文字内容,统一处理,整合成为一个语料库。
我们从百度输入法、搜狗输入法中获取部分电力行业的词库,经过人工筛选,得到互联网电力词库(约38000个词汇),而后将语料库进行分半句后向量化处理,训练出向量模型,并与互联网电力词库做对比,拿到词向量求余弦值>0的词汇,约35000个,作为我们的基础电力行业词库。
对基础词库做多次的训练和测试,我们对基础词库进行了二次筛选,拿到与向量模型余弦值>0.02的词汇,并对其进行人工筛选,取得约6000个词汇,作为设备类别词库。
专业词库是一个持续性的工作,在平时的训练和测试时需要随时进行人工调整。
在建立了行业词库之后,我们只是对现有的一部分已知词汇有了识别能力,在对未知词汇如何进行判断识别中,我们加入了基于行业词库的语法规则进行判断。
语法规则是由行业词库中词汇的词性组成。专业词汇是由一个或者是多个词组合而成的词语,那么它们的词性组合可以视作是一个专业词汇的语法规则。我们对行业词库进行词性处理,得到词库中所有专业词汇的词性组合以及占比。那么遇到新的未知词汇的时候,通过语法规则的筛选,机器就可以拿到符合词库语法规则的位置词汇。
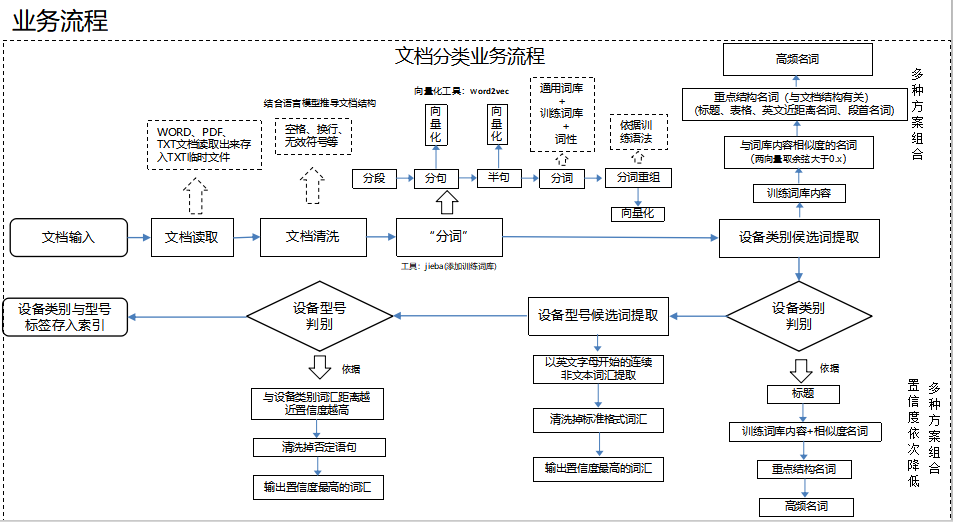
图3设备信息提取流程
步骤1:文档读取。选择要分析的设备文档将会传入后台进行读取。处理文档是需要首先转写成机器可以“看懂”的文件格式,这里后台从前端页面接收到选择分析的文档信息后,将该文档进行读取转写处理,转写为txt格式的文件,而后将txt文件路径返回。
步骤2:初步清洗,即对文件中的无效符号进行初步清洗,而后返回清洗后的clean_txt文件路径。
步骤3:分词处理。1)分半句处理。通常在文档中,设备的信息是以每半句为最小颗粒度的形式存在,为了更好的让机器“看懂”文档内容,我们对清洗后的txt文件进行分半句后保留中文处理,得到处理结果。2)分词与分词重组。引入通用词库和电力词库对半句内容进行分词,目的是得到已知词汇的分词处理结果,这个结果是不全面的,那么对于未知词汇,用词性切分词法对半句再次切分词,利用词库语法规则进行筛选,通过该规则进行分词重组,推测出可能是专业词汇的词语,最后进行停用词(非电力名词,包括日常用语等)过滤,返回最终分词结果。
步骤4:设备类别候选词提取。对“分词处理”的结果、原文档以及转写txt进行操作和处理。我们根据设备说明书实际情况出发,将设备类别可能出现的地方进行了重点提取。
步骤5:设备类别判别。在设备类别候选词提取中,我们只是提取到了可能是设备类别的词汇,这一步将提取到的类别候选词,按照提取方法的不同来确定候选词的置信度值,以置信度总值为1进行赋值,并计算出置信度值最高的类别候选词。
步骤6:设备型号提取。最后,通过对所有候选词和其置信度值的计算,得出置信度最高的类别候选词,作为该文档的设备类别。所有设备的型号,通常是以英文开始的连续非中文词汇(纯英文或英文数字组合),在这一步,我们按这个要求进行提取,拿到所有可能是型号的组合。
步骤7:设备型号判别。通过按行切分或按句切分得到英文词汇与设备类别的相对距离值,计算出英文词汇与设备类别的相对距离和的值。判断最小的相对距离和,与之对应的英文词汇判定为设备型号。若出现多个英文词汇距离和的值相等或均为最小的情况,我们判定在文档中出现最早的英文词汇为该设备的型号。
知识是人类进步的阶梯,信息提取则是计算机智能进步的阶梯,信息提取在自动问答、信息检索、数据分类等领域有着广泛的应用前景,本文基于中文处理技术初步实现了面向特定领域的信息提取自动化构建,在构建实施中的字符与词汇表示联系学习、特定领域的中文分词、特定领域的知识实体识别、基于命名实体的全文检索方面重点开展研究,但在实际研究实验和信息提取自动化的构建过程中,还需要在以下方面做进一步的深入研究与改进:
在文档文本分词阶段,针对分词结果中有可能出现的分词不准确的情况,需要进一步的优化。
在业务流程中,设备类别提取的方案还可继续增加和优化,设备类别判别时置信度值也需随之调整。
对于设备型号的提取,可进一步对标准号等干扰项进行筛选清洗,避免影响型号判别的结果。
参考文献:
[1] Ian G,Yoshua B,Aaron C. 深度学习[M]. 赵申剑,译. 北京:北京人民邮电出版社,2017.
[2] Mikolov T,Sutskever I,Chen K,et al. Distributed representations of words and phrases and their compositionality[C]/ /Advances in Neural Information Processing Systems.2013: 3111-3119.
[3]word2vec-ACV:OOV语境含义的词向量生成模型[J].计算机应用研究. 2019,36(06):1623-1628.

客服QQ:30444492琼网文【2021】1550-113号
增值电信业务经营许可证:琼B2-20210322
出版物经营许可证:新出发龙华出字第(2021)009号
广播电视节目制作经营许可证:(琼)字第00779号
版权所有 ©2002-2024 期刊网(www.qikanchina.com) 琼ICP备2021005105号



