湖南中车时代通信信号有限公司 湖南省长沙市 410000
摘要:列车运行径路反应列车实际走行路径,融合在高度抽象的LKJ2000基础数据中,无法直观体现。针对铁路运输的应用需求,采用无权有向图的底层模型,搭配图的深度优先遍历算法,运用栈的数据结构,对LKJ2000基础数据进行回溯处理,最终将列车运行径路简明厄要的展现出来。
关键词:LKJ2000,运行径路,深度优先,栈,回溯
0引言
目前LKJ2000基础数据以线性方式描述铁路网状结构,使LKJ2000基础数据高度抽象。对于多线交汇站,枢纽站等复杂场景更需要拆分站场或制作重复数据等特殊手段处理,进而使LKJ2000基础数据更加复杂繁冗。由于LKJ2000基础数据的离散性,导致基础数据中各数据段间虽走行关联但是物理位置相隔甚远。而运行径路数据又是以运行径路号串联,描述起始站到终止站之间的实际走行路径,需要将离散的基础数据进行逻辑串联。因此无法在如此复杂的LKJ2000基础数据中直接清晰展现,严重影响数据理解及数据编制效率。
1 LKJ2000基础数据与列车运行径路数据现状
LKJ2000基础数据是指纳入铁路局《列车运行图技术资料》中的线路、信号、接触网、站场等设备、设施基础线路数据,以及车站接发车经由股道、开车对标距离特殊地点、机车(动车组)担当区段等基础运行组织数据。目前全国干线铁路网共分为18个路局,各局负责编制本局局管内的LKJ2000基础数据。根据实际运营场景,每个路局都存在跨局运营的情况,各路局之间存在强相关联系。因此,各路局间的LKJ2000基础数据也需相互配合使用才可保证铁路运输正常进行。
各路局局管内LKJ2000基础数据编制完成后通过跨局交接流程向关联路局发布或接收关联路局LKJ2000基础数据。而后抽取各自所需的关联路局数据至本路局数据中,完成最终的LKJ2000基础数据的编制工作。
列车运行径路数据是指对LKJ基础数据按照列车实际运行径路理出并与列车控制条件相关联的数据排布逻辑方式,通过监控交路组织的按顺序排列对应列车运行径路的数据集合。
依照目前的LKJ2000数据架构,列车运行径路数据隐式包含在LKJ2000基础数据中,采用特定的数据类型(交路转移,支线转移)进行逻辑串联。其复杂程度由分支站或枢纽站的多少呈现阶乘级递增。目前LKJ2000运行径路数据主要由人力从LKJ2000基础数据中抽取,效率低下,错误率高。
2搜索方法研究
基于LKJ2000基础数据搜索列车运行径路数据,实质上是在铁路网中找到特定车站对之间的多种逻辑走行方式,所过的车站序列,经由车站的前后关系等。需要对全国路网进行模型构建,而后在模型上运行合理的搜索策略获取最终结果。
2.1模型构建
LKJ2000基础数据本质为线性状态描述的网状结构图。首先,可将LKJ2000基础数据抽象为图模型。其次,由于LKJ2000基础数据包含行别,运行方向等实际运行信息,可递进推定LKJ2000基础数据本身含有方向性,因此可进一步明确模型为有向图。再次,由列车运行径路决定只需明确走行的逻辑串联关系,并不需要明确站间距离,站间设备等各权重信息。最终,可明确采用无权有向图模型描述LKJ2000基础数据。经过分析LKJ2000基础数据,可构建无权有向图模型G(V,E,I),车站抽象为图中节点V,区间抽象为边E,连通关系为I。
列车运行径路数据可描述为有向图G上特定节点对之间的连通路径集合M,其为全部单条连通路径的并集。单条运行径路可描述为特定节点对之间的一条连通路径,其为节点间连通关系I的并集,整体集合关系为:
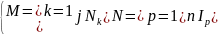
其中j为连通路径总数,n为单条路径中的关联关系总数。
2.2 算法指导与数据结构
通过模型构建,LKJ2000运行径路数据最终为集合M的结果。集合M内元素N描述的为连通路径。在有向图中获取两个特定节点之间的连通路径有深度优先遍历和广度优先遍历两种方法。由于LKJ2000运行径路走行方式由运行径路号进行串联,符合深度优先遍历规律,故而采用有向图的深度优先遍历算法。
深度优先遍历主要思想为按照某一条路径不停深入搜索,直到路径走不通或到达终点,而后回退最近一个分支节点搜索下一条分支。整体策略符合回溯法,当在搜索运行径路至数据结束或者终止站时停止搜索,并回溯至上一分支节点。
运行径路数据的搜索采用深度优先遍历算法,遇到分支节点回溯的思想进行实际操作。在算法运行过程中,需要依托栈先入后出的特性,故而数据结构选用栈。
3 搜索方案
3.1 搜索条件
列车运行径路包含起始车站,终止车站,运行径路号三个关键属性。起始车站用于定位搜索的起始位置,终止车站决定运行径路的终止位置。运行径路号决定在分支节点有多条运行径路时,实际选取的搜索分支。依照此三个搜索条件遍历LKJ2000基础数据,可获取运行径路号对应的列车运行径路。
3.2 搜索方法
在确定起始车站及终止车站后,由起始车站开始遍历LKJ2000基础数据,存储遍历的车站节点,判断分支节点是否需要遍历。如需遍历,则遍历分支直至分支结束或找到终止车站,而后回退至上一分支节点判断下一分支是否需要遍历。
搜索算法步骤如下:
步骤1:匹配搜索起始条件,定位起始车站,将起始车站压入栈中。
步骤2:向后搜索车站信息及转移信息。
步骤3:将车站信息和转移信息压入栈中,对于车站信息,跳转步骤4; 对于转移信息,定位到转移信息目标数据段,重复步骤2,步骤3。
步骤4:匹配搜索终止条件,判断是否为终止车站,如果是终止车站,输出栈中所有车站信息,一条运行径路搜索完毕,跳转步骤5。如果不是终止车站,重复步骤2,步骤3。
步骤5:将栈顶数据弹出,判断栈是否为空,如果栈为空,则全部径路搜索完毕,算法退出。如果栈不为空,继续弹出栈顶数据,直到弹出数据为转移信息,跳转步骤6。
步骤6:弹出此条转移信息,定位到此条转移信息实际位置的下一条数据记录,重复步骤2,步骤3。
流程图如图1所示:
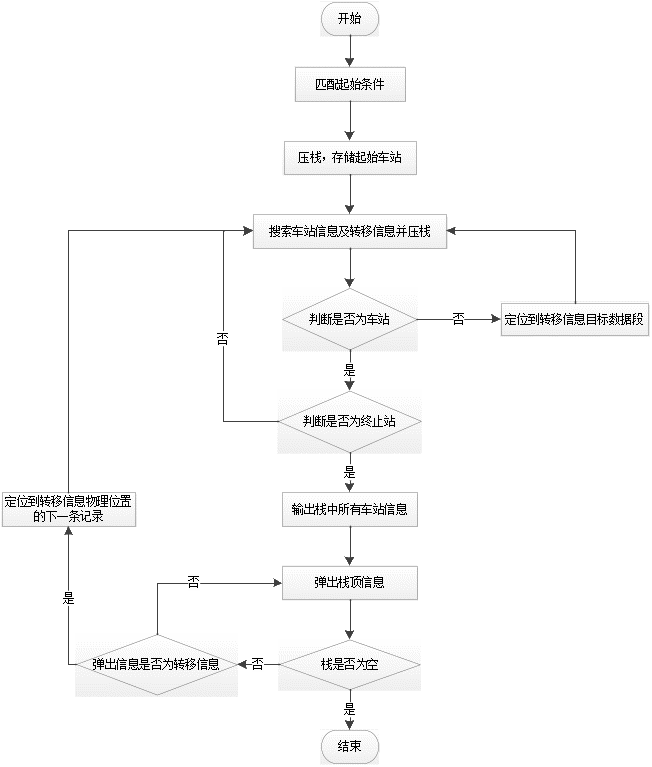
图 1
3.3 搜索方法分析
以上搜索算法从空间效率上分析,其空间复杂度为从起始站到终止站的车站序列,是一个一维的结构体数组,故其空间复杂度为O(n)。
从时间效率分析,算法运行的时间长短决定于起始车站与终止车站之间的分支节点个数。最坏结果时间复杂度为O(n!),即除起始车站和终止车站之外的全部节点都为分支。最良结果时间复杂度为o(n),即起始车站与终止车站之间没有分支节点。
4 结语
针对目前LKJ2000列车运行径路数据不明确的问题,研究LKJ2000列车运行径路数据的搜索与实现。基于LKJ2000基础数据结构进行数学建模,结合栈,采用图论的深度优先遍历策略为指导,运用回溯算法实现在网状的LKJ2000基础数据中搜索并输出列车运行径路的方法。最终以线性方式展现出列车运行径路,准确性强,效率高。
参考文献
[1] 列车运行监控装置(LKJ)运用维护规则.中国铁道出版社,2014(6):18-28.
[2] 列车运行监控装置(LKJ)数据文件编制规范(2015):1,32-33,52-54.
[3] Mark AllenWeis.数据结构与算法分析—C语言描述.机械工工业出版社,2004(1):248-249.
[4] Kenneth H.Rosen.离散数学及其应用.机械工业出版社,2011(1):82-83,89-90.

客服QQ:30444492琼网文【2021】1550-113号
增值电信业务经营许可证:琼B2-20210322
出版物经营许可证:新出发龙华出字第(2021)009号
广播电视节目制作经营许可证:(琼)字第00779号
版权所有 ©2002-2024 期刊网 琼ICP备2021005105号



