南京市江北新区沿江街道办事处 210031
摘 要 大数据分析方法为期刊评价的一种重要手段,大数据分析首要工作是批量数据的获取,使用网络爬虫工具从现有数据库中获得批量数据是一种快速、经济的方法。本研究利用中国知网已经有的数据,根据其收录数据的特点,使用python语言编写脚本文件,快速获取2016-2018年《编辑学报》文章关键词和《编辑工程与标准化》栏目的摘要,此脚本文件只要根据介绍,替换其中的期刊编号,就可以批量下载期刊内容,以方便快递、批量的获得某个期刊的特定内容,从而方便后续的分析。
关键词 大数据分析;中国知网;数据爬取
随着经济和科技的发展,我国学术期刊的数量越来越多,期刊收录的文章也越来越多,期刊之间的交叉,包含被引和施引,形成了一种很复杂的网络结构。在期刊研究和期刊评价中,需要获得期刊很多信息,包括期刊的关键词、摘要、被引用量等信息,这些信息的获得,特别是对期刊文章报道内容的获取,常规的复制、粘贴方法是无法完成的。目前大数据分析的发展为批量数据的采集和分析提供了技术的支持,在目前的企事业单位获得广泛的应用,在一些政府决策中也得到了大量的应用[1-2],数据的爬取是获取数据的快速和有效的手段。目前大数据分析手段也在期刊研究中发挥越来越重要的作用,例如吴玲使用中国知网的可视化工具研究了大数据分析在期刊策划、约稿等方面的作用[3],魏良云等使用CiteSpace软件分析了护理的研究热点和趋势[4]。从这些分析看,数据的获取有直接根据中国知网已有工具进行分析,有使用CiteSpace的使用,中国知网中集成的分析程序比较固定,只能分析固定内容,用户定制性欠缺,Citespace软件是目前期刊研究或者情报学研究使用较多的软件[8],此软件根据期刊文章之间的引用形成的作者、机构、国家、特征词、关键词、参考文献和文章的网络进行的大数据分析,依据的是社交理论探索知识点之间的相互关系,相当于人类社会的社会网络,通过知识点的相互联系聚集成一团,形成集合,此软件对研究某一领域或者某特征词(或关键词)相互联系或者演变进程是一种很好的工具,但是如果想要对某个期刊报道内容,特别是还没有形成互引关系的一些文章的内容进行研究,此软件就不能发挥很好的作用,同时此软件在操作过程中虽然可以简化一定的数据分析过程,但是并没有提供快速地批量的数据下载过程,不能批量地快速地获得某个期刊的研究特色领域。例如为了加强期刊标准化建设,《编辑学报》开设了《编辑工程和标准化》栏目,此栏目可以为编辑同仁提供最新的、全面的对编辑过程中的国家标准的解读,如何从这些特定范围批量文章中快速获取自己感兴趣的文章阅读,以及快速获取《编辑学报》近几年报道的重点内容这些信息,使用citespace是很难实现的,并且所得结果的解读也比较麻烦,为了解决以上两种问题,本人结合大数据分析方法的数据获取阶段的方法,根据中国知网收录文献的特征,编写了脚本文件,此脚本文件只要根据本文中介绍,替换感兴趣的期刊编号,就可以批量下载期刊内容,以方便快递、批量的获得某个期刊的特定内容,从而方便后续的分析。
1 项目实现目的
本项目的目的是批量、快速获取《编辑学报》2016-2018年刊发文章的关键词,并获取这3年中《编辑工程与标准化》栏目所有文章的摘要,以上两个目的分别标识为目标1和目标2。
2 项目分解和实现
根据中国知网收录期刊文章的特点,本项目针对两个目标单独进行研究。
2.1 中国知网收录文章的特点
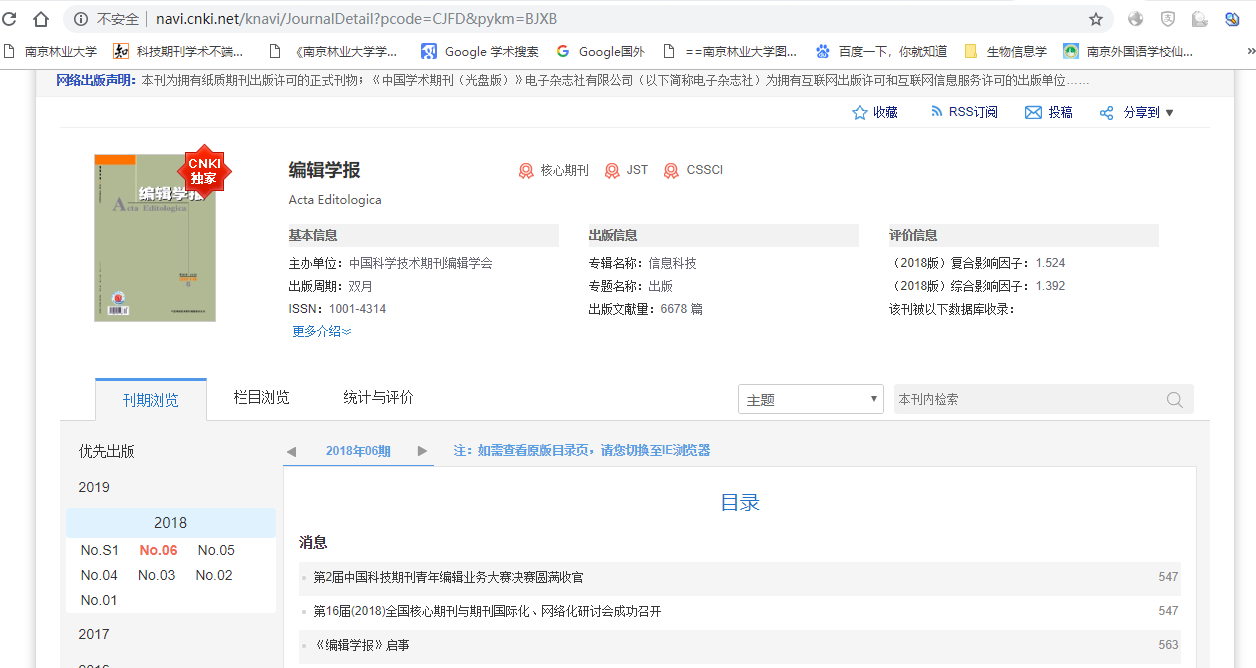
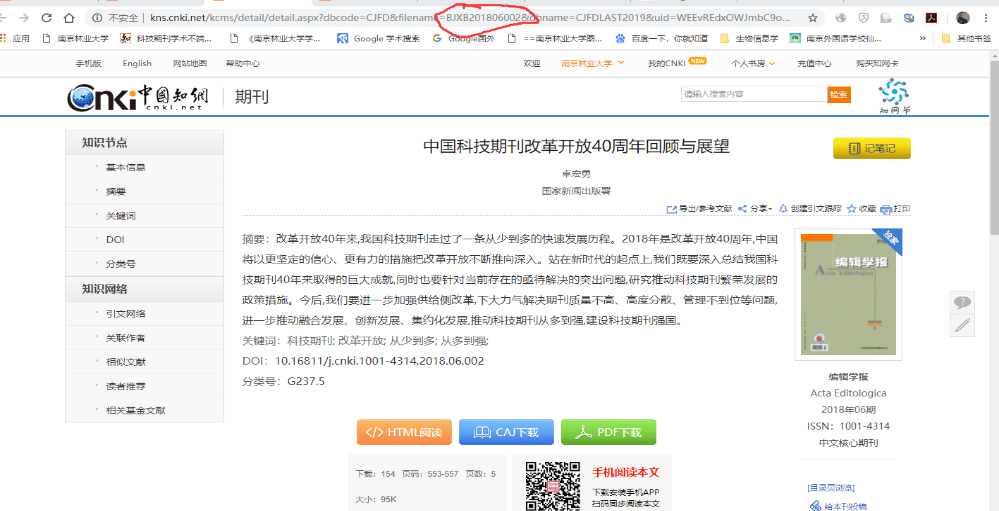
在中国知网中,每本期刊在中国知网中都有唯一编号的一个,例如在期刊导航界面,输入“编辑学报”,就可以看到《编辑学报》在中国知网中的唯一编号即为”BJXB“(如图1A),同时进入文章界面(图1B),所有的文章都有同一类型唯一的一个编号,例如《编辑学报》的2018年第6期的《中国科技期刊改革开放40周年回顾与展望》这篇文章的编号如图1B,在图1B中“BJXB201806002”既有期刊名称的编号“BJXB”,又有文章的编号“201806002“,包含了这篇文章的年月期以及文章序号等信息,所以获得每篇文章的信息,首先要获取每篇文章的这个编号。对期刊在中国知网中的展现形式分析可以发现(图1A),在《编辑学报》界面中,默认呈现为最新的一期目录信息,图1A的左边展现了《编辑学报》所有刊期的年份信息,点击任意年份,呈现为每年所刊发的期数,点击任何一期文章,在右边出现此期文章的”目录“界面,包含文章题目、栏目分类、作者和页码等信息,同时有每篇文章的超链接,连接到每篇文章信息界面,本项目正是根据这个超链接获取每篇文章在中国知网中的编号,根据编号进入文章信息界面(如图1B),在文章界面中包含了文章的题名、作者,单位、摘要、关键词、DOI号、分类号、参考文献文献等固定信息,同时还有文章的引文网络、关联作者、相似文献、读者推荐和相关基金文献等知识网络,以及“导出/参考文献”、“分享”、“创建引文跟踪”、“收藏”、“打印”等快捷操作的链接。本项目的实现正式先通过期刊界面获得每篇文章的编号,根据编号进入文章界面,从而抓起文章的关键词和摘要等信息。首先获得关键词文件。根据关键词文件获得摘要,对摘要进行分析。
A |
B 图 1 中国知网中《编辑学报》及期文章界面 |
2 结果与分析
使用以上的程序,获取了2016—2018年《编辑学报》所有文章的关键词和《编辑工程和标准化》文章的摘要,共获取关键词1 756个,摘要168段,详细信息见表1和图2,2016—2018年《编辑学报》共刊发文章969篇,其中具有关键词文章有789篇,篇均关键词数为4.05个。使用R语言的wordcloud2软件包和table函数对关键词进行词频分析,发现出现20次以上的关键词有12个,其中科技期刊出现次数最多,为258次,其他11个关键词为“学术期刊”(76次)、“编辑”(52次)、“青年编辑”(45次)、“学术不端”(27次)、“科技论文”(24次)、“医学期刊”(24次)、“新媒体”(23次)、“媒体融合”(22次)、“数字出版”(21次)、“影响力”(21次)和“编辑加工”(20次)。根据12个关键词关注的内容,12个关键词可以聚集为5类,类型1包含“科技期刊”、“学术期刊”、“科技论文”、“医学期刊”,类型2包含“编辑”(此关键词由于有动词和名词暂定为此类)、“青年编辑”,类型3包含“新媒体”、“媒体融合”、“数字出版”、“影响力”,类型4包含“编辑加工”,类型5包含“学术不端”,结果表明2016—2018年《编辑学报》对科技期刊、学术期刊、医学期刊和科技论文的报道较多,期刊的传播方式和编辑职业发展的关注度也比较高,由于本项目主要介绍获取文章要素的方式,下游的分析不是本文探讨的重点,此处只是初步分析,后续将会有更详尽的分析。
表格 1 2016-2018年《编辑学报》关键词情况
总发文量 | 含有关键词篇数 | 关键词总数量 | 非重复关键词数量 | 出现20次以上的关键词 |
969 | 789 | 3 194 | 1 756 | 科技期刊、学术期刊、编辑、青年编辑、学术不端、科技论文、医学期刊、新媒体、媒体融合、数字出版、影响力、编辑加工 |

图2 2016-2018年《编辑学报》关键词词云图(A)和《编辑工程与标准化》栏目部分文章摘要(B)
参考文献
[1]阙红艳.大数据背景下构建社会综合治税信息平台的思考——以九江市为例[J/OL].江苏经贸职业技术学院学报,2019(03):46-48[2019-06-13].http://kns.cnki.net/kcms/detail/32.1705.Z.20190612.1159.026.html.
[2]李洋.大数据分析在高速公路收费管理中的应用[J/OL].交通世界,2019(13):134-135[2019-06-13].https://doi.org/10.16248/j.cnki.11-3723/u.2019.13.065.
[3]吴玲.大数据时代基于计量可视化的精准约稿策略[J].科技与出版,2019(03):52-55.
[4]魏良云,周军.护理大数据的研究热点和趋势分析[J].护理研究,2019,33(02):256-260.
[5]杜涛,刘宁宁.基于文献计量学的体医结合研究[J].济宁医学院学报,2019,42(01):64-67.
[6]丁曼旎,曹志红,方晓阳.基于Web of Science的京津冀地区研究热点演化知识图谱分析[J].环境与可持续发展,2019,44(01):40-44.

客服QQ:30444492琼网文【2021】1550-113号
增值电信业务经营许可证:琼B2-20210322
出版物经营许可证:新出发龙华出字第(2021)009号
广播电视节目制作经营许可证:(琼)字第00779号
版权所有 ©2002-2024 期刊网(www.qikanchina.com) 琼ICP备2021005105号