柳州欧维姆机械股份有限公司 广西柳州市 545005
摘 要:PCJ(Parallel Computing in Java)是一个用于可扩展的高性能和计算以及大数据处理的Java库,该库实现了分区全局地址空间(PGAS)模型。PCJ应用程序作为一个多线程应用程序运行,线程分布在多个Java虚拟机上,每个任务都有自己的本地内存来存储和访问本地变量。选定的变量可以在任务之间共享,可以被其他任务访问、读取和修改。该库提供了执行基本操作的方法,如任务的同步化,以异步单边的方式获取和放置值。此外,PCJ还提供了创建任务组、广播和监控变量的方法。该库隐藏了节点间和节点内通信的细节,使编程变得简单而可行。PCJ库允许开发在大型资源上运行的高度可扩展(高达20万核)的应用程序,PCJ应用程序也可以运行在为数据分析设计的系统上,如Hadoop集群,在这种情况下,性能比本地应用程序要高。PCJ库完全符合Java标准,因此,程序员不需要使用额外的库。在本文中,本文介绍了PCJ库的细节,它的API和应用实例,结果显示了良好的性能和可扩展性。值得注意的是,由于PCJ库的性能和创建简单代码的能力,它很有希望在HPC和大数据应用的并行化方面取得成功。
关键词:Java编程 大数据开发 应用模式
当前和未来一代的硬件在很大程度上依赖于多处理器和多核架构来实现性能提升,这给包括编程工具和环境在内的软件开发带来了巨大压力。传统的编程模型,如MPI和OpenMP是不够的,程序员正在寻找更适合利用并行性的新解决方案。在本文中,本文介绍了PCJ(Parallel Computing in Java),这是一个在Java中进行可扩展的高性能计算和大数据处理的新型工具。PCJ是实现PGAS(分区全局地址空间)编程范式的Java库,它使计算应用以及大数据处理的开发变得简单而可行,使用PCJ库开发的应用程序可以在传统的HPC系统以及Hadoop/Spark等大数据基础设施上运行。PCJ库为用户提供了易于使用和灵活的编程工具,可以实现不同的并行化模式。只需几个编程结构,程序员就可以实现map-reduce算法,以及其他任何计算或数据密集型算法。PCJ应用程序可以在广泛的系统上运行,包括笔记本电脑和服务器,以及顶级的超级计算机。
Java的使用将HPC和大数据类型的处理结合在一起,并能在不同类型的硬件上运行。特别是,PCJ应用的高可扩展性和良好的性能已经在Cray XC40系统中得到了证明。本文介绍了在Cray XC40系统上测量的PCJ库的性能和可扩展性,这些标准基准包括乒乓、广播和随机访问。本文描述了不同特性的应用实例的并行化,包括FFT和2D模版,还介绍了标准大数据基准的结果,如字数。在所有情况下,测量的性能和可扩展性证实了PCJ是开发不同类型的并行应用的好工具。
PCJ是一个在BSD许可下开发的开放源码Java库,PCJ不需要任何语言扩展或特殊的编译器。用户只需下载一个jar文件,然后就可以在任何安装了Java的系统上开发和运行并行应用程序。程序员被提供给PCJ类,它有一套方法来实现必要的并行结构。所有的通信细节,如线程管理或网络编程,都对程序员隐藏起来。用户不需要修改问题以适应给定的编程模型,如map-reduce,而是以最佳方式实现他的算法。特别是,程序员可以轻松实现最适合他所解决的问题的数据和工作分区,PCJ库为其提供了必要的工具,包括线程编号、数据传输和线程同步。通信是单边的和异步的,这使得编程很容易,而且不易出错。图1显示了PCJ计算模型的图示以及可能的数据交换。
PCJ应用程序可以在PC、x86集群和超级计算机(包括Cray XC40系统)上运行,PCJ已经在英特尔KNL处理器以及Power8系统上进行了测试,用PCJ和Java实现的应用程序可以扩展到数十万个内核,PCJ与整个系统管理工具(包括最流行的批处理系统和执行环境)很好地集成。由于Java的可移植性,在笔记本电脑或工作站上开发和测试的PCJ应用程序可以在不做任何修改甚至不重新编译的情况下转移到超级计算机。
PCJ已经被用于特定应用程序的并行化。一个很好的例子是Graph 500测试套件中的通信密集型图形搜索。PCJ的实现具有很好的扩展性,比Hadoop的实现要好100倍。PCJ库也被用来开发进化算法的代码,该算法被用来寻找CEC'14基准套件中定义的简单函数的最小值[8],以及寻找模拟C.Elegans连接组的神经网络的参数。最近的例子包括序列排列的并行化。PCJ库允许在多个节点上轻松实现多个NCBI-BLAST实例的动态负载平衡,获得的性能比基于静态工作分配的实现至少高2倍。
使用PCJ库的应用程序是作为典型的Java应用程序使用Java虚拟机(JVM)运行的。在多节点环境中,每个节点上必须启动一个(或多个)JVM,PCJ库负责这个过程,允许用户在多个节点上开始执行,在每个节点上运行多个线程。节点和线程的数量可以很容易地配置,然而,最合理的选择是将每个节点上的线程数量限制在可用内核的数量上。通常情况下,每个物理节点上运行一个Java虚拟机,尽管PCJ允许多个JVM的情况。
典型的PCJ应用程序的启动时间与使用系统工具(如srun或aprun)启动的任何并行应用程序的启动时间相似。启动时间随着使用的节点数量的增加而增加。其可扩展性与运行简单命令(如主机名)的可扩展性相似。
由于多节点PCJ应用程序不是在单个JVM内运行,不同线程之间的通信必须以不同方式实现。如果通信线程运行在同一个JVM中,可以使用Java并发机制来同步和交换信息。如果数据交换必须在不同的JVM之间实现,则必须使用网络通信,例如套接字。
PCJ库能够处理这两种情况,向用户隐藏细节。它区分了节点间和节点内的通信,并选择了适当的数据交换机制。
PCJ库的设计是为了方便并行应用的开发,具有一套编程结构,可以实现各种类型的并行算法。用PCJ库开发的应用程序可以在任何安装了Java的系统上运行,这包括笔记本电脑、服务器、HPC和数据分析系统。PCJ已经在最新的处理器架构上进行了测试,包括英特尔KNL和Power 8,PCJ库的性能已经根据标准的微观基准进行了测试,如ping-pong、broadcast和barrier,显示出良好的可扩展性,性能可达数十万个内核。
本文介绍了在ICM的Cray XC40系统上运行的选定示例应用程序的性能结果。每个节点由2个英特尔至强E5-2690 v3 CPU组成,运行频率为2.60 GHz,内存为128 GB。节点通过Cray的Aries互连系统连接。使用了Oracle Java 1.8.0。
循环的并行化(迭代形式的工作负载)可以通过很多方式进行,通常取决于数据分布,这里本文介绍一个简单的案例,它依赖于工作分布。一个很好的例子是使用蒙特卡洛方法对π进行估计,工作以循环或分块的方式在线程之间进行分配,每个线程计算圆内的一些点,一旦完成,这些数据就会被交流和汇总。
![]()
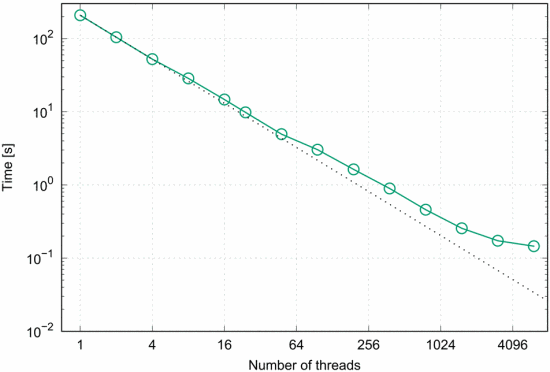
图 1 蒙特卡罗方法进行π估计结果示意图
图1展示了用蒙特卡罗方法进行π估计的性能,在正方形[0]、[1]x[0]、[1]上随机抛出的(x,y)点总数为4,800,000,000,并在线程间平均分配。该应用程序理想地扩展到48个核心(只使用一个单节点),然后考虑到节点间的通信,但它仍然线性地扩展到1536个核心,在那里数据交换时间开始主导计算,性能下降。
字数统计模块用于计算文本语料库中每个单词的出现次数,它是一个基本的技术演示器,也是一个教授map-reduce范式的工具,在Cray XC40上运行的该代码的PCJ版本的详细分析已在其他地方介绍。这里本文介绍了代码的可扩展性结果,该代码在通用集群上执行,该集群配备了英特尔E5-2697 v3,时钟频率为2.0-3.1GHz,64GB内存和Infiniband FDR+1GB以太网互连,使用NFS/lustre/ext3文件系统。测试是在弱扩展模式下进行的,每个线程读取一个10MB的文件。在这个I/O绑定的基准测试中,本文测试了两种情况:第一种情况是每个线程读取其输入文件的副本;第二种情况是所有线程只共享一个副本。为了寻找最佳性能的软件和硬件配置,每个节点执行了不同数量的PCJ线程,并测试了不同的削减策略:
① GetGlobalCountHypercube - 基于超立方体的还原。
② GetGlobalCountReduceLocalFirst-2步还原方案;第一步包括节点内还原,第二步线程0从远程计算节点收集部分结果。
③ GetGlobalCountParallelNodeO-2步还原方案,其中所有隶属于节点0的线程都进行远程还原;远程计算节点以轮流方式分配给节点0的线程;在这一步之后,进行节点0内部的还原。
在这种I/O绑定的代码中,最好的性能通常是在所有线程只共享一份输入文件的情况下实现的。总的来说,本文之前的测试已经证明,基于超立方体的还原是性能最好的,这一点在图2中也有所体现,尽管在这个系统中,本地还原的性能非常相似。
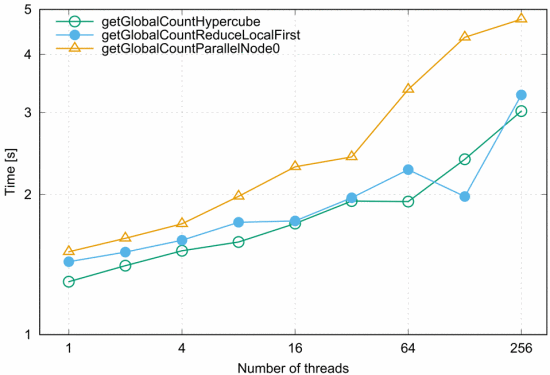
图2 每个PCJ线程从同一个文件副本中读取单词计数代码的通用集群的执行时间统计图
综上,PCJ库是高度可扩展、易于使用的工具,用于开发并行应用,包括大数据处理,PCJ特别适用于可以利用计算和通信之间的重叠的大型应用。在这种情况下,PCJ允许简单的代码开发,从而获得非常好的可扩展性和性能,与其他工具相比,PCJ的实现要容易得多,并提供更好的应用性能。它需要使用较少的库,并尽量减少使用的语言结构的数量。由此产生的代码通常更短,可读性更强,PCJ应用程序可以使用标准的Java环境进行开发和测试,不需要耗时的安装和维护Hadoop等基础设施工具。
PCJ已经被用于选定应用程序的并行化,一个很好的例子是Graph 500测试套件中的通信密集型图形搜索。PCJ的实现具有良好的扩展性,比Hadoop的实现要好100倍,PCJ库也被用来开发进化算法的代码,该算法被用来寻找一个简单函数的最小值,以及寻找模拟C. Elegans连接组的神经网络的参数。PCJ允许跨越多个节点的多个NCBI-BLAST实例的动态负载平衡,获得的性能比基于静态工作分配的实施方案至少高2倍,基于PCJ的实现可以很好地扩展到数百个节点,并允许显著减少分析时间。
[1]王茹葳.Java编程语言在大数据开发中的应用[J].电子技术,2022,51(01):160-161.
[2]张万方,李翔,王媛媛.大数据专业WEB开发技术教学研究[J].淮阴工学院学报,2021,30(06):91-96.
[3]杨海红.大数据时代计算机软件技术的开发与应用[J].电子技术与软件工程,2021(19):47-48.
[4]司利平.浅谈Java在计算机软件开发中的应用[J].电脑知识与技术,2021,17(24):81-82.
[5]王春明.计算机软件Java编程的应用[J].科技资讯,2021,19(14):24-26.收件地址:广西柳州市鱼峰区南环路6号
邓阳名收 电话:18154750909
2 / 2

客服QQ:30444492琼网文【2021】1550-113号
增值电信业务经营许可证:琼B2-20210322
出版物经营许可证:新出发龙华出字第(2021)009号
广播电视节目制作经营许可证:(琼)字第00779号
版权所有 ©2002-2024 期刊网 琼ICP备2021005105号



