江苏大学 江苏镇江 212013
摘 要:协同过滤推荐算法通过研究用户的喜好,实现从海量数据资源中为用户推荐其感兴趣的内容,在电子商务中得到了广泛的应用。然而,当此类算法应用到社交网络时,出现推荐算法效率偏低,推荐准确度下降问题,导致社交网络中用户交友推荐满意度偏低。针对这一问题,引入用户相似度概念,提出改进的协同过滤推荐算法。实验结果表明:改进算法能有效改善社交网络中的推荐准确性并提高推荐效率,全面提高用户满意度。
关键词:用户相似度;协同过滤
一、引言
随着互联网的发展,数据资源每天以几何数量级增加,为解决用户复杂的需求和庞大数据之间的矛盾,个性化推荐系统应运而生[1]。随着社交网络的兴起,个性化推荐技术也在社交网络中得到了广泛的应用。与传统的基于内容过滤的直接分析内容进行推荐不同,协同过滤分析用户的兴趣,在用户群中找出与目标用户相似的用户,综合相似用户对不同项目的评分,产生目标用户对这些项目喜好程度的预测,从而产生推荐[2]。
虽然协同过滤推荐算法在信息过滤方面呈现出了极大的优势,但随着电子商务和社交网络的快速发展和相互间的不断融合,算法在不同领域中的应用也凸显出一些问题:①冷启动问题;②稀疏性问题;③最初评价问题。社交网络包含用户的基本资料信息的同时,也包含大量用户交互、互动行为信息,如何有效利用这2类信息为用户产生推荐,也成为个性化推荐研究的一个重要议题。
针对这一问题,本文引入用户相似度概念,重新定义社交网络中相似度属性,相似度构成及其计算方法,提出一种改进的协同过滤推荐算法。
二、用户属性相似度及计算
传统的相似度有皮尔逊相关系数法、向量余弦法、调整的向量余弦法、约束的皮尔逊相关系数法、斯皮尔曼相关系数法等,在不同的应用领域中,选取不同的相似度计算方法。由于社交网络的特殊场景,本文重新定义了相似度及其计算方法。
相似度矩阵在计算时分为基于用户的相似度集合与基于商品的相似度集合。定义用户集合![]() ,商品集合
,商品集合![]() ,可用1个n×m的用户—商品评分矩阵Hmn对商品相似度进行建模,构建的用户—商品评分矩阵Hmn如下:
,可用1个n×m的用户—商品评分矩阵Hmn对商品相似度进行建模,构建的用户—商品评分矩阵Hmn如下:

式(1)中,矩阵Hmn中的n行代表n个用户,m列代表m个商品,第n行m列矩阵元素 rmn表示第n个用户对第m个商品的评分。
项亮[3]引入热门商品与该商品的几何平均值以降低热门商品与其他商品的相似度,公式如下:
![]()
式(2)中,![]() 表示评价过商品i的用户集合,
表示评价过商品i的用户集合,![]() 表示评价过商品j的用户集合,
表示评价过商品j的用户集合,![]() 表示对商品i和商品j都有过评价的用户集合。
表示对商品i和商品j都有过评价的用户集合。
推荐系统不仅要反映出用户的近期偏好,还要预测其长期偏好。许侃等提出不活跃用户对商品相似度的影响大于活跃用户[4],因此在计算时要降低活跃用户对相似度权重的影响,即增加![]() 项,公式如下:
项,公式如下:

式(3)中,N (u)表示对商品u有过行为的所有用户。
近期行为最能反映出用户的当前兴趣,因此时间相隔较短的行为才能更好地反映商品之间的相似度,故在公式(3)中加上时间衰减衰减因子,公式如下:

三、实验设计
对本文提出的算法与传统CF算法(余弦相似度)进行比较,分别在不同K值(近邻用户数)和Top N推荐长度下比较二者的精确度、召回率,并对实验结果进行分析。
3.1 实验算法实现步骤
改进商品相似度算法步骤如下:
步骤1:在训练集中构建用户—商品评分矩阵Hmn。
步骤2:根据公式(3)计算加入物品惩罚因子的商品相似度矩阵![]() ,得到最终用户当前对商品的相似度矩阵。
,得到最终用户当前对商品的相似度矩阵。
步骤3:遍历用户历史商品集合,从该集合中找出每个历史商品最相似的K个商品作为候选集。
步骤5:从候选集合中选出指定返回数为I的集合作为推荐结果。
3.2 实验准备
以电影评分作为实验对象,选取GroupLens实验室成立的MovieLens站点中的ml-1m数据集。该数据集包含6040个用户对3900部电影的评分记录,评分划分为5个等级,用1~5的整数表示。该评分数据的稀疏度为![]() 。
。
3.3 推荐指标
为评价算法性能,将MovieLens数据集拆分为训练集和测试集。利用不同 K值和TopN算法比较精确度(Precision)、召回率(Recall),在3次试验下取评价指标的平均值作为实验结果。其中,N为推荐列表中的商品总数,P为目标用户在前N项中的商品数。
其中,精确度定义:
![]()
召回率定义:
![]()
3.4 实验结果与分析
3.4.1不同近邻用户数K下算法的精确度和召回率
将改进相似度的算法称为New Item CF,传统的基于商品的CF算法称为Item CF。在 K值(近邻用户个数)不同,物品返回数为40的条件下,两种算法的精确度和召回率分别如图2、图3所示。由图2可知,New Item CF的精确度明显高于Item CF,在K=200时,New Item CF的精确度达到最大,为 0.18,比Item CF的精确度提高了9%,二者差值也达到最大。由图3可知,在相同条件下,New Item CF的召回率明显高于Item CF,在K=200 时,New Item CF的召回率达到最大,为0.17,比Item CF提高了7.2%,二者差值也达到最大。

图1相似度算法改进前后物品得分
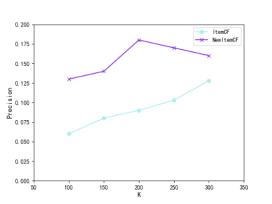
图2不同K值下推荐结果的精确度比较

图3不同K值下召回率的变化
3.4.2不同Top N算法下精确度比较
不同Top N算法下精确度比较将商品近邻数设置为40,通过设置不同推荐列表长度n测试改进算法的精确度。由图4可知,当推荐长度为5时,New Item CF算法的精确度大于 Item CF算法。然而,随着推荐长度的增加,New Item CF和Item CF的精确度均开始下 降,当Top N=10时,Item CF的精确度超过New ItemCF。因此,在使用New Item CF算法推荐商品时,推荐列表不宜过长。

图4 不同Top-N算法下的精确度
四、结束语
本文在定义用户相似度构成与计算方法基础之上,提出一种基于用户属性和用户互动信息的协同过滤推荐算法,并应用到社交网络中的智能推荐过程;本文通过一系列数据证明,在一定条件下,改进的推荐算法在精确度和召回率方面比传统CF算法明显提高。
参考文献:
[1]杨辉.基于深度学习的个性化推荐算法研究[D].北方工业大学,2021.DOI: 10.26926/d.cnki.gbfgu.2021.000022.
[2]夏立新,曾杰妍,毕崇武,等.基于LDA主题模型的用户兴趣层级演化研究[J].数据分析与知识发现, 2019, 3(07): 1-13.
[3]张亚楠,黄晶丽,王刚.考虑全局和局部信息的科研人员科研行为立体精准画像构建方法[J]. 情报学报, 2019, 38(10): 1012-1021.
[4]许侃、刘瑞鑫、林鸿飞、刘海峰、冯娇娇、李家平、林原、徐博、基于异质网络嵌入的学术论文推荐方法[J]. 山东大学学报(理学版),2020,v.55(11):39-49
作者简介:
王万扬,男,生于2000年2月,汉族,江苏大学,信息管理与信息系统方向
焦子学,女,生于1999年11月,汉族,江苏大学,信息管理与信息系统方向
【基金项目】本文系江苏大学2021年度大学生创新创业训练计划项目,项目编号:202110299877X

客服QQ:30444492琼网文【2021】1550-113号
增值电信业务经营许可证:琼B2-20210322
出版物经营许可证:新出发龙华出字第(2021)009号
广播电视节目制作经营许可证:(琼)字第00779号
版权所有 ©2002-2024 期刊网 琼ICP备2021005105号



