杭州士兰集昕微电子有限公司 浙江 杭州 310018
摘要:现代考试均是选择项目功能差异(DifferentialItem Functioning,DIF)对该问题进行检测与研究。作为判断测验公平性与评估效度的工具,DIF检测已成为全球公认的标准化考试质量分析手段。本研究运用Monte Carlo模拟对MH、LR这两种不同的DIF检测方法做出比较。
关键词:DIF检测;MH;模拟
1 两种DIF检测方法
1.1 MH方法
MH方法,其提出者为Mantel和Haenszel(1959)。1988年,Holland(1985)、Holland 等人将这种方法投入到项目功能差异的检测上来。如今,MH成为检测DIF最为普遍的工具。MH法能够对两级记分项目DIF进行侦查,将测验总分当做最终的匹配变量。MH方法统计量,是基于一张S×2×2列联表,S用于检测总分水平数。任何水平K,均能够构成两子群体在得、失分数上的2×2列联次数表(表1)。
表1 MH法S×2×2列联表

结合样本资料,制作如上S×2×2列联表,按表中数据分别计算出αMH,计算式:
αMH =(∑(f1rk·f0fk /nk)/∑(f0rk·f1fk)/nk
f1rk、f0rk代表的是在第k个能力水平组内,参照组中答对和答错的人数;f1fk、f0fk 代表了目标组回答正确、错误的具体人数。αMH取值通常为0-正无穷。当αMH=1.0,意味着该研究项目中没有DIF;当αMH<1.0,说明对目标组的难度相对偏低;当αMH>1.0,说明对参照组的难度相对偏小。考虑到αMH计算均是取自我们的样本数据,故其值是否完全为1.0,还有待做出统计检验。
1.2 LR方法
1990年,Swaminathan、Rogers两位学者提出了LR方法:令Y为分数变量,取1或是0;令Z为观察变量,代表测验总分;假设V是被试分类变量。在Logistic回归模型中,当我们给定Z、V,正确作答的概率:
P(Y=1,Z,V)= exp(β0+β1Z +β2V +β3ZV)1+exp(β0+β1Z+β2V+β3ZV)(2)
取上式两边中的对数,则:
ln( P1 - P) = β0 + β1Z + β2V + β3ZV(3)
如此,我们将Logistic回归模型成功地转变为线性回归模型。ZV项是个记号,代表观察变量实际的组合水平。运用极大似然法或是最小二乘法可以估出出回归参数β0、β1、β2以及β3。DIF检测有不一样的含义:若方程中仅仅β0、β1≠0(与0有很大区别),代表该项目中无DIF;倘若方程中β0、β1和β2均≠0,代表该项目存在一致性DIF;假设ZV项参数β3也≠0,说明项目中包括非一致性DIF。
2 实验部分
2.1 数据模拟
本研究构建了两参数Logistic模型,针对任意能力=θ的被试,在项目i上的正确概率Pi(θ):
![]()
被试能力参数θ~N(0,1),区分度ln(a)~N(0,1),其难度参数b~N(0,1),D=1.7。
2.2 DIF项目模拟设计
本研究中,测验长度设定为50个项目,属于二级记分。在目标组、参照组两个小组中,无DIF项目的参数维持恒定。也就是:不同组中能力一样的被试,在该类项目上显示的正确概率也是一样;存在一致性DIF的项目,在2个小组中表现不一样的难度系数,同样的区分度。所以,改变任何一组难度参数,困可以设置一致性DIF项目;非一致性 DIF项目,在两组中均有各自的区分度,但其难度系数一样。所以,改变任意一组区分度参数,即可设定有非一致性DIF的测试项目。
2.3 研究设计
为了得到可靠的结果,本文将300当做最小样本量,将2000当做最大样本量。在8%的项目(4个项目)有DIF时,假设3题、6题、26题和30题中均有DIF,前2个都是含一致性DIF的项目,而后2个则是含非一致性 DIF项目;在16%的项目(8个项目)有DIF时,假设3题,6题,9题,12题,26题,30题,34题和40题中都有DIF,前4个项目属于含一致性DIF,而后4个题目则属于含非一致性DIF;24%的项目(12个项目)有DIF时,假设3题,6题,9题,12题,17题,21题,26题,30题,34题,40题,43题和48题中均有DIF,前6个题目属于含一致性DIF项目,而后面6个题目则表示含非一致性DIF。可见,本实验认定为5×3×3×2混合设计,有90种不同的实验条件,每种均重复100次,共计9000次。利用R-2.15.2来完成模拟运算。因变量:I型错误率、检出率。I型错误,代表弃真错误,也就是当原假设为真(不显著)时,否认原假设。DIF分析得知,当原假设(题目并无DIF)为真时,再次否认原假设,错误地认为题目中含有DIF。检出率高,意味着该方法相对比较好,可以检测出有DIF的项目。
3 结果
3.1 I型错误率分析
表3反映了两种方法在不同条件下显示的平均I型错误率。
表3 MH、LR的平均I型错误率情况(α=0.05时)
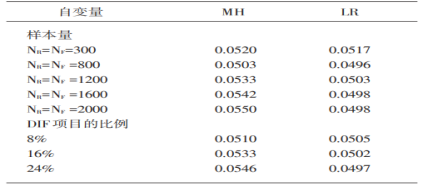
从表3得知,MH、LR的I型错误率约为0.05,可见这两种方法相对来说都是较好的。当样本量逐步地增加后(从0.052到0.0550)MH的I型错误率也会随之增高;有DIF的项目同样也会出现小幅度增加(0.0510加大至0.0546)。在任何情形下,LR的I型错误率相对比较平稳,介于0.049~0.051。这就说明,MH方法在I型错误率上的变化幅度明显要大于LR(MH:0.0510~0.0550;LR:0.0497~0.0517)。除上述外,MH的I型错误率相比LR也要更高,当样本量=2000或是DIF项目=24%时,这2种方法得到的I型错误率存在显著的差异。当样本量=800时,其I型错误率相对处于最低水平。
表4 MH和LR的检出率情况
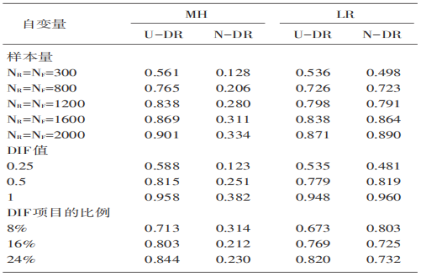
针对一致性DIF,当NR=NF=300时,MH、LR检出率均会接近于0.5。不论在什么样本下,MH检出率均要高于LR(Swaminathan & Rogers,1990);针对非一致性DIF,LR检出率远高于MH,LR适用于其他DIF类型。但是对非一致性DIF,MH检测相对不佳。这是由于,MH是用于测定一致性DIF,对非一致性DIF来说并不十分敏感(Swaminathan & Rogers,1990;Li,Brooks & Johanson,2012)。因此,两种方法在后续只能用于一致性DIF时进行检测和比较。检出率上,不论一致性还是非一致性DIF,均和样本量、DIF值存在正相关。当样本量由之前的300到800,DIF值由0.25扩大至0.5,2种方法在检出率上也会显著地增长。当NR=NF=2000和DIF=1时,两种方法均能够得到较高的检出率,约为0.9。DIF项目的占比,对检出率也会有不同程度的影响。对于一致性DIF,当项目比例扩大后,两种方法在检出率上均会扩大。当DIF项目比列接近于24%(12个题目有DIF),其检出率均不低于0.8;针对非一致性DIF,检出率也会逐步降低[MH:0.314(8%),0.230(24%);LR:0.803(8%),0.732(24%)]。
结束语
本研究得出的结果,基本上和前人报道相似。MH适用于检测一致性DIF,其检出率略高于LR。针对一致性、非一致性DIF,LR的检出率均比较高。不过,它对样本量有着严格的要求。不同类型的DIF项目,其比重增加也会影响检出率。总之,MH是检测一致性DIF较为理想的方法,无需大样本,操作便捷。所以,ETS一种都将MH用于项目DIF的常规分析。若要判断和分析其他方法,建议以MH方法为参照,和其他方法进行比对。LR能够同时检测一致性、非一致性DIF,其功能强大。当样本量接近于1500,有显著的优势。
参考文献:
[1]于媛颖.多种DIF检测方法的比较研究[D]. 北京语言大学,2004.
[2]严芳,张增修. 用Logistic Regression侦察题目差异功能[J]. 应用心理学,2001,7(1):57- 62.
[3]董圣鸿,马世晔.三种常用DIF检测方法的比较研究[J]. 心理学探新. 2001,(1):43-48.

客服QQ:30444492琼网文【2021】1550-113号
增值电信业务经营许可证:琼B2-20210322
出版物经营许可证:新出发龙华出字第(2021)009号
广播电视节目制作经营许可证:(琼)字第00779号
版权所有 ©2002-2024 期刊网(www.qikanchina.com) 琼ICP备2021005105号



