湖北师范大学 湖北省黄石市 435000
摘要:随着大数据时代的到来,人工智能、深度学习研究领域逐渐成为热门。本研究从参数对模型准确率的影响角度来改进模型,数据集采用的是CK+公共人脸数据集,将数据集除去蔑视后,每张照片取最后三张峰值图最终整理得到愤怒、厌恶、恐惧、快乐、悲伤、惊讶六类共计927张48×48格式图片。以该数据集为样本在VGG16模型的基础上综合finetune和bottleneck两种优化策略,探究包括训练集测试集的比例、模型输入的尺寸、锐化翻转等不同的变换方式、Dropout参数对模型准确率的影响,最终模型准确率从开始的89.07%提高到了93.60%,能够完成人脸基础表情的识别任务。
关键词:深度学习;表情识别;图像处理;迁移学习
0引言
根据CNNIC的报告表显示,2021年的6月份在线教育用户的人数已经达到3亿多,占比整个网民规模的30%以上。在大规模环境下,如何提高在线学习的效果是当下一个重要的难题。本研究以返回在线学习者的面部表情数据给教育者为切入点,通过这种方式,减缓在线学习过程中师生的情感分离问题从而提升学习效果。
本研究在VGG16模型的基础上综合finetune和bottleneck两种优化策略,探究了包括训练集测试集的比例、模型输入的尺寸、锐化翻转等不同的变换方式、Dropout,Adma优化器的学习率等参数对模型准确率的影响。最终通过实验结果对比来进行模型的调整,达到可以初步完成人脸基础表情的识别任务。
1VGG16网络结构与迁移学习
1.1 VGG16网络结构
VGG是由Simonyan 和Zisserman在文献《Very Deep Convolutional Networks for Large Scale Image Recognition》中提出的卷积神经网络模型。该模型参加2014年的ImageNet图像分类与定位挑战赛,在分类任务上排名第二。
整个模型共包括13个卷积层、3个全连接层以及5个池化层。由于只有卷积层和全连接层涉及到权重系数,而池化层不属于权重层,所以这也是VGG-16中16数字的来源。

图1 VGG16网络结构图
1.2迁移学习
通常而言,由于数据量的问题,很少从头开始训练整个神经网络。对于在ImageNet数据集上训练好的VGG-16模型,其特征提取能力强,可以直接使用迁移学习的方式。步骤为先自己定义好全连接层,使用VGG-16前面的卷积层作为特征提取器后,将提取到的bottleneck特征图作为新的数据集,再放入全连接层中进行训练。整个过程均采用五折交叉验证,最终训练结果取平均值。流程图如图2所示。

图2 整体训练流程图
2 不同参数对模型的影响
2.1数据来源
数据集采用的为CK+公共人脸数据集,该数据集是由2010年的Cohn-Kanda数据集扩展而来,包含123名参与者,593个图片序列。将数据集除去蔑视后,每张照片取最后三张峰值图并通过OpenCV自带的Haar级联检测来框选出人脸区域后最终整理得到愤怒、厌恶、恐惧、快乐、悲伤、惊讶六类共计927张48×48格式图片。
2.2训练集测试集比例
数据预处理阶段将整个数据集划分为训练集、验证集、测试集三部分,其比例分别为6:2:2和8:1:1这两种常用的数据集划分类别。本次模型训练的输入尺寸为48×48,过程引入Dropout防止模型过拟合,参数值为0.5。实验结果如表1。
表1不同数据划分比例的准确率(百分比)
第一次 | 第二次 | 第三次 | 第四次 | 第五次 | 平均 | |
6:2:2划分 | 89.30 | 88.64 | 89.91 | 90.12 | 87.42 | 89.07 |
8:1:1划分 | 88.92 | 90.13 | 90.07 | 93.68 | 92.10 | 90.98 |
2.3模型输入尺寸
VGG16模型的标准输入尺寸是224×224,但由于数据集本身已经被统一处理成48×48尺寸,图片在进行上采样或者下采样都会改变其像素值的数目,间接的影响模型的特征提取工作。分别对模型的输入层参数修改为32×32、64×64、以及224×224尺寸,观察尺寸对模型的影响。训练过程引入0.5的dropout防止过拟合现象,优化器选择Adam学习率为1e-4。实验结果如表2。
表2不同输入尺寸的准确率(百分比)
第一次 | 第二次 | 第三次 | 第四次 | 第五次 | 平均 | |
32×32 | 80.00 | 83.11 | 82.70 | 79.12 | 80.33 | 81.05 |
48×48 | 88.92 | 90.13 | 90.07 | 93.68 | 92.10 | 90.98 |
64×64 | 92.09 | 92.17 | 94.73 | 93.21 | 92.38 | 92.91 |
224×224 | 92.63 | 89.32 | 91.80 | 90.87 | 91.41 | 91.20 |
2.4旋转翻转缩放
对于图像的增强方面,keras提供了一个ImageDataGenerator的类,类似图形生成器的功能,负责将图片一批一批的拿去给模型训练,并且在这个过程进行各种数据处理。实验结果如表3所示。实验结果可以看见,每种数据增强均有助于提高表情识别的准确率,将几种方式综合起来使用其准确率能得到明显的提高。
表3不同数据处理方式的模型准确率(百分比)
第一次 | 第二次 | 第三次 | 第四次 | 第五次 | 平均 | |
未增强 | 87.33 | 90.31 | 90.03 | 88.14 | 88.34 | 88.83 |
旋转 | 90.92 | 90.33 | 90.06 | 89.34 | 90.11 | 90.15 |
翻转 | 90.03 | 90.14 | 92.22 | 90.70 | 91.80 | 90.97 |
缩放 | 90.33 | 91.12 | 88.19 | 90.36 | 90.25 | 90.05 |
全部 | 92.09 | 92.17 | 94.73 | 93.21 | 92.38 | 92.91 |
2.5不同参数对模型的影响
在网络的全连接层中引入Dropout可以使卷积神经网络在训练时随机丢弃部分神经元,有助于降低过拟合的影响。为了分析不同Dropout 参数对改进的VGG16 网络的影响。根据图3可以看见,无Dropout情况下,存在过拟合现象比较严重,在测试集上的准确率最低。而0.6再往上之后的参数也会因为神经网络过多的节点不工作后,其整体参数下降导致准确率不如之前。
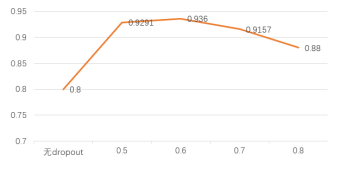
图3不同dropout参数对准确率的影响(百分比)
2.6实验结果分析
表5和表6分别为模型优化前后的混淆矩阵平均值,对比可以看见优化后的模型显然要好于优化前,本研究在不改变模型的结构上,通过实验分析参数对模型的影响将模型的准确率由89.07%提高到93.60%总体提升了4.53%。除了生气和厌恶在准确率上分别为85%和83%较低以外,其他类在测试集上的准确率都在98%以上,这种情况出现的原因可能是由于生气和厌恶表情本身都是耸起鼻子,皱起眉头,存在一定的特征关联现象导致模型的识别率下降。
表5 模型优化前的混淆矩阵(平均)
生气 | 厌恶 | 害怕 | 高兴 | 悲伤 | 惊讶 | |
生气 | 0.7407 | 0.0000 | 0.1111 | 0.0000 | 0.1481 | 0.0000 |
厌恶 | 0.0000 | 0.9166 | 0.0000 | 0.0000 | 0.0833 | 0.0000 |
害怕 | 0.0000 | 0.0000 | 0.9746 | 0.0000 | 0.0000 | 0.0000 |
高兴 | 0.0068 | 0.0000 | 0.0000 | 0.9931 | 0.0000 | 0.0000 |
悲伤 | 0.1764 | 0.0000 | 0.1764 | 0.0000 | 0.6470 | 0.0000 |
惊讶 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 1 |
表6 模型优化后的混淆矩阵(平均)
生气 | 厌恶 | 害怕 | 高兴 | 悲伤 | 惊讶 | |
生气 | 0.8571 | 0.1428 | 0.0000 | 0.0000 | 0.0000 | 0.0000 |
厌恶 | 0.0000 | 0.8333 | 0.0000 | 0.1666 | 0.0000 | 0.0000 |
害怕 | 0.0038 | 0.0000 | 0.9961 | 0.0000 | 0.0000 | 0.0000 |
高兴 | 0.0046 | 0.0000 | 0.0000 | 0.9896 | 0.0057 | 0.0000 |
悲伤 | 0.0000 | 0.0026 | 0.1764 | 0.0000 | 0.9973 | 0.0000 |
惊讶 | 0.0000 | 0.0000 | 0.0134 | 0.0000 | 0.0000 | 1 |
 图4为训练集验证集测试集比例8:1:1,输入尺寸64×64,dropout参数为0.6情况下迭代200次的准确率和损失函数曲线(其中一次),可以看见在迭代200次之后,模型基本已经达到收敛。平均准确率达到93.60%,可以完成识别6类人脸基础表情的任务。
图4为训练集验证集测试集比例8:1:1,输入尺寸64×64,dropout参数为0.6情况下迭代200次的准确率和损失函数曲线(其中一次),可以看见在迭代200次之后,模型基本已经达到收敛。平均准确率达到93.60%,可以完成识别6类人脸基础表情的任务。
图4优化后的模型迭代200次的准确率和损失函数曲线
3总结
本文用整理后的CK+数据集为训练样本,通过迁移学习的训练方式,以经典卷积神经网络VGG16为基础,探索分析了样本训练过程中各参数对模型准确率的影响并分析了其原因。最终以五折交叉验证后的平均准确率为参照在不改变网络结构的基础上从参数改进的角度来优化网络,通过测试集验证结果准确率从改进前的89.07%提高到了93.60%,证明了该优化方式具有一定的实用性,模型在人脸的表情识别方面也具有一定的准确性。但由于受限于数据集的规模以及迭代周期较少,不可避免会出现模型的泛化性较差的情况,在未来研究中还需要在数据集以及网络结构上着手,进一步提高其准确率。
参考文献:
[1]周义飏.基于VGG的人脸表情识别与分类[J].智能计算机与应用,2021,11(09):35-
[2]徐琳琳,张树美,赵俊莉.构建并行卷积神经网络的表情识别算法[J].中国图象图形学
[3]陈筱.基于卷积神经网络的在线教学过程中学习者情感识别研究[D].西安电子科技大学,2020.
[4]周箭峰. 基于微表情情感识别的在线学习者学习效果分析研究[D].湖北大学,2020.
[5]雷芬. 基于深度学习的在线学习情感投入识别研究[D].华中师范大学,2021.

客服QQ:30444492琼网文【2021】1550-113号
增值电信业务经营许可证:琼B2-20210322
出版物经营许可证:新出发龙华出字第(2021)009号
广播电视节目制作经营许可证:(琼)字第00779号
版权所有 ©2002-2024 期刊网(www.qikanchina.com) 琼ICP备2021005105号



