(广东电网有限责任公司肇庆市供电局 广东省 肇庆市 526040)
摘要:随着电网规模不断扩大,电力调控技术不断发展,大量变电站、电厂运行数据接入智能电网调度控制系统。电网运行数据在每日统计分析上报过程中,需要统计大量数据,这些数据由主调OCS系统采集汇总,再由调度进行整理后上报。由于电网规模不断扩大,电网运行数据量日益增加,数据采集汇总流程变得复杂,传统的汇总上报流程不但容易出错,而且效率低下。因此,我们通过一种电网运行数据智能统计分析的工具替代传统的人工统计。
关键字:电网运行数据;智能统计;计算站;单点定义引擎
0.引言
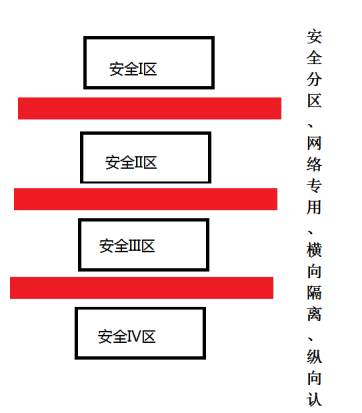
我们工作中编辑整理数据在管理信息区(安全区Ⅳ),调度运行的全部数据在控制区(又称安全区I),因此我们将在“安全分区、网络专用、横向隔离、纵向认证”安全防护原则(如图1安全区原则图),连通这两个区域的数据并通过程序化集抄完成。整个数据决策系统的搭建分为三步:
![]()
1.集抄数据
集抄数据,主站对需要上报的统计数据的原始采集数据进行数学模型集中关联展示。由于主站上有功、电流、潮流图、保护信号等数据繁多,由于电力系统中有功、无功、电流等数据都是复杂非线性的,“计算站”模型是为了简化调度OCS系统的计算过程,通过模型进行公式化、模型化,以简化计算(如图2计算站原理图)。这样做的代价往往是降低计算精度,产生一些计算误差。但考虑到计算量的需要和其他诸多原因的影响,采用模型计算。由于计算站模型往往是对有功、无功、电流等实际过程的简化,因此,模型往往有一些适用范围。超出特定的适用范围,模型通常会产生很大的误差甚至错误的计算结果。经过我们的估算,针对主站上有功、无功、电流等繁多数据计算结果的误差在合理范围内,符合我们日常调度运行数据智能统计的要求。
![]()
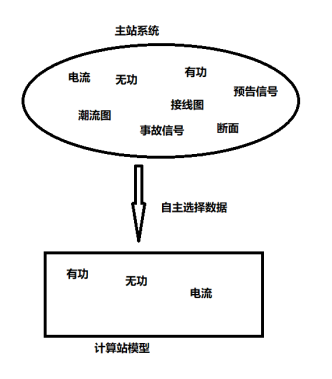
所谓的数学模型,通常指使用数学概念和语言来描述一个系统。创建数学模型的过程叫做数学建模。演绎、归纳和漂移:演绎模型是创建在理论上的一种逻辑结构;归纳模型由实证研究和演绎模型而得;漂移模型则既不依赖于理论,也不依赖于观察,而仅仅是对预期结构的调用。当数学应用在经济学以外的社会科学时,此类模型一直被批评为毫无根据的模型。科学中在突变理论的应用已被定性为漂移模型[1]。“计算站”模型更接近属于演绎模型。
基于南瑞科技公司的D5000系统平台,利用C++在底层源数据中开发“计算站”数学模型,该模型布置在控制区(又称安全区I)主站服务器中,具备简单实用的人机交互界面,通过自定义的公式将调度主站系统的有功、无功、电流等数据关联到至“计算站”,过滤无用的数据。
2.报表收集数据
报表收集电网日报数据,通过开发一种基于javaWeb的电网数据报表系统,它主要使用java开发一种C/S架构的人机交互模块“单点定义引擎”编辑报表,来自定义配置需汇总收集的数据。
C/S(Client-Server)架构是建立在局域网基础上的客户-服务器体系结构,客户端从服务器获取资源,通过提供查询响应来减少网络流量,结构属于点对点的结构模式,数据的处理是基于安全性较高的网络协议之上。C/S面向相对固定的用户群,可对权限进行多层次的校验,对信息安全的控制能力很强,安全性得到很好保障。
C/S结构有三种类型分别是:一层架构、两层架构和三层架构[2]。电网数据报表系统采样三层结构,收集电网日报数据主要涉及到数据存储,包括定义信息和真实的业务表存储管理,表单定义信息对于自定义表单来说,访问特别的频繁,真实业务变更极少,需要不少的过滤查询,所以考虑把工作簿定义信息存储到每一个应用程序内存中,直接从内存中访问工作簿定义信息,工作簿定义信息改变时,通知所有应用定义对应的数据已经更新,应用程序读取数据时,会从“计算站”模型读取最新的数据存储到内存中。工作簿定义信息还会存储到浏览器中,一条总的原则就是访问自定义工作簿定义信息一定要快,就近获取。数据字典(用户信息)也可以存储到本地缓存,管理方式同表单定义本地缓存,数据字典变更极少。“单点定义引擎”实现新建一个工作簿并对每一个单元格定义公式,定义设备的采样(统计)时间、采样类型、统计选项等等,实现与查询日期关联,后端服务每日定时获取。采用tomcat作为web服务器负责对外发布,tomcat服务器提供Web服务端和tomcat层之间的接口,并实现了针对不同数据和不同数据挖掘任务的各种数据挖掘算法,Web层提供一个和用户交互的界面,接受用户的输入,提供挖掘过程的人机交互界面和展示挖掘分析的结果。配置展示“计算站”包含的电网运行数据。“计算站”中采集了整个电网众多数据,这些数据并不全部用于报表。为方便报表的日常维护,在控制区(又称安全区I)开发“单点定义引擎”编辑报表。“单点定义引擎”可以实现新建一个工作簿并对每一个单元格定义公式,定义设备的采样(统计)时间、采样类型、统计选项等等,实现与查询日期关联。
3.收取报表
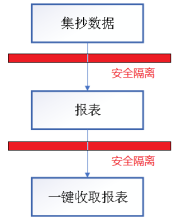
收取报表,基于单向传输的网络数据包安全策略的,数据包的TCP、ICMP、UDP和IP报头确定是否允许通过。单向传输又称单向访问,指在通讯过程中只允许一端主动传输向另一端,相反另一端不能反向传输[3]。传输可靠的保证方式有:校验和、确认应答、超时重传、连接管理、流量控制、拥塞控制等。校验和,在数据传输过程中,把传输的数据加起来,最前面的进位补到最后一位,然后取反得到校验和。发送方和接收方验证校验和是否相同。不相同则数据传输有误,相同也可能有问题。超时重传,发送数据后长时间没收到回应会把数据再发一次。连接管理规则,四次握手第五次挥手。流量控制,控制传输数据的大小。拥塞控制:传输数据时是慢启动开始,先发送一点点数据去探测网络拥不拥塞,如果不拥塞则大量的发送数据。如果拥塞了则又很慢的发送数据。这样是为了尽快发送数据,避免网络拥塞造成一系列问题。数据包过滤技术简单容易实现,缺点是无法防止通过应用层协议传输的数据包带来的安全威胁,在此基础上设定单向允许的规则将填补上面的缺点。在上述措施确保控制区(又称安全区I)与生产管理区(安全区Ⅲ)安全隔离后,Web层提供一个和用户交互的界面。整个报表通过数据包通知的形式,单向同步至生产管理区(安全区Ⅲ)的《数据决策系统》。调控员进入管理信息区的《数据决策系统》一键收取报表。系统结构如图3
![]()
4.结语
系统通过自动集抄数据、生成报表、再一键收取报表的全自动流程方式实现快速获取并统计分析电网运行数据。工具主要工作原理有五个步骤:①自动统计集抄数据;②使用报表汇总数据;③主站服务器中开发“计算站”,通过自定义的公式将调度主站系统的有功、无功、电流等数据映射至“计算站”,滤掉无用的数据,减轻服务器负荷。④在控制区(又称安全区I)开发“单点定义引擎”编辑报表。“单点定义引擎”可以实现新建一个工作簿并对每一个单元格定义公式,定义设备的采样(统计)时间、采样类型、统计选项等等。⑤基于单向数据包安全策略的,确保控制区(又称安全区I)与生产管理区(安全区Ⅲ)安全隔离后,调控员进入管理信息区的《数据决策系统》一键收取报表。
【参考资料】
(1)专著:[1] Zerkowski R M. Social sciences as sorcery[M]. Deutsch, 1972.
(3)专著:[2] linux. C/S和B/S架构的工作原理及优缺点[J]. linux浅谈. 2020
(4)专利:[3] 刘晓建.信息在不同网络间单向传输的方法:9791020[P].2019

客服QQ:30444492琼网文【2021】1550-113号
增值电信业务经营许可证:琼B2-20210322
出版物经营许可证:新出发龙华出字第(2021)009号
广播电视节目制作经营许可证:(琼)字第00779号
版权所有 ©2002-2024 期刊网(www.qikanchina.com) 琼ICP备2021005105号



