国网内蒙古东部电力有限公司供电服务监管与支持中心 内蒙古通辽 028000
摘要:电力行业是我国经济社会的重要组成部分,加强电能计量运维工作不仅能提高企业的可持续发展,促进经济增长,还能切实优化计量方式,使用户获得更好的用电体验。
关键词:电能计量大数据;计量装置;运行维护
1计量装置应用分析
①传统电力计量中的电能表被逐渐替代。随着信息科技的不断发展,新型电子式智能电能表成为当前应用最广泛、使用效率最高的计量装置,该设备不仅能实现传统电能表的功能,还在此基础上进行了细节的优化与提升,使数据整理过程更高效、更便捷,同时也大大降低了计量装置的运维难度。同时,电子式智能电能表的电能采集终端能够根据收集到的信息数据,进行数据传输、指令下达,完成自动化工作,进一步提升了电能表的能效。②电能计量技术的迅速发展。实现了高级计量体系的建设以及远程抄表的智能化,能够切实将电能传送中产生的线路耗损降到最低,且可以自行分析耗电异常的形成原因,从而降低维护人员的工作难度,更好地开展运维工作。③通信技术的升级与创新。通过以光纤线路作为信息传递的渠道,完成信息管理的统筹规划,使数据参数的传递效率更高,资源分享更及时。
2智能电网环境下电能计量大数据智能多维分析
2.1总体方案设计
该方案采用Spark系统与Hadoop模型进行结合,利用ETL技术、Spark内存计算框架和Spark SQL技术来处理电能计量数据,在技术方案中融入OLAP技术,实现不同种类电能计量大数据的多维度分析,从不同的角度挖掘数据信息,总体架构示意图如图1所示,方案架构包括数据采集层、数据存储计算层、数据分析层和应用管理层四个层次。
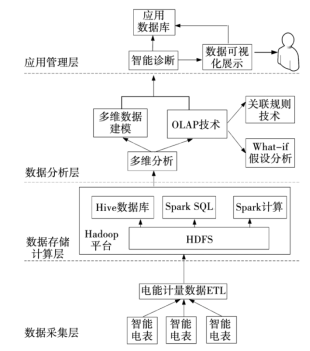
图1智能多维分析系统总体框架图
①数据采集层
数据采集层的主要任务是从各个智能电表中收集电能计量数据,通过智能电表的智能通讯技术可以实时地远程传输数字信号至通讯服务器。应用ETL技术实现电能计量大数据的初步处理,将初步处理后的大数据信息输出至数据存储计算层。
③数据存储计算层
数据存储计算层的主要作用是对采集到的数据进行存储和计算,通过Hadoop平台将HDFS系统与Hive数据库结合,利用Spark系统中信息读写技术和计算算法对数据进行高效率地处理,之后将处理好的数据传输至数据分析层。
③数据分析层
电能计量大数据分析是整个智能多维分析系统中的重要部分,利用该技术能够融合多维数据建模与OLAP技术中的关联规则技术和What-if技术,进而实现电能计量大数据的多维分析。然后将分析结果传输至应用管理层中进行系统智能诊断。
④应用管理层
应用管理层的主要任务是将分析结果进行智能诊断,然后传输至应用数据库中,以备下次使用。对于特别情况,还可以通过数据可视化技术在显示屏上进行展示,通过直观显示,能够使电能计量管理人员进一步分析和研究电能计量装置存在的问题,分析后的数据信息被传递到应用数据库进行存储。
2.1关键技术设计
① Spark技术
由于Hadoop模型的MapReduce算法计算效率低下,且存在HQL转换成MapReduce格式效率低下的问题,本文采用Spark技术从信息读写和计算方面弥补这些缺陷。Spark是Hadoop模型的优化,具有很好的延展性和高容错率,不仅拥有Hadoop模型中所有的优点,而且操作类型更多,编程模型更加灵活。Spark还可以把运算的中间数据进行存储,而不需要再写回HDFS里。在Spark的计算框架中,本研究通过分布式弹性数据集(RDD)作为电能计量大数据的样本分析,实现数据的抽取,在计算过程中,本系统具有存储功能,计算输出的数据信息被实时存储。因此可以比Hadoop模型的MapReduce算法计算效率高出数倍。Hadoop计算框架流程图如图2所示。
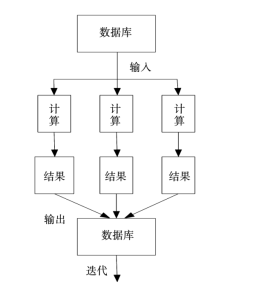
图2Hadoop计算框架
Spark的计算框架流程图如图3所示。Hive数据库所用的语法虽然与传统的SQL语法没有太大区别,数据处理起来非常方便,但是在Hadoop平台上HQL必须要换成MapReduce算法才能运行,从而浪费了时间。Spark SQL技术则基于RDD把运算过程存储起来,减少中间读写过程的时间。具体的优点有:①Spark SQL使用的是内存列存储,在读写方面优势很大;②Spark SQL可以使用特定代码动态编译和运行所要匹的配表达式;③Spark SQL在编写代码时使用的是Scala,这种代码虽然编程稍稍复杂,但非常高效,且操作简单。因此,电能计量数据选择使用Spark SQL的形式进行计算和处理。

图3Spark计算框架示意图
② ETL技术
ETL技术能够抽取、转换和装载电能计量大数据。传统基于SSIS和MapReduce计算模型的ETL虽然能够分布式地处理各种电能计量数据,但是由于MapReduce计算模型的编程语言所带来的局限性,使ETL在读写的过程中存在性能差、处理速度慢等问题。本文采用在Spark技术下分区聚合方法的ETL,这种方法使得ETL保留分布式特点的优势,且不用局限于Map和Reduce方式。在数据仓库处理过程中,经常需要按一定的维度对不同程度的事实表数据进行聚合。在Spark的环境下,可以利用RDD先进行分区内聚合,而后进行分区与分区之间的聚合。分区聚合先把电能计量大数据中每个分区内部先聚合,并且缓存起来,之后在分区之间进行聚合,这样一步步将海量的电能计量数据进行汇总处理,可以有效地减少因数据传输量庞大所造成的性能问题,加快数据处理的速度。
③ OLAP技术
OLAP技术的全称为联机分析处理,由于其对数据分析有明显的优势,所以在金融领域、电信领域、军事领域等被广泛应用,但OLAP技术在电能计量方面的研究还比较少。OLAP技术可以进行多角度、多层面的信息分析,从而发现电能计量数据中的隐含信息。
在应用OLAP技术时,通常采用的技术手段有数据钻取、切片和旋转。数据钻取包括电能计量大数据上钻取和电能计量大数据下钻取。电能计量大数据上钻取从下层至上层逐步分析大数据,电能计量大数据下钻取从上层至下层逐步分析大数据;在对电能计量大数据进行切片时,在电能计量大数据集合中所指定的维度上进行数据选择;电能计量大数据旋转指将抽取的多维数据集合中不同纬度和数量的数据信息进行空间变换。通过这种方式能够多角度实现数据分析。
结语:
在目前智能电网环境下,本文根据电能计量大数据的特点提出了一种基于大数据的电能计量智能多维分析系统,利用信息化技术来解决传统方法存在的问题。利用Spark技术基于RDD把运算过程存储起来的操作,减少中间读写过程的时间;利用ETL技术中分区聚合的方法把电能计量大数据分区内部先聚合且缓存,之后在分区之间进行聚合,加快数据处理速度。
参考文献:
[1]李骁,赵曦,王者龙,等.融合数据挖掘的电能计量资产自动化智能库房管理方法[J].电子设计工程,2021,29(12):102-107.
[2]文耀宽,王献军,王峻,等.基于随机森林算法的电力计量大数据分析平台研究[J].计算机技术与发展,2021,31(6):216-220.

客服QQ:30444492琼网文【2021】1550-113号
增值电信业务经营许可证:琼B2-20210322
出版物经营许可证:新出发龙华出字第(2021)009号
广播电视节目制作经营许可证:(琼)字第00779号
版权所有 ©2002-2024 期刊网(www.qikanchina.com) 琼ICP备2021005105号



