西南民族大学 四川 成都 610225
摘 要:针对目前基于关键词的藏文古籍文献学特征检索需要大量著录人力、专业的辨识能力和缺乏定量标准的问题,本文将基于内容的图像检索技术引入到藏文古籍文献学特征检索中,即采用“以图搜图”的方法在藏文古籍图像数据库中检索与模板图像具有相同或相似文献学特征的图像。实验在所构建的5个藏文古籍文献学特征数据集和7种基于内容的图像检索技术特征提取算法上进行,证明了方法的可行性。该方法可为在海量文献图像数据库中的文献学特征检索问题提供有益参考。
关键词:藏文古籍;文献学特征;基于内容的图像检索;深度学习
1引言
在文献学学科中,墨种、字体类型、文献载体、装订形式,甚至污损程度、版面残缺程度等特征,被称为文献学特征。藏文古籍中的文献学特征往往是藏文文献学研究者们重点关注的内容,被广泛用于对文献特点、功能、类型、生产、分布、发展规律和文献发展历史等研究中。藏文古籍文献学特征检索是指通过信息检索手段从文献数据库中检索出满足指定文献学特征的藏文古籍。目前,在现有藏文古籍文献数据库中,藏文古籍文献学特征检索均是基于关键词的,这需要文献学研究者人工地进行辨识,并把文献学特征描述信息录入数据库。但是,在文献信息数字化的背景下,藏文古籍文献数据库的规模不断扩大,基于关键词的文献学特征检索面临巨大挑战:对海量藏文古籍图像标注文献学特征不仅费时费力,还需要专业的辨识能力和缺乏定量标准。
对此,本文将把基于内容的图像检索(Content-basedimageretrieval,CBIR)技术引入到藏文古籍文献学特征检索中,即采用“以图搜图”的方法在藏文古籍图像数据中检索与模板图具有相同或相似文献学特征的图像。这是一种不同于基于关键词的藏文古籍文献学特征检索的方法,可快速、高效地实现海量数据库中的文献学特征检索。
本文其余部分组织如下:第2节介绍藏文古籍文献学特征和基于内容的图像检索的相关工作,第3节介绍基于内容的藏文古籍文献学特征检索方法,第4节是实验,第5节是总结。
2相关工作
20世纪90年代末国外就有学者开始了藏文文献数据库建设的理论研究与实践探索[1],先后建设了藏传佛教资源中心数据库[2]、数字喜马拉雅[3]、雪域数码图书馆[4]、西南民族大学数字文献馆[5]、中国藏文文献资源网和中国藏文学术期刊网[6]等,这些数据库中基本都有藏文古籍文献学特征检索功能,不过都是通过基于关键词的检索方式实现的。
CBIR是由T.Kato[1]于1992年提出,其核心是使用图像的可视特征对图像进行检索。从本质上讲,它是一种近似匹配技术,融合了计算机视觉和数据库等多个领域的技术成果,其中的特征提取和索引的建立可由计算机自动完成,避免了人工描述的主观性[7]。
CBIR的发展分为两个阶段,即特征工程阶段和深度学习阶段[8]。在特征工程阶段,CBIR采用人工设计特征的方式进行特征表示,有全局特征表示算法和局部特征表示算法。其中,全局特征表示算法包括基于颜色特征的颜色直方图(Histogram)、颜色相关图、颜色矩和一致性矢量等,基于纹理特征的共生矩阵、Tamura特征、Gabor变换和多尺度自回归模型等,基于形状特征的傅里叶描述符、Diasy、边缘直方图(Edge)、方向梯度直方图(Histogram of Gradient,HOG)等。局部特征表示算法包括SIFT特征、视觉词袋模型、Fisher向量和局部聚合描述符向量等[9]。
2012年,随着AlexNet在图像分类上大获成功,人工设计特征的主导作用已被深层卷积神经网络(Deep Convolutional Neural Network,DCNN)取代,CBIR进入深度学习阶段。DCNN可以直接从数据中学习具有多个抽象层次的特征表示,因此被应用于CBIR中。并且,基于DCNN的CBIR应用还在不断扩展,如人、车再识别,地标检索,遥感、医学图像搜索,在线产品搜索等[10]。为了方便,下文把特征工程阶段和深度学习阶段的CBIR分别简称为传统CBIR和深度学习CBIR。
据我们调研,虽然CBIR技术取得了较大发展,但尚未见到将CBIR技术用于藏文古籍文献学特征检索的报道。
3基于内容的藏文古籍文献学特征检索方法
为了解决基于关键词的藏文古籍文献学特征检索需要大量著录人力、专业的辨识能力和缺乏定量标准的问题,本文把CBIR技术引入到藏文古籍文献学特征检索中,提出基于内容的藏文古籍文献学特征检索方法:用户输入一张藏文古籍图像作为模板图,在藏文古籍图像库中查找具有相同或相似文献学特征内容的其它图像。技术框架如图1所示,主要有藏文古籍文献学特征提取和特征匹配两个关键步骤。
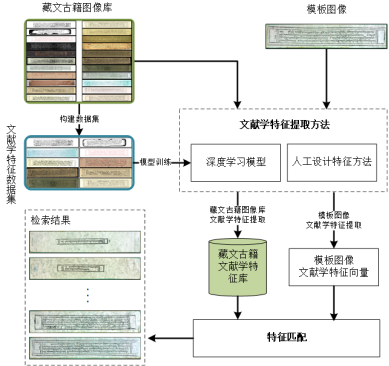
图1基于内容的藏文古籍文献学特征检索方法
在藏文古籍文献学特征提取中,主要解决如何用向量有效地描述
藏文古籍图像文献学特征的问题,这和其他CBIR技术一样,有基于人工设计特征和基于深度学习模型等两类特征提取方法。其中,基于深度学习模型类的方法需要构建用于训练的文献学特征数据集:从文献学特征视角在藏文古籍图像库中筛选出部分图像并分类,构建藏文古籍文献学特征数据集,例如从墨种文献学特征视角筛选出满足深度学习模型训练所需数量的黑色、红色、黄色、白色等墨种的藏文古籍图像,并按墨种类别进行标注。本文共从纸张质地、墨种、版式、“纸张质地+墨种”、“纸张质地+墨种+版式”等5个文献学特征视角,构建了5个藏文古籍文献学特征数据集。其中,“纸张质地+墨种”表示同时从纸张质地与墨种的视角对古籍图像分类,即只要古籍图像在纸张质地与墨种二者中有一者不同就属于不同分类。同理,“纸张质地+墨种+版式”表示同时从纸张质地、墨种与版式的视角对古籍图像分类,即只要古籍图像在纸张质地、墨种与版式三者中有一者不同就属于不同分类。
经过文献学特征提取后,每张图像均被特征向量描述,描述藏文古籍图像库中图像的特征向量生成藏文古籍文献学特征库,描述模板图像的文献学特征向量与藏文古籍文献学特征库进行匹配,按匹配程度排序返回检索结果图像。其中,匹配的过程是指文献学特征之间的相似度计算,例如可采用曼哈顿距离、余弦相似度距离[14],这两种距离计算公式分别如下:
![]() (1)
(1)
 (2)
(2)
其中,![]() 与
与![]() 表示待求相似度的两个n维文献学特征向量。
表示待求相似度的两个n维文献学特征向量。
4实验
4.1实验设置
实验环境为Ubuntu20.04操作系统、Python 3.6,GPU为16GB Tesla SMX2 P100,CPU为两张 Xeon Gold 6130H,运行内存大小为 32GB。
为了更广泛地验证基于内容的藏文古籍文献学特征检索方法的有效性,实验同时选用了传统CBIR和深度学习CBIR,前者包括Histogram、Gabor、Daisy、Edge和HOG等5种算法,后者包括VGG、ResNet等2种深度神经网络模型。这7种算法的参数设置同文献,其中VGG和ResNet模型分别选择VGG19和ResNet152。VGG19和ResNet152的训练过程采用文献中的预训练模型,设置训练轮数(epochs)为10、训练批次大小为5、学习率为1e-5、权重衰减系数为5e-4,选择交叉熵损失函数和Adam优化器。ResNet152的输入图像大小依据藏文古籍图像的一般情形统一为396像素×1920像素,VGG19由于全连接层的限制,输入图像的大小统一为224像素×224像素。
实验采用第3节所述的纸张质地、墨种、版式、“纸张质地+墨种”、“纸张质地+墨种+版式”数据集,其中类别数分别为10、4、2、11、16,版式数据集的每类图像数为1920张,其余数据集每类图像数均为240张。各数据集按9:1:2的比例分为训练集、验证集和测试集,其中训练数据集和验证数据集用于训练和验证VGG和ResNet,测试数据集用于测试所有算法。
在特征匹配阶段的相似度计算时,Histogram、Daisy、HOG、VGG和ResNet选用曼哈顿距离,Gabor和Edge选用余弦相似度距离。
为了衡量算法模型的性能,本文统计了算法耗时和特征匹配精度。算法耗时是指包含特征提取和特征匹配的总时长,其中特征提取时长是指一张图像的文献学特征计算时长,特征匹配时长是指模板图像的文献学特征与数据库中图像的文献学特征之间相似度计算的时长。特征匹配精度选用平均精度均值的均值(Mean Mean Average Precision,MMAP),其是反映算法在全部相关图像上性能的单值指标。
4.2实验结果及讨论
VGG19和ResNet152在训练过程中的损失函数值(Loss)和验证精确度(Accuracy)的变化曲线如图2所示,其中,“paper”、“ink”、“edition”、“paper_ink”和“paper_ink_edition”分别表示纸张质地、墨种、版式、“纸张质地+墨种”和“纸张质地+墨种+版式”数据集。可见,神经网络模型均在10轮时达到稳定。

图2VGG19、ResNet152训练损失函数值、验证精确度曲线
表 1各算法的MMAP、特征提取时长和特征匹配时长
算法 | MMAP(%) | 特征提取时长(s) | 特征匹配时长(s) |
Histogram | 88.30 | 1.22E+00 | 2.34E-05 |
Gabor | 85.24 | 4.56E+01 | 2.70E-05 |
Daisy | 72.78 | 7.74E+00 | 5.96E-06 |
Edge | 23.40 | 1.99E+01 | 2.67E-05 |
HOG | 77.00 | 3.18E+00 | 5.77E-06 |
VGG19 | 91.38 | 2.71E-02 | 6.89E-06 |
ResNet152 | 99.86 | 1.05E-01 | 6.70E-06 |
表 1为各算法的MMAP、特征提取时长和特征匹配时长在5个数据集上的均值。从中可知:
(1)在MMAP
上,深度学习CBIR中的算法均优于传统CBIR中的算法,前者达到90%以上;在深度学习CBIR中,ResNet152优于VGG19,前者达到99%以上;在传统CBIR中,有部分算法表现较优,如Histogram、Gabor的MMAP均值达到85%以上。
(2)在特征提取时长上,深度学习CBIR中的算法均优于传统CBIR中的算法,均远少于1s;在深度学习CBIR中,VGG19优于ResNet152;在传统CBIR中,Histogram最优。
(3)在特征匹配时长上,深度学习CBIR与传统CBIR各有优劣,且均远少于相对特征提取时长。
可见,本文提出的基于内容的藏文古籍文献学检索方法是有效的,且其中深度学习CBIR普遍优于传统CBIR。
5总结
针对目前基于关键词的藏文古籍文献学特征检索需要大量著录人力、专业的辨识能力和缺乏定量标准的问题,本文提出了基于内容的藏文古籍文献学特征检索方法:构建藏文古籍文献学特征数据集,用其训练并选择CBIR技术中的特征提取算法,用特征提取算法计算每张藏文古籍图像的文献学特征向量,模板图像的文献学特征向量与藏文古籍图像库中所有图像的文献学特征向量进行匹配,按匹配程度排序返回检索结果图像。实验证明了本文方法的可行性。
虽然本文取得了一些进展,但基于内容的文献学特征检索仍然是开放性的研究,例如:本文方法有待扩展应用于其他文种古籍的文献学特征检索中;字体类型、文献污损程度、版面残缺程度等更广泛、更细致的文献学特征的检索也有待验证。
参考文献
[1]德萨.论藏文文献数据库建设实证调查研究的必要性——兼谈价值及其意义[J].西藏科技,2014(09):77-80.
[2]索珍.美国主要涉藏研究机构和藏学研究人员现状及其分析[J].中国藏学,2006(02):271-281.
[3]李梦瑶,胡建.藏文文献数据库建设现状综述[J].数字技术与应用,2020,38(04):218-219.
[4]李涛.戴维·吉玛诺和雪域数码图书馆[J].中国西藏(中文版),2005(06):64-66.
[5]西藏大学图书馆[J].大学图书馆学报,2015,33(04):18.
[6]孟繁杰, 郭宝龙. CBIR关键技术研究[J]. 计算机应用研究, 2004(7):5.
[7]陈剑雄, 张蓓. 简析图像检索系统中的CBIR技术[J]. 情报探索, 2010(7):3.
[8]孟繁杰, 郭宝龙. CBIR关键技术研究[J]. 计算机应用研究, 2004(7):5.
[9]王鑫城. 基于内容的图像检索系统的研究[D].东华大学,2021.
姓名:邢鹏辉(1997.09.24);性别:男,民族:土家族; 籍贯:重庆市酉阳县人,学历:硕士研究生在读,就读于西南民族大学;研究方向:数据工程。
基金项目:国家社会科学基金重大招标项目“藏文典籍文献整理与全文数字化研究”(16ZDA166);
西南民族大学研究生创新型科研项目“面向藏文古籍文献学特征的图像检索研究”(YB2022410)资助

客服QQ:30444492琼网文【2021】1550-113号
增值电信业务经营许可证:琼B2-20210322
出版物经营许可证:新出发龙华出字第(2021)009号
广播电视节目制作经营许可证:(琼)字第00779号
版权所有 ©2002-2024 期刊网 琼ICP备2021005105号



