HU Shuntian OU Yanghao LING Ling XIE Dongling XU Dezhen LI Chaoyun
摘要:
基于Bounding Box预测原理结合孪生网络结合构建深度学习模型实现对品牌logo识别。该模型与传统滑块窗口构建深度学习模型相比,大大减少了模型的计算成本提高了计算效率,同时相比传统深度模型,使用孪生网络能够具有更好的泛化能力。
关键字:
图像识别、深度学习、孪生网络、Siamese模型、logo识别
0 引言
随着经济的发展,品牌商标、IP文化等具有一定象征意义的logo图标已经成为了大部分企业和团队代表自己的意识形态,具有不可忽略的经济价值。同时,与二维码扫码识别相比logo在人眼辨识度以及经济推广效益领域更具有价值。综上所述,对logo识别技术的研究具有重要价值。
1 模型介绍
基于BoundingBox预测的YOLO模型算法,是当前目标检测中最常用的算法之一,由Redmon等人在《You Only Look Once: Unified real-time object detection![]() 提出,其核心思想在于将图片划分为多个区域,并在每个区域上都使用图像分类和定位算法,每个区域只需关注自己的区域内是否包含感兴趣内容的中心点。每块区域由5个预测值组成:(x,y,w,h)定位信息、置信度PC及分类信息等。
提出,其核心思想在于将图片划分为多个区域,并在每个区域上都使用图像分类和定位算法,每个区域只需关注自己的区域内是否包含感兴趣内容的中心点。每块区域由5个预测值组成:(x,y,w,h)定位信息、置信度PC及分类信息等。
孪生神经网络Siamese模型,其由两个相同的分支神经网络建立的耦合架构组成,以两个样本为输入,输出其嵌入高纬度空间的表征,最后通过计算不同表征之间的欧式距离以比较输入样本之间的相似程度。孪生网络在1993年Yann等人发表的论文Signature Verification using a “Siamese” Time Delay Neural Networ![]() 中首次提出,如图1所示。
中首次提出,如图1所示。
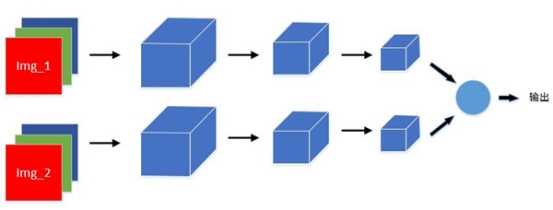
图1 Siamese模型概念图
本文将基于BoundingBox区域预测原理结合孪生网络模型构建SBB模型实现logo预测及识别,其由两部分组成,前部分为由YOLO模型组成,后部分由Siamese模型组成,与传统模型相比,SBB模型极能够以较低的计算成本得到较好的效果。作为SBB模型的一部分,YOLO模型主要负责对每个区域内进行感兴趣内容的识别与检测,并输出所在区域感兴趣内容的置信度、x、y、w、h。其核心思想在于将图片分成多个区域并在各个区域进行目标检测,并将目标检测问题处理成回归问题,与传统滑块窗口物体检测相比,无论是在精确率和召回率上还是在运行效率上,YOLO模型的boundingbox区域预测算法都更为高效。Siamese模型作为SBB模型的另一部分,负责为YOLO模型得到的置信度较高的感兴趣区域提供相似值,利用不同相似值之间的维度距离可以有效的对感兴趣区域内内容进行判别与识别,达到分类效果。与传统深度学习模型相比,Siamese模型的优点在于:训练成本较低,往往只需要少量的数据便可以达到较好的效果,同时,利用图像之间各自相似值的维度距离大小进而判断图像是否属于同一类的原理,使得其当需要改变分类种类数量时,不需要改变模型的结构而重新训练。
2 实验分析
对于利用CNN深度学习识别图像来说,图像的质量直接关系着模型识别效果的好坏。在实际中,用户在上传图像进行图像识别的过程里,图像往往会因为各种原因导致图像受到污染,例如在图像获取的过程中,由于受传感器属性、工作环境、电子元器件和电路结构等影响会引入场效应管的沟道热噪声、光子噪声、暗电流噪声等或因为拍摄技术、拍摄方法等人为因素而导致图片模糊产生一定的失真问题;在图像信号传输的过程中,也可能会因为传输媒介不稳定或硬件设备等的不完善、网络波动等不确定因素对数字图像造成污染引入噪声,常见的噪声有:椒盐噪声、高斯噪声等。综上所述,当用户上传图像时,我们需要对原始图像进行预处理操作。面对不同的噪声的干扰,使用合适的图像恢复技术可以有效解决或削弱噪声的干扰。例如,利用中值滤波技术可以有效处理椒盐噪声,同时较好的削弱噪声。
Yolov5模型主要由CBR、CSP1_x、CSP2_x作为基本构架。训练图像经由输入端输入后,模型将使用Mosaic数据增强对训练数据进行处理,通过随机剪裁、随机缩放等图片处理方式对数据样本集进行增强,并通过Slices模块在不减少特征值的情况下降低图像的大小增加维度,同时,在Neck上还采用了FPN+PAN的结构,通过上采用及下采样的方式,将上层的强语义特征传递下去并将底层的定位特征传递上去,对整个特征金字塔进行增强,有利于从不同的主干层对不同的检查层进行特征聚合
Yolov5模型训练的损失函数有三种分别为:分类损失、定位损失以及置信度损失,总体损失即为三者加权之和,通过修改权值可以改变对不同损失函数的关注度。对于分类预测,yolov5在模型上采用了二元交叉熵。
即:
Cost(y,![]() ) =
) = ![]() ) (1)
) (1)
对于边界框预测上则采用CIOU即:
CIOU(B,![]() )
) ![]() (2)
(2)
v = 4/![]() (arctan(
(arctan(![]() )-arctan(w/h)
)-arctan(w/h)![]() (3)
(3)
![]() (4)
(4)
![]() :代表预测框与真实框中心点距离的平方
:代表预测框与真实框中心点距离的平方 ![]() :代表最小方框面积
:代表最小方框面积
对于Siamese模型,使用VGG16模型作为该模型的backbone,其原因在于VGG16模型结构仅需要较低的计算成本便可以在孪生网络中取得较好的效果。模型搭建好后,使用Triple![]() 损失函数对模型进行训练即使用三张图片作为一个训练样本,假设trainA为需要识别的图片,trainP为我们认为与trainA十分相似的图片,trainN为我们认为与trainA不是一样的图片,将他们划为一组,将trainA、trainP、trainN放入Siamese模型中,得到对应的f(A),f(P),f(N)(f(x)为x图的相似值),f(A)与f(P)的相似程度可以表示成
损失函数对模型进行训练即使用三张图片作为一个训练样本,假设trainA为需要识别的图片,trainP为我们认为与trainA十分相似的图片,trainN为我们认为与trainA不是一样的图片,将他们划为一组,将trainA、trainP、trainN放入Siamese模型中,得到对应的f(A),f(P),f(N)(f(x)为x图的相似值),f(A)与f(P)的相似程度可以表示成![]() ,即欧拉距离,同理,f(A)与f(N)的相似程度可以表示成
,即欧拉距离,同理,f(A)与f(N)的相似程度可以表示成![]() 。当
。当![]() 越接近0时,说明f(A)与f(P)越相似,反之越不相似。为了使识别样本train_A与正确识别样本train_P越相近,与错误识别样本train_N越远,所以可以得到:
越接近0时,说明f(A)与f(P)越相似,反之越不相似。为了使识别样本train_A与正确识别样本train_P越相近,与错误识别样本train_N越远,所以可以得到:
![]() -
- ![]() α
α ![]() 0 (5)
0 (5)
在这里为了防止设置模型参数设为零变量时导致梯度下降无法更新模型参数加上![]() ,由上可得Siamese模型的损失函数为:
,由上可得Siamese模型的损失函数为:
Cost(![]() ,
,![]() ,
,![]() ) =
) = ![]() (6)
(6)
对损失函数进行batch梯度下降法或mini batch梯度下降法并结合Adam、RMSprop等优化算法进行优化。
SSB模型经过epoch为300、样本数为300的训练后,测试集效果展示图及Precision及Recall趋势图如图2、3所示:

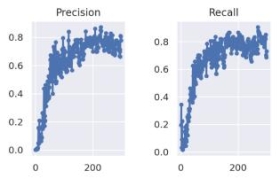
图2测试集效果展示图 图3 Precision及Recall趋势图
可以发现,当epoch为200时,Precision及Recall趋于稳定,并达到80%以上高度。但同时需要注意的是,需要检测模型是否存在偏差或方差问题。当训练集的损失函数Cost![]() 较大,则说明模型发生了偏差问题,此时需要将模型的结构复杂化,解决办法有:增加卷积的层数、模型的深度等,但同时需要注意的是,当模型的深度较大时,模型往往容易发生梯度消失或梯度爆炸等问题,可以在结构的基础上增添RestNe
较大,则说明模型发生了偏差问题,此时需要将模型的结构复杂化,解决办法有:增加卷积的层数、模型的深度等,但同时需要注意的是,当模型的深度较大时,模型往往容易发生梯度消失或梯度爆炸等问题,可以在结构的基础上增添RestNe![]() 残差网络结构或使用CSPRestNet网络等方式进行解决。当训练集的损失函数较小而验证集的损失函数Cost
残差网络结构或使用CSPRestNet网络等方式进行解决。当训练集的损失函数较小而验证集的损失函数Cost![]() 较大,则说明模型发生了方差问题,可以使用添加惩罚项的正则化的方法进行解决,也可以在全连接层上使用droopout算法进行处理,比较推荐的方法是在卷积层激活函数前使用BN归一化处理。
较大,则说明模型发生了方差问题,可以使用添加惩罚项的正则化的方法进行解决,也可以在全连接层上使用droopout算法进行处理,比较推荐的方法是在卷积层激活函数前使用BN归一化处理。
3 结束语
SSB模型是由Siamese网络与Bounding Box预测结合而成,具有不错的鲁棒性,同时,使用SSB模型构造深度学习实现品牌logo识别与传统的滑块窗口算法相比,SSB模型极大提升了模型的计算效率,减少了计算成本,logo识别价值体现在其具有良好的经济推广效益以及人眼识别度,在安全上,与二维码相比,用户可以根据logo图型不一致、颜色不相同而进行判断信息的真伪并且实现logo识别技术可以运用在许多方面上。在效益上,用户在识别logo的过程中,会增加用户对相关品牌、企业的辨识度,从而提高客户对产品的友好度。
参考文献:
[1]Redmon J , pvala S , Girshick R , et al. You Only Look Once: Unified, Real-Time Object Detection[J]. IEEE, 2016.
[2]ROOPAK, SHAH, EDUARD, et al. SIGNATURE VERIFICATION USING A "SIAMESE" TIME DELAY NEURAL NETWORK[J]. International Journal of Pattern Recognition and Artificial Intelligence, 1993, 07(4):669-669.
[3]Schroff F , Kalenichenko D , Philbin J . FaceNet: A Unified Embedding for Face Recognition and Clustering[J]. 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2015.
[4]He K, Zhang X, Ren S, et al. Deep residual learning for image recognition[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2016: 770-778.
[5]Wang J , Yang S , Leung T , et al. Learning Fine-Grained Image Similarity with Deep Ranking[C]// 2014 IEEE Conference on Computer Vision and Pattern Recognition. IEEE, 2014.
【作者简介】
胡顺天(2000—),男,广西玉林人,本科生,专业方向:软件工程深度学习开发应用;
欧阳浩:教师,研究方向:软件工程
梁琳:本科生,专业方向:软件工程
谢东伶:本科生,专业方向:数字媒体
徐德振:本科生,专业方向:软件工程
黎朝雲: 本科生,专业方向:软件工程
【注释】
广西柳州 545006
[基金项目] 广西科技大学2021年自治区级大学生创新创业训练项目(S202210594072)

客服QQ:30444492琼网文【2021】1550-113号
增值电信业务经营许可证:琼B2-20210322
出版物经营许可证:新出发龙华出字第(2021)009号
广播电视节目制作经营许可证:(琼)字第00779号
版权所有 ©2002-2024 期刊网(www.qikanchina.com) 琼ICP备2021005105号



