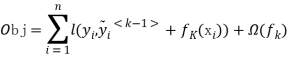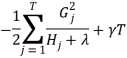杭州师范大学 数学学院 浙江杭州311121
摘要:随着企业对机械设备的科学管理与维护的需求日益迫切,而齿轮箱在大型机械设备中更是得到广泛应用,对齿轮箱运行状态是否故障的检测和诊断成为企业的一大忧患。最常用的对齿轮箱故障的检测便是通过对其四个不同部位加装加速度传感器,这种方法能在齿轮箱不停机的时候进行,便捷且节约时间。本文则阐述了如何通过分析传感器采集到的振动信号,来检测和诊断齿轮箱的运行状态。
关键词:齿轮箱、故障诊断、特征统计值、相关性分析、机器学习
随着科学技术的提高,各种机械设备的出现,人们对机械设备的管理与维护有着日益迫切的需求。优质的机械维护不仅能降低企业运行的成本,更能提高机械的生产效率,因此为保障机械的安全与长久运行,企业也愈发重视对设备运行的监测。在大型的旋转机械设备中,齿轮箱的应用十分频繁,在汽车、风机等中都屡见不鲜,但也极易损坏。利用加速度传感器采集到的振动信号,然后根据振动信号进行分析,得出其是否故障或处于何种故障状态。如何对振动信号的进行科学分析也自然成为备受关注的一大问题。
一、基于振动信号的主要特征统计值的故障检测模型
首先,我们通过安装在正常运行的齿轮箱的四个不同部位的加速度传感器,采集正常状态下齿轮箱的振动信号。对于出现不同故障的齿轮箱,我们同样采用安装加速度传感器的方式,采集各种故障状态下的振动信号数据。
当我们通过加速度传感器得到了大量振动信号后,可先对原始数据进行可视化处理(画出正态分布图像),直接观察正常状态下与不同故障状态下的振动信号的差异。为了进一步的分析差异与规律,可计算出各组数据的主要统计特征值,并绘制正常状态下与不同故障状态下振动信号的平均值、峰值、峰度、偏度的折线图来呈现差异。通过分析各项特征统计值的差异大小,最终确定用来描述差异的特征值。
但是由于传感器的振动信号数据庞大且无序,直接观察原始数据计算得到的统计特征值难以判断齿轮箱是否处于故障状态,故需要对原始数据进行一定的处理。此处,引入偏离系数Q来描述故障状态下主要统计特征值与正常状态下的差异。
![]()
**其中Yi为故障i状态下特征统计值数值,X为正常状态下特征统计值数值
前文中,我们已经通过原始数据的正态分布图像得到了差异最为明显的特征值,故在此模型中,可优先使用此特征值进行计算偏离系数Q。若仅通过此特征值的偏离系数无法得出结论,则可利用其他统计特征值的偏离系数进行补充。根据样本数据,我们可以确定正常状态下偏离系数Q的区间,并排除由实验误差引起的振动信号差异。最后我们将当偏离系数Q落在区间以外时,可判断该齿轮箱处于故障状态。
运用此模型,我们可以较为直观的判断齿轮箱是否处于故障状态,但是由于该模型的数据敏感性较低,我们难以判断齿轮箱处于何种故障状态。要想判断故障类型,还需对收集到的振动信号做进一步的分析。
二、基于机器学习的故障诊断模型
集成学习算法是在众多机器学习算法成熟后提出的,他是由多种机器学习算法以一定的方法组装而成的集成模型,可以综合各类算法的优点,博采众长,同时也避免了只使用一种算法所带来的准确性与精准性上的弊端,是一种模型优化的良好手段。集成算法常是先单独对每个模型进行训练,然后综合结合这些模型的结果,最后得到一个总体的更具可靠性的预测结果。引入集成学习算法作为齿轮箱振动信号故障状态分类检测的分类器,可以用来改善基本机器学习的泛化能力,提高算法检测的稳定性。本文采取基于DT,XGBoost,RF,GBDT,LightGBM的集成模型对齿轮箱的故障状态进行检测分类。
1.DT(Decision Tree),决策树算法建立在已知各种情况发生的概率前提下,通过建立分支结构来计算期望值大于或等于零的概率。[2]决策树算法按照一定的特征将源数据划分到不同的分支结点,并且最大可能的保证分支结点所包含的样本属于同一类别,从而进行优化分类。
2.GBDT(Gradient Boosting Decision Tree),梯度提升决策树。它是由多个CART回归树集成得到的,而CART树是决策树的其中一种,其用模型在数据上的负梯度作为残差的近似值从而拟合残差。基于传统的Boosting算法的迭代,其每次迭代都建立在上一轮迭代的损失函数的残差上,损失函数越小则说明该模型训练的越充分。
在GBDT多分类算法中,使用softmax的损失函数:
| (1.) |
于是会得到其中的每一类的概率值:
| (2.) |
在生成CART回归树的时候要对每一类都要生成一棵树![]()
其中叶子节点的预测值为:
| (3.) |
3.XGBoost(Extreme Gradient Boosting),其基分类器是CART回归树,同样和GBDT一样是拟合的在数据上的残差,但它是用泰勒展开式对模型损失残差的近似,并且加入了模型复杂度的正则项,其性能在GBDT上有了进一步的提升。
假设已经训练了K棵树,对于第i个样本的预测值为
| (4.) |
**其中![]() 为样本特征,
为样本特征,![]() 表示第
表示第![]() 棵树对样本
棵树对样本![]() 的预测结果。
的预测结果。
经过优化后得到损失函数:
| (5.) |
再将其套入泰勒展开式:
| (6.) |
其经优化后可得到:
| (7.) |
![]() 和
和![]() 是已知的,若要优化函数,则要将
是已知的,若要优化函数,则要将![]() 、
、![]() 参数化。
参数化。
又定义树的复杂度,用叶节点个数和节点值计算:
| (8.) |
**其中![]() 表示树结构中叶子的数量
表示树结构中叶子的数量
最终可以再优化得:
| (9.) |
当前树结构下的最佳的目标函数值为:
| (10.) |
当我们的知道了训练第![]() 棵树时最小的目标函数值
棵树时最小的目标函数值![]() 后,随意给出一颗树(已知树结构),就能算出该棵树下最小的目标函数值。
后,随意给出一颗树(已知树结构),就能算出该棵树下最小的目标函数值。
4.RF(Random Forest),随机森林是利用多棵决策树对样本进行训练并预测的一种分类器。随机森林具有泛化能力强、训练速度快等特点,同时随机森林还具有样本随机性以及特征选取随机性,降低了每一棵决策树的相关性,保证随机森林的分类能力。构建随机森林的步骤如下:
(1)首先对给定的训练特征集F进行有放回的随机抽样,形成子训练集,即θ;
(2)子训练集θ一共有M个属性特征,在决策树的每个节点需要分裂时,从中任意选出m个特征做为候选的分裂属性特征;
(3)计算所选m个特征的信息增益,并将其中增益最大作为分裂特征属性;
(4)每个节点都按照上面步骤进行分裂,直到生成的决策树可以准确地将训练特征集F中的样本进行分类,或者用完所有属性特征;
(4)重复上述步骤,建立大量决策树并组成随机森林模型。
5.LightGBM,该模型属于集成学习中的Boosting方法。相比于GBDT算法,他进行了进一步的优化,能够在保证准确度的同时,有更高的效率和更快的运算速度,并且能够降低内存占用。
通过将收集到的振动信号数据进行划分采样,得到机器学习算法的训练数据与测试数据。将测试数据分别送入不同算法所构建的分类器中进行测试,采用准确率、精确率、召回率以及 F1 得分对多分类算法进行评估。由此得到最合适的算法,再将未知故障的振动数据处理后进行故障诊断,判断其故障类型。
三、结语
本文所建立的齿轮箱故障诊断与判断模型均具有易操作、易学习的特点,其中基于集成学习算法的故障诊断模型准确率高且处理速度快,对于机器故障判断及分类等相关研究工作具有一定的参考价值。同时由于齿轮箱正常工况下振动信号数据样本量过少,模型也存在一定的局限性,如基于主要特征统计值的故障检测模型的普适性有待进一步探究、基于集成学习算法的故障诊断模型可能存在过拟合现象等等。
参考文献
[1]苏德.基于Markov过程的风电机组预防性维护与可靠性研究.2021.兰州交通大学,MA thesis.
[2]闫云凤.基于决策森林的回归模型方法研究及应用[D].导师:齐冬莲.浙江大学,2019.
[3]郭文勇.改进CatBoost算法在不平衡分类问题的应用研究[D].导师:巩红禹.内蒙古财经大学,2021.
[4]马丽英,张洪杰,罗天洪,郑讯佳.基于LMD-CSP和随机森林的运动想象脑电信号分类[J].传感技术学报,2021,(09):1189-1195.

客服QQ:30444492琼网文【2021】1550-113号
增值电信业务经营许可证:琼B2-20210322
出版物经营许可证:新出发龙华出字第(2021)009号
广播电视节目制作经营许可证:(琼)字第00779号
版权所有 ©2002-2024 期刊网(www.qikanchina.com) 琼ICP备2021005105号