山东协和学院 山东济南 250107
摘要:本文利用Excel对给出的药材红外光谱数据进行预处理,通过图表寻找近、中红外光谱中不同药材的特征和差异性;利用Spss软件通过聚类分析进一步对药材种类和产地进行鉴别和分类;通过相关性分析、欧式距离,研究光谱与产地的相关联系。具体分析如下:
针对问题一:首先,利用Excel对附件1中几种药材的中红外光谱数据进行初步处理并做折线图,将其按照光谱特征初步分成3组,研究其特征与差异性,经过分析得知不同种类的药材呈现的光谱特征,在波数范围和吸收倍率两方面差别都比较明显。然后,利用Spss软件对数据采用K-means聚类分析算法进行出来,经分析研究,最后将药材分为4大类。
针对问题二:首先,使用Excel对附件2中给出的数据按药材产地进行筛选,并分别选取相同产地和不同产地的数据进行做图,比较分析得出产地相同和不同时药材的特征和差异性。然后,使用Spss软件的系统聚类分析算法将药材产地初步分类得出K值,随后利用K-means聚类分析算法继续分类,对聚类效果好的产地直接分离,聚类效果不明显的产地继续利用相关性分析进行筛选,并对结果进行检验,最终鉴别出未知药材所属得产地,具体结果见表4。
针对问题三:首先,使用Excel对附件3中给出的两组数据按照产地编号进行排序处理,并将相同产地的数据分组求取平均值,将求得的平均值与未知数据项一起建立到新表格当中。然后,运用欧式距离分别求取每个未知项与各已知产地的距离,做成图表,通过分析寻找出未知数据与已知产地中最短距离。最后,将建立好的中、近红外欧式距离关系图放在一起进行对比,按照最小值进行最后产地的鉴别,具体结果见表11。
针对问题四:首先,将附件4中药材数据根据种类进行筛选,利用Spss软件进行聚类分析可得出A、B两类数据,A类数据特点明显,容易辨别;B类数据较为混乱,不易辨别。然后,将B类数据单独进行欧式距离求解,解得B类数据中包含C类数据,所以需要分析的药材数据中一共有三种类别。最后,产地的鉴别思路参照问题三,具体结果见表15。
关键词:K-means聚类分析,相关性分析,系统聚类分析,欧氏距离,Spss
一、问题重述
1.1问题背景
红外光谱技术[1]是运用化学领域的相关知识,在原有的光谱测量基础之上结合产生的一种新型技术。其原理主要是用红外光线捕捉原子不同的振动的状态和相关的吸收频率实现分析和检测,这种技术的优点在于:简单、方便、分辨率高等。
1.2问题的提出
1.通过研究附件1中的不同药材的中红外光谱数据,分析总结出来不同种类药材的特征和差异,并且根据不同种类药材特征,鉴别出不同药材的种类。
2.通过分析附件2中给出的某种药材的中红外光谱数据,判断总结出不同产地药材的特征和差异性,尝试鉴别这些药材分别的产地,并将得出的结果进行分析。
3.通过对附件3的某种药材近、中红外光谱数据的综合分析,鉴别出该种药材的产地,并对鉴定结果进行分析。
4.通过对附件4给出的几种药材的近红外光谱数据,鉴别这几种药材的类别和产地,并结合分析的结果,对应图中编号将类别和产地结果填入表中。
二、问题分析
本文的研究对象是若干中药材的红外光谱数据,研究内容是不同药材对近、中红外光线的吸光度特征。根据特征进行分析,使其能够鉴别不同中药材的道地性。主要目的是针对传统的中药材鉴别方法进行优化升级,达到中药鉴别领域的技术革新,使得中药鉴别的过程和结果实现便捷、高效、准确等优点。
问题一分析:首先对附件1中给出的中红外光谱数据进行预处理,利用Excel中的工具筛选出我们所需要的数据,然后将具有错误的数据和与题干无关的数据进行分类剔除,最后采用K均值聚类分析法将剔除后的数据进行聚类,对比聚类后各个群体的特征、规律,总结出不同种类药材的特征和差异性,并鉴别药材的种类。
问题二分析:对附件2中给出的中红外光谱数据进行数据预处理,利用Excel将数据排序成有利于聚类分析的形式,再挑选出部分产地进行图表分析,分析出特点和差异性,再计算出各个产地的平均值,利用平均值与未知产地的数据做聚类分析,最后利用相关性判断产地,完成填表。
问题三分析:首先对附件3进行数据清洗、预处理,先将近、中红外数据分开,单独对近红外和中红外数据进行分类,方法如下:用SPSS软件进行系统聚类分析,先将近红外数据分类出一部分,再对难以分类的部分用欧式距离细致划分,中红外数据同理,则对近红外以及中红外的数据初步分类完毕。对比发现仅有编号为170的药材在近红外和中红外的数据中,都被分为第9产地。其它编号药材分类均不同,因此,通过近、中红外的光谱数据进行相互验证,以此来对中药材的产地综合鉴别。
问题四分析:首先对附件4中数据进行预处理,将数据按照药材种类排序,然后进行取平均,将平均值与所求数据作图分析,发现其中一类药材特点明显,但是其他两类数据较为混乱,难以辨别。因此利用SPSS软件将上述数据进行系统聚类分析,结果与作图分析结果一致。针对两类难以辨别的数据,采用分类更为细致的欧氏距离进行分类,得出种类的划分。最后对产地进行分类,将数据按照产地进行分类求平均,每种产地各一条,共得到16条产地平均数据。先采用系统聚类进行分类发现,分类的结果误差较大,因此对于产地的分类,依旧采用欧式距离的方法进行求解。
三、基本假设
1. 假设附件中的红外光谱数据已进行了初次处理,如基线矫正、平滑处理。
2. 假设针对误差较大,难以鉴别的药材,仍可通过细微差别进行区分。
3. 假设附件中产地与种类的数量即使附件中所给出的数量。
四、符号定义
符号 | 说明 |
r | 相关系数 |
d x y | 欧式距离 已知产地/种类吸光度 未知产地/种类吸光度 |
五、模型的建立与求解
5.1不同种类的药材中红外光谱的研究分析
5.1.1数据预处理
对附件一的数据进行深入的挖掘和分析,具体分为以下三个步骤:
(1)数据的排序。将附件1中的数据按照降序进行排列,目的是为了让数
值相差不大的各项数据排列在一起,方便后期的处理和聚类分析。
(2)数据的编号。对附件1排序后的数据进行重新编号(编号见支撑材料),并在后续的论述当中,沿用重新编制后的编号。
(3)数据的剔除。对附件1中的数据用Excel作折线图,如图1:
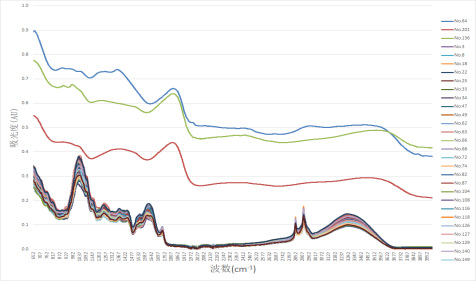
图1 异常数据对比图
由图1可以看出编号为64、136、201(未重新编号)的数据与其他数据差异明显,因此判断这三行数据为异常数据,故做剔除处理。
5.1.2不同种类药材特征和差异性分析
将附件一中数据按照从大到小的规律排列,按吸光度数据大小分为三组。利用Excel作折线图,通过初步的排序、作图、分析得出三种不同类型的药材中红外光谱曲线图,具体情况如图2:

图2 不同分组的药材光谱图
据图2分析:
4-209编号的药材,在1044cm-1—1772cm-1波段,药材的原子活跃性大幅下降,在932cm-1—1212cm-1波段活跃性最高;在1772cm-1—2836cm-1 波段活跃性一直趋于低迷状态。因此,该类药材活跃主要在652cm-1—1660cm-1波段区间,1772cm-1—2836cm-1区间活跃性不高,据此判断4—209编号的药材原子性质较为稳定,在各个波段的数据差距不大。
210-286编号的药材,在652 cm-1—1744 cm-1区间较为活跃,吸光度起伏较大,为活跃区间。在1744 cm-1—3928 cm-1区间持续低迷,吸光性积极性不高,为不活跃区间。该类药材活跃主要在652 cm-1—1744 cm-1波段区间,1744 cm-1—3928 cm-1区间活跃性不高。其吸光度与特征与前面几种类型均不同,其图像较为稳定,在各个波段的数据差距不大,因此的吸光性较其他几组稳定。
287-424编号的药材,在962 cm-1—1582 cm-1区间和2822 cm-1—3318 cm-1活跃,吸光性相对其他波段较高,在1706 cm-1—2636 cm-1区间吸光性积极性较低,为不活跃区间。该药材活跃主要在962 cm-1—1582 cm-1区间和2822 cm-1—3318 cm-1区间,1706 cm-1—2636 cm-1区间活跃性不高。总的说此组药材吸光能力较低,且在短波段原子变化状态异常激烈,但在后面的波段中原子的变化趋于平缓,不在出现变化剧烈的情况。
综上所述:经过分析,不同的中药材的中红外光谱中的波形具有较大的差异,但是它们积极吸光的现象都集中出现在某一波段,根据图像特点和差异性分析,三段数据给出的图像主要差距在2400 cm-1—3300 cm-1波段,有一组在此波段吸光最激烈,其他几段在不同的波段表现并无太大差异。
5.1.3用K-均值聚类分析法对药材进行分类
对附件1中的数据进行挖掘,根据图2展示的各组图像的特点,初步预测该数据大致可以分为三类。现利用SPSS软件,对附件1中的数据采用K-均值聚类分析法进行聚类分析,进一步进行检验,重复进行多次聚类分析,发现该数据包含不止三类药材,所以重新进行预测,在经过多次检验后,最终确定该数据可以分为四大类药材分别命名A、B、C、D一共四类。具体分析过程如下:
1. K-means聚类分析算法流程图
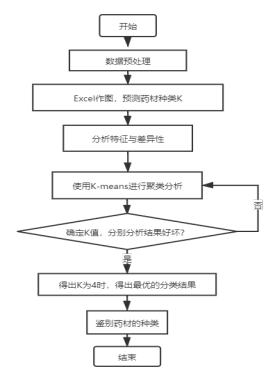
图3 K-means算法流程图
2. K-means聚类分析法的具体步骤
本题聚类分析算法的具体原理步骤为:
(1)在样本中任意挑选一个作为开始的第一个聚类中心;
(2)根据选出的聚类中心开始计算样本与中心的直线距离,若样本离临近的聚类中心越远,则被选为下一个聚类中心的可能性就越大;最后,依据概率的大小选出下一个聚类中心;
(3)将第(2)步重复多次,直到选出了K个聚类中心。然后再挑选出初始点就可以进行K-均值聚类算法。
3. 聚类分析结果分析
通过采用K-means聚类分析法进行聚类分析,得出如下图4
![C:\Users\Admin\Documents\Tencent Files\1462430487\Image\Group2\A$\JL\A$JL9LNK_%K}LA%]TOAGQID.jpg](/convert/2023-06-28/file_168795899551529797.004.jpeg)
图4 数据聚类分析图
根据图4显示,A类药材中包含63个数据,具体特征为:该类药材在652 cm-1—964cm-1区间内吸光度下降明显,在此波段内药材B的原子活动不如两边的波段频繁,在总趋势上仍然吸光度较高。在波段1042 cm-1—1198 cm-1内药材B的吸光度达到顶峰,此时药材B对红外光的吸收率最高。在波段1744 cm
-1—2758 cm-1内,药材B对红外光的吸收趋近于0,原子在此波段基本不吸收红外光线,这种现象在波段3616 cm-1—3928 cm-1再次出现。
B类药材中包含66个数据,具体特征为:在882 cm-1—1158cm-1区间内吸光度大幅度上升,在此波段内药材的原子活动最频繁,在总趋势上看吸光度最高。在波段1204 cm-1—1526 cm-1内药材的吸光度总趋势是在下降的,但有个别变量在这个波段吸光度异常,经分析、推断有其他因素影响,导致部分药材在此阶段异常。在波段1756 cm-1—2860 cm-1内,药材对红外光的吸收趋近于0,原子在此波段基本不吸收红外光线,这种现象在波段3642 cm-1—3964 cm-1再次出现。
C类药材中包含134个数据,具体特征为:在939 cm-1—1185cm-1区间内吸光度大幅度上升,在此波段内药材的原子活动最频繁。在波段1226 cm-1—1677cm-1内药材的吸光度变化剧烈,时高时低的现象较为明显,据此分析药材在此区间原子活跃性大,导致变化剧烈。在波段2825 cm-1—3645 cm-1内,药材D的吸光性又一次迎来高峰,区别于其他几种药材在此波段的变化规律,据此分析,药材在此区间仍具有较强的吸光性。
D类药材中包含83个数据,具体特征为:药材在652 cm-1—862cm-1区间内吸光度下降明显,在此波段内药材的原子活动不如两边的波段频繁。在波段904cm-1—1072 cm-1内药材的吸光度达到顶峰,此时药材对红外光的吸收率最高达到0.45。在波段1744 cm-1—2794cm-1内,药材对红外光的吸收趋近于0,原子在此波段基本不吸收红外光线,这种现象在波段3676 cm-1—3970 cm-1再次出现,且药材在2836 cm-1—3634 cm-1区间内,再次出现光吸收现象。
5.1.4方法检验分析
采用K-均值聚类分析方法对数据进行鉴别分类,得出不同种类的中药材的中红外光谱中的波形具有很强的相似性,与通过对比发现,得到的结果基本一致,证明该方法在鉴别过程中,使用恰当。
5.2同种药材不同产地的中红外光谱研究分析
5.2.1 不同产地药材的特征和差异性分析
首先利用Excel对附件2的数据按照产地分类进行排列,把相同产地的药材按产地分别进行分析。然后,选取相同产地的药材作图分析,以产地1为例,任意提取四种产地1的药材数据作图,具体特征如图5;
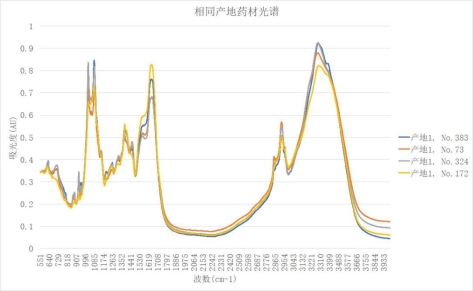
图5 相同产地药材光谱
选取不同产地的药材作图分析,以产地2、3、4、5为例,任意提取四种产地中的一种药材数据作图,具体特征如图6;
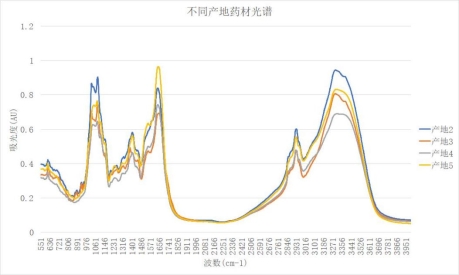
图6 不同产地药材光谱
结果分析:
据图5分析,同一产地之间药材的光谱折线紧密贴合,吸光活跃的波段趋于一致,都在996 cm-1—1619 cm-1和2865 cm-1—3310 cm-1区间出现峰值,主要差异表现在吸光度的倍率方面,但据图所示的吸光度,表现的差异性并不大吸光度倍率差距最大值也在0.1之内。
据图6分析,不同产地之间同种药材的光谱折线变化趋势在不同的波段基本一致,峰值都出现在976 cm-1—1656 cm-1和2846 cm-1—3356 cm-1区间,其主要差异表现在吸光度的不同,吸光度强的药材,峰值倍率趋近于1;吸光度弱的药材,峰值倍率趋近于0.6,不同产地的同种药材在吸光波段上并无差异,主要差异表现在峰值的最高吸光度方面。
综上所述,同种产地的药材与不同产地的药材在吸光波段的变化上并无太大差异,基本趋于一致,不同点在于相同产地的同种药材在峰值吸光倍率方面差异较小,但不同产地的同种药材在峰值吸光倍率方面差异较大,结合题目给出信息推断,不同产地间由于无机元素的化学成分、有机物等存在差异,因此其原子在吸光度上表现不同。
5.2.2 基于系统聚类算法的中药材产地的鉴别
1.系统聚类分析算法流程图
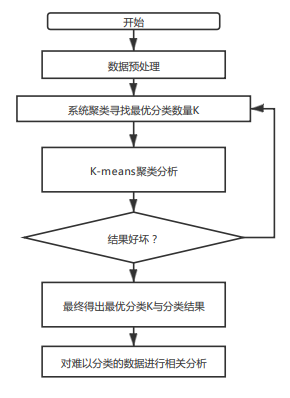
图7 系统聚类算法流程图
2.药材产地的分类
对附件2中数据进行挖掘,采用系统聚类算法对数据进行统计处理,具体处理步骤如下:
第一步:利用Excel对附件2的数据进行预处理:首先,将附件2中的数据进行分类,对其进行排序筛选,相同产地的数据为一类。然后,对相同产地的各列数据取平均值,将各产地的多条数据整合成一条数据,便于分析。最后,用相同的方法对其他产地的数据进行均值处理。
第二步:利用Spss将步骤1中的数据进行系统聚类,得到聚类谱系如图8,同时得到聚合系数如表1。
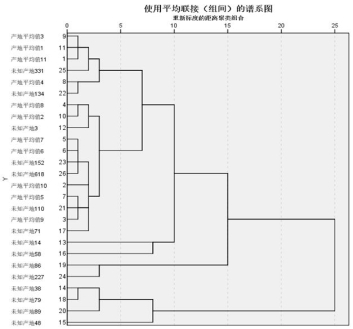
图8 聚类谱系图
表1 聚合系数
![C:\Users\Admin\Documents\Tencent Files\1462430487\Image\Group2\[1\]F\[1]FO5NQOC1N51YXWUDZ1Q5.jpg](/convert/2023-06-28/file_168795899551529797.009.jpeg)
第三步:根据肘部法则找到最优分类节点数K。将聚类系数单列到Excel表格中,并按照降序排列,做出聚合系数折线图,如图9

图9 聚合系数折线图
对聚合系数折线图进行分析可知,当类别数K为5时斜率骤变,折线的下降趋势趋缓,故可将类别数设定为5。
第四步:利用K-means算法做出聚类结果。根据聚合系数计算的K值,将所有产地分成五份。如表2 :
表2 聚类结果
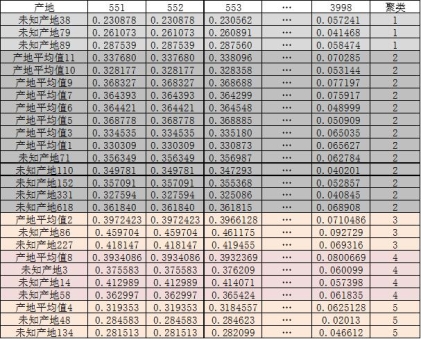
由表2的聚类结果可以看出:聚类为1的数据所属,都是未知产地的数据,没有已知产地作对比,因此难以区分产地所属;聚类为2的数据中所含已知产地过多、误差较大,难以分辨; 在聚类为3、4、5的数据中,都仅有一个已知产地,因此在该聚类中的其他未知产地都可归属为一类产地。如聚类3中包含已知产地2,其余两个编号为86和227的未知产地,均可归属为同一类产地。
第五步:利用Excel对聚类1、2数据进行相关性分析。以下为相关系数计算公式:
 。
。
因为第三步聚类结果中,聚类1、2难以分类,因此将该部分数据重复第二步的系统聚类分析,发现依然难以分类。并且,聚类1、2中的未知产地光谱比较接近,使得光谱鉴别的误差较大因此,此种情况聚类分析结果不理想。
若想对该部分的未知产地进行分类,在误差较大的情况下, 对该部分数据;利用Excel中的CORREL函数进行相关性分析,对其中细微差别进行计算,找到差别较小的数据,归为一类。得出相关系数如表3:
表3 未知产地与已知产地的相关性

据表3分析,通过分析未知产地与已知产地之间的相关系数,在已知条件:相关系数越大,两地的数值越相似,相关度越高。因此,需要找出未知产地中与已知产地相关系数最大的一项,并以此为依据进行分类。如38号未知产地,与其相关性最高也就是相关系数最大的是第5产地,因此判断38号未知产地与第五产地是同一个产地。
综上所述,在仅有中红外数据的情况下,所有产地的光谱比较接近,因此难以区分未知产地具体所属,所以通过聚类分析,先分析出一部分未知产地与已知产地相似度极高的类别,这部分类别误差较小。剩余数据误差较大,难以分析,只能使用相关系数寻找细微差别进行分类。
鉴别结果如表4:
表4 未知药材产地鉴别结果
![]()
3.结果检验
利用means方法在SPSS软件上对分类结果进行检验,因为空间问题,选取部分波长,具体情况如表5:
表5 聚类结果检验
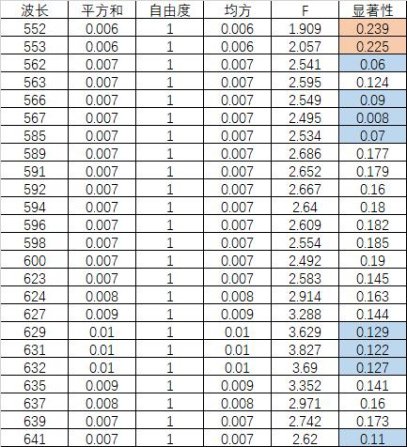
综上所述,表5是对平均数差异的表现,显著性这一列表明除了552、553其他的指标都比较显著。
5.3 利用欧氏距离对药材产地进行鉴别
5.3.1 问题解决流程图
图10 问题解决流程图
5.3.2 问题解决具体步骤
1.数据预处理
首先,利用Excel将附件3中的两种光谱数据按照产地分别进行排序,将排序后的数据按照产地分组并求出每组产地的平均值,具体如表6 、表7。然后将每组产地的平均值与未知产地的数据单独列成新的表格。
表6 近红外产地吸光度平均值

表7 中红外产地吸光度平均值

2.基于欧氏距离的产地鉴别过程
(1)欧氏距离:
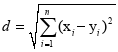 (1)
(1)
其中d为未知产地光谱与平均光谱吸收度值的距离,其中xi,yi 分别为未知产地光谱与平均光谱吸收度对应的数值,![]() 。
。
(2)近红外光谱的鉴别
利用欧氏距离对未知产地分别与每组产地的近红外光谱的数据平均值进行计算,计算结果最小的即为与未知数据最接近的产地,计算结果如表8:
表8 未知产地4与各已知产地的欧氏距离表

从表8可得未知产地4与已知产地11欧氏距离最小,因此在近红外光谱中判断,未知产地4与已知产地11是一类,将这两项数据分离到新表格中。
同理,将其余几个未知产地都进行分类,最终得出下表:
表9 近红外光欧氏距离表

据表9分析得,在近红外中所有未知产地对应的已知产地。如编号4的药材,对应11产地,其余未知产地以此类推。
(3)中红外光谱的鉴别
同理,用欧氏距离对未知产地分别与每组产地的中红外光谱的数据平均值进行计算,计算结果如表10:
表10中红外光欧氏距离表
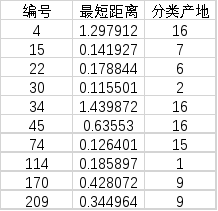
据表10分析得,在中红外中所有未知产地对应的已知产地。如编号4的药材,对应16产地,其余未知产地以此类推。
(4)两种情况下综合分析
经过对比表8和表9研究发现,部分相同编号的未知产地在两种情况下对应的已知分类不同,例如编号4的未知区域两种情况下分别对应已知产地11与16,本文采取就近原则,选择两者中距离较小者作为最终鉴别标准,所以编号4对应的分类产地为11产地。同理,将剩余未知区域进行最终确认,结果如下表11:
表11 两种情况下的产地鉴别结果
![]()
5.4利用欧氏距离鉴别不同药材
1.数据预处理
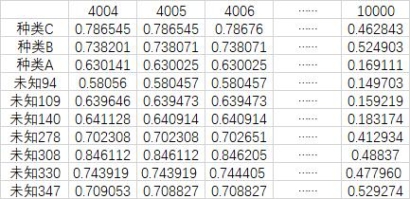
首先将附件4中需要分析的药材数据根据种类区别出来,针对不同部分的药材数据求取平均值,将平均值与要求的数据一起放在独立的表格当中,如表12。
表12 平均值与未知产地数据表
2.用系统聚类分析三类数据
据表12可得,一共有A、B、C三类数据,利用SPSS软件使用谱系图进行分析,尝试将数据按照A、B、C分类,截图如图11:
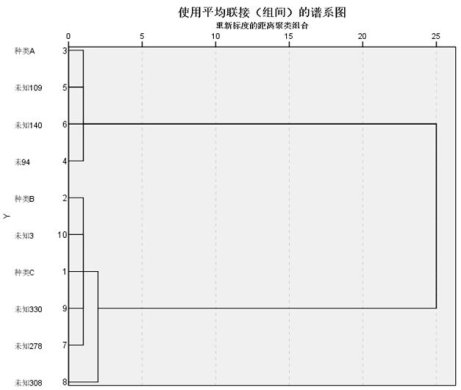
图11 系统聚类谱系图
如图11所示,第一次分类就已经分出了A类数据,但B、C两类数据仍然混乱,难以区分,因此需要使用其他方式区分B、C两类数据,例如欧式距离法。
3. 运用欧式距离法区分数据
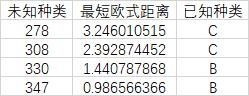
因为使用谱系图仍然无法区分B、C两类数据,因此需要使用更为精确到欧式距离法进行区分,利用欧氏距离对未知种类分别与每组种类的近红外光谱的数据平均值进行计算,取与位置产地距离最小的已知种类,结果如表13:
表13 欧氏距离分种类
接下来对产地进行分类,将数据按照产地进行分类求平均,每种产地各一条,共得到16条产地平均数据。先采用系统聚类进行分类发现,分类的结果误差较大,因此对于产地的分类,依旧采用欧式距离的方法进行求解,结果如表14。
表14 欧氏距离分产地
![C:\Users\Admin\Documents\Tencent Files\1462430487\Image\Group2\LR\]$\LR]$}66Q8$I%L3]PH2GQH3N.jpg](/convert/2023-06-28/file_168795899551529797.028.jpeg)
分析归类后将剩余未知区域进行最终确认,完成最终结果,如表15:
表15 最终结果
![C:\Users\Admin\Documents\Tencent Files\1462430487\Image\Group2\VL\[1\VL[1TLW]JM{TW5C{9EOX}J6.jpg](/convert/2023-06-28/file_168795899551529797.029.jpeg)
六、模型的评价与推广
6.1模型的评价
1.模型优点
(1)对数据进行多种分析方式,采用其中变化明显的数据,是本次问题研究分析中的亮点,主要是为了将问题化繁为简。
(2)通过此模型得到的结果,可以通过联系全文不同结果去分析、反复推敲,以此验证模型是否可行。
2.模型缺点
模型的建立并不全面,误差相对较大,单一的处理方式并不能对问题进行多方面的比较分析,因此不能对模型进行更好的优化处理。
6.2模型的推广
通过聚类分析、相关分析、欧式距离的求解方法,针对相似性极高的数据进行区分,适用于生活中,如假币的鉴别等。
[参考文献]
[1]刘沭华,张学工,张素琴.中药材产地的近红外光谱自动鉴别和特征谱段选择
[J].2005.50(04):393-398.
[2]朱乐.基于近红外和中红外光谱的细菌分类与浓度检测研究[D].2020.6:17-38.
[3]岑忠用,雷顺新,严军,张晖英.近红外光谱法鉴别6种根茎类中药材
作者简介:尚安琦(2004.9—),女,汉族,山东省泰安市人,本科在读,研究方向:K-means聚类系统分析建模分析。
1

客服QQ:30444492琼网文【2021】1550-113号
增值电信业务经营许可证:琼B2-20210322
出版物经营许可证:新出发龙华出字第(2021)009号
广播电视节目制作经营许可证:(琼)字第00779号
版权所有 ©2002-2024 期刊网(www.qikanchina.com) 琼ICP备2021005105号



