联通在线信息科技有限公司
摘要
随着移动互联网的不断发展,数据爆炸式增长,数据存储的需求正发生急剧的变化,服务和存储逐步转向智能化、数据化演进,云盘、视频、人工智能所需的深度学习,模型训练等技术与业务的需求,对于存储和计算提出更高的要求,传统存储系统已经难以满足新形势下高性能、低延迟、可扩展、高可用、成本优化的需求,所以急需研发下一代高性能存储系统,以满足数据存储的需求。
基于对高性能存储系统国产化替代方案的研究,在业界没有成熟运营级方案实现可以采用的前提下,使用最新的国产化的NVMe存储和RDMA网络硬件,基于全新的软件栈,设计并实现一套高性能、低延迟、可扩展、高可用、成本优化的存储系统,并进行业务验证。
本文给出上述基于NVMe和RDMA的高性能存储系统的方案研究以及实现细节,给出验证性能,以及未来应用展望。
关键词:NVMe、RDMA、高性能存储、国产化
1.引言
传统企业客户的大型数据库应用,比如证劵交易、航空预定等,对高性能存储的要求还不是特别明显。但随着百行百业都在不断推进新业务,以及新基建建设的深入,AI、5G、物联网、大数据、区块链、自动驾驶、AR/VR等新兴技术与业务融合,百行百业的数据呈现出前所未有的丰富性、多样性,业务访问越来越呈现高密集I/O特征,因此各种云存储产品的各项性能指标也在逐步提升,而传统硬件,存储架构不具备满足更大规模下存储集群能力以及高性能访问要求,存在单盘IOPS低、吞吐低和延迟大的问题。
这种情况下,需要基于最新存储与网络硬件,研究新一代高性能存储系统,硬件上,需要研究NVMe存储、RDMA网卡等新技术的采用;软件上,需要研究基于NVMe存储、RDMA网卡的高性能I/O模型,研究全新的软件存储系统技术栈,研究相关系统层以及用户层的驱动等。
2.技术背景
2.1 硬件技术
1)高性能存储技术
根据工信部电信研究院的报告[1],如下表所示,当前社会正步入智能时代,云计算、物联网、大数据、人工智能、区块链等新技术快速演进,人脸识别、自动驾驶等智能新应用不断涌现,推动了数据爆炸式增长。数据存储主要有三大需求,分别是EB级容量、亿级IOPS和智能管理。
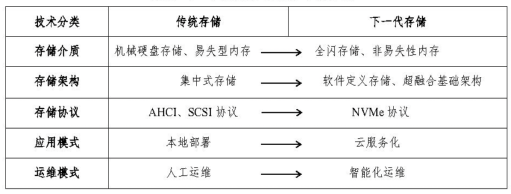
其中,亿级IOPS需求是推动存储革新的基础,必须在物理层面推动存储介质的变革才能满足性能要求。分析当前的技术现状以及趋势,全闪存储普遍被认为是存储行业的发展方向。
通常而言,全闪存阵列可以提供50到100万IOPS,延迟在1毫秒以下。但全闪存物理存储的采用,需要采用新的NVMe协议,以避开单队列模式AHCI协议。
在存储系统中,HDD磁盘以及早期SSD磁盘的传输协议一般采用AHCI(高级主机控制器接口,Advanced Host Controller Interface)。对于HDD这种慢速设备来说,传输速度主要受限于存储设备,而并非AHCI传输协议。
SSD盘的IO带宽越来越大,访问延时越来越低,AHCI协议已经不能满足高性能和低延时SSD的需求;而NVMe协议可以实现多队列同时操作,命令处理流程更为简单,且队列大小、深度更满足并发需要,可以充份利用SSD的硬件性能,实现高性能存储。
因此,需要采用SSD+NVMe的底层硬件,并在此之上进行系统驱动层面的研发定制,才能够实现新一代的高性能存储,并对外提供服务。
2)高性能网络技术
在单机实现了高性能存储后,如果要对外提供高性能存储的云服务,还需要实现网络层的高性能存储支撑。经典的数据中心,一般采用支持传统的TCP/IP协议的网络设备。而网络协议栈(如TCP/IP)不是针对高性能存储场景设计的,很难支持高性能存储对网络高性能访问要求。
远程直接内存访问(remote direct memory access,RDMA)技术是一种更快的网络通信协议[2],允许用户程序绕过操作系统内核,直接和网卡交互进行网络通信,从而提供高带宽和极小时延。并且RDMA网卡可以在没有远端节点帮助的情况下,由网卡直接发起和完成对远程内存的读写请求,通过Bypass CPU的方式,降低CPU使用率,提升性能。
再简单的阐述,RDMA理解为利用相关的硬件和网络技术,服务器1的网卡可以直接读写另一个服务器2的内存,最终达到高带宽,低延迟和低资源利用率的效果。
大致有三类RDMA网络,分别是Infiniband、RoCE、iWARP。其中,Infiniband是一种专为RDMA设计的网络,从硬件级别保证可靠传输,而RoCE和iWARP则都是基于以太网的RDMA技术,支持相应的verbs接口(RDMA的verbs接口一般支持单边方式通信和双边方式通信)。
RDMA 规范的前身 Infiniband 简称IB,起初用于高性能计算领域,需要使用专用的交换机、路由器等网络设备,部署维护成本高。最新的RDMA网卡已经可以达到200 GB的带宽,并且one-sided操作的时延可以低至600 ns。并且相关的RDMA网卡可以提供了新的NVMeoF(NVMe over fabrics)特性,使得RDMA可以直接操作固态存储设备[2]。
因此,在网络层,需要支持RDMA的最新一代网卡以及交换机,并在此之上进行系统驱动层面的研发定制,才能够实现新一代的高性能存储,并对外提供服务。
2.2 软件技术
1)UIO&VFIO
UIO( Userspace I/O) 是运行在用户空间的I/O 技术。Linux 系统中一般的驱动设备都是运行在内核空间,而在用户空间用应用程序调用即可。UIO 则是将驱动的很少一部分运行在内核空间,而在用户空间实现驱动的绝大多数功能。使用 UIO 可以避免设备 的驱动程序需要随着内核的更新而更新的问题。

图:UIO技术架构
UIO 的缺点在于用户态的虚拟地址无法直接用于做设备的 DMA 地址,在用户态无法知道 DMA内存的物理地址,这样限制了 UIO 的使用范围
VFIO是 Linux Kernel UIO 特性 的 升 级 版 本,VFIO 通 过 IOMMU 的能力来解决UIO的缺陷。IOMMU 可以为设备直接翻译虚拟地址,这样我们在提供虚拟地址给设备前,把地址映射提供给 VFIO,VFIO就可以为这个设备提供页表映射,从而实现用户程序的 DMA 操作。
现阶段,基于用户态的 NVMe 驱动有两种实现方案: SPDK和NVMeDirect。两种方案都是基于UIO 技术进行实现的。
2)SPDK
SPDK( Storage performance development kit )是本文中采用的方案,SPDK 是由Intel发起,用于使用 NVMe SSD 作为后端存储的应用软件加速库。该软件库的核心是实现了用户态、异步、无锁、轮询方式的 NVMe 驱动。
与传统Linux 内核的 NVMe 驱动相比,它可以大幅度降低 NVMe command 的延迟,同时提高单CPU的IO 处理能力 IOPS,从而形成一套高性价比的解决方案,例如使用 SPDK的vhost 解决方案可以应用于公有云中来加速虚拟机中的 NVMe I/O。
3)半虚拟化技术以及v-host
全虚拟化中,客户操作系统在hypervisor上运行,相当于运行于裸机一般。客户机不知道它在虚拟机还是物理机中运行,不需要修改操作系统就可以直接运行。与此相反的是,在半虚拟化中,客户机操作系统不仅能够知道其运行于虚拟机之上,也必须包含与hypervisor进行交互的代码。
virtio:设备和半虚拟化管理程序(Para virtualized Hypervisor)之间的一个抽象层。提供了一套上层应用与各 Hypervisor 虚拟化设备(KVM,Xen,VMware等)之间的通信框架和编程接口,减少跨平台所带来的兼容性问题,大大提高驱动程序开发效率(virtio之外,Xen、VMware Guest Tools也提供类似的支持)。
vhost:virtio后端设备用于具体响应Guest的命令请求。例如,对virtio-scsi设备来讲,该virtio后端负责SCSI命令的响应,QEMU负责模拟该PCI设备,把该SCSI命令响应的模块在QEMU进程之外实现的方案称为vhost。
vhost-kernel&vhost-user:在Linux内核中实现的vhost叫vhost-kernel,而在用户态实现的vhost叫作vhost-user。
3.研究思路
在业界没有开源实现的前提下,使用最新的存储和网络硬件,基于全新的软件栈,设计并实现一套高性能、低延迟、可扩展、高可用、成本优化的存储系统,完成整体自研存储架构的完整演进。根据前面的技术背景部分,需要考虑NVMe、RDMA等硬件技术,UIO&VFIO、SPDK、以及基于virtio/vhost等技术,在上述技术之上,架构实现高性能存储系统。
(1)采用最新的支持NVMe的SSD存储硬件和RDMA网络硬件,考虑到提高缓存性能,也需要采用nvdimm持久化内存设备。
(2)NVMe支持上,采用SPDK框架来与NVMe SSD交互,采用用户态驱动,多队列自适应Polling模式。在前端,采用私有的I/O协议+RDMA+用户态驱动方式来转发前端I/O请求到后端。
(3)驱动上采用vhost-user架构,即IO请求的生命周期完全bypass QEMU。
4.方案设计
4.1 方案概述
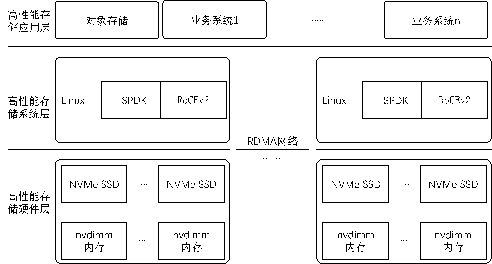
图:高性能存储系统架构
如上图所示:
硬件层:系统硬件层,采用了nvdimm以及NVMe SSD技术,并采用了RDMA网络技术,从硬件上保证存储的高性能。
系统层:采用了UIO技术的SPDK框架支持NVMe SSD高性能的发挥,采用RoCEv2技术栈,支持RDMA网络的高性能发挥。
应用层:应用层主要采用了联通云盘进行业务验证,也同时支持其他业务系统的使用和验证推广。
4.2 详细设计
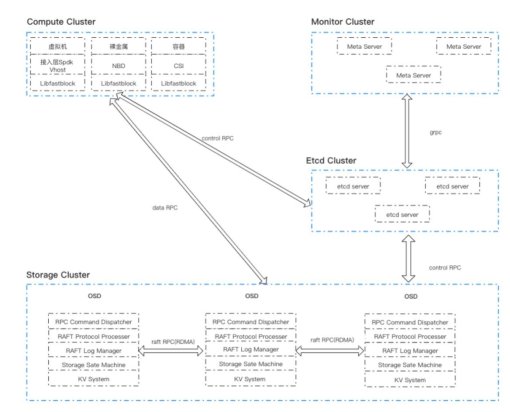
图:高性能存储详细架构
如上图所示,为高性能存储详细架构设计,其中
ComputeCluster对应计算服务;
Monitor集群负责维护集群元数据;
StorageCluster对应存储集群,每个存储节点中运行多台StorageNode,每个StorageNode上运行多个OSD(ObjectStorageDaemon);
EtcdCluster则是由多台etcdserver组成的元数据存储节点;
ControlRPC一般指元数据RPC,DataRPC则是数据RPC,而RaftRPC则特指osd进程之间运行的Raft论文中定义的RPC消息,这部分RPC是使用RDMA进行传输的;
RPCCommandDispatcher是RPC子系统的消息分发模块;
RAFTProtocolProcesser则重点是处理RAFTRPC消息、选举定时器超时等RAFT协议规定的内容;
RAFTLogManager则负责管理和持久化RAFTlog;
StorageStateMachine存储用户数据;
KVSystem则提供kvapi和事务API;

4.2.1集群元数据服务(Meta Server)
元数据服务负责维护存储节点状态和节点加入删除、存储卷的元数据,并维护集群的拓扑结构。Meta Server作为集群管理工具,并不需要存储海量数据,也不需要追求极致性能,所以使用Golang进行实现。
使用etcd已经在工程届有大量应用,可实现元数据的冗余存储,另外通过etcd的API实现快速的时间订阅和通知,让所有的存储节点能够快速影响集群变化。
将基于线性优化算法的partition均匀分配算法发布的etcd,所有的存储节点上的存储进程便会以此进行Raft Group的创建、删除和迁移。
另外,Meta Server的另外一项重要工作是均匀分布所有的Raft Group的leader,因为Raft Group的leader需要响应用户的读写请求,压力相对较大,所以需要通过人为控制的方式来影响Raft Group内部的选择,通过transfer leadership的方式来进行均衡。
4.2.2纯异步的RDMA实现
DMA(Direct Memory Access)即直接内存访问,允许在计算机主板上的设备直接把数据发送到内存中去,数据搬运不需要CPU的参与,随着技术的发展,目前已经实现了RDMA(Remote Direct Memory Access),这项技术的主要优点是:
1、零拷贝:应用程序能够直接执行数据传输,无需将数据复制到网络层;
2、内核旁路:可以直接在用户态执行数据传输,无需切换到内核态;
3、无需CPU干预:应用程序可以访问远程主机内存而不消耗远程主机中的任何CPU。
但是RDMA的用户态编程接口相当复杂,且涉及到2套语义,即同步语义的send/receive和异步的write/read。经过调研发现目前已经开源的RDMA都不是真正纯异步的RDMA语义,他们都是基于同步的send/receive语义进行实现的,这种同步的语义实际上并不具有最优的性能,因为本机和远端的send/receive之间存在阻塞的情况。
存储进程启动后,存储进程会attach到大小为1GB整数倍的shared memory上,这块shared memory将完全用于处理RDMA相关的IO。我们使用RDMAWrite传输对象的数据(这部分数据较大),使用的RDMA Send/Recv传输其他消息,这些其他消息包括用来同步对象传输状态的消息、用于初始化连接状态的元信息等(这部分消息一般都很小)。
每个存储进程在收到客户端的请求后,会用链表构造一个ring buffer,这个ring buffer包含数个chunk,即下图中绿色的圆角矩形。这个ring buffer在客户端里也有一个,两个ring buffer里的chunk一一对应。chunk里的head和tail均是1字节大小,取值只有0和255,如果head和tail既不是0也不是255,就代表没有存储进程使用这个chunk。head和tail是用来表示这块chunk上是否有RDMAWrite发生。存储进程在busy loop中不断检查head和tail的值,当head的值与原来的值不同时,表明有RDMAWrite操作再向chunk写数据,且这时候size已经写入完毕,接着根据size就可以确定tail的位置,当tail与head相等时,表示整个消息传输完毕。这时候就会从busy loop里出来。

4.2.3基于Seastar实现高吞吐、低延迟RPC系统
ceph中存在大量的线程,线程之间存在大量的切换,导致存在大量的CPU需求,另外单个IO的延迟也显著增大。一种简单的改进是使用基于reactor模型的单进程模式,这种模式下不会有线程间切换和TLBmiss,但是也面临这不能够充分利用目前的多核性能。
Seastar是scylladb开源的一个高性能C++事件驱动异步处理框架,它基于C++11/14/20的众多新feature,支持高并发和低延迟的异步编程,针对传统TCP栈处理开销大,开发了用户TCP栈或者支持DPDK;针对linuxIOschduler性能弱,开发了用户态的IOscheduler,自己管理IO请求和分配优先级,且绕过page cache,直接DMA传输;针对flush、compaction等后台任务占用过多IO带宽就发明workload conditioning机制,可简单理解为IO系统内部进行自动调优,使得对客户端请求时延不受过多影响,这使得Seastar成为了存储领域最领先的开源框架,基于Seastar开发的兼容Cassandra接口的scylladb性能是Cassandra的十倍,目前包括ceph也在往这个方向演进。
目前Seastar已经有了基于DPDK和TCP的用户态网络协议栈,但是这个协议栈还是没有充分利用RDMA带来的纯异步高吞吐低延迟的优势。我们计划基于Seastar开发RDMA stack,并基于这套RDMAstack来实现RPC系统。
4.2.4使用PMDK实现数据高速读写
非易失性内存的随机读写和顺序读写都非常快,在我们的系统中,既使用它充当日志盘,也将它当成大块内存用于存储SD(Storage Daemon)的大量元数据。
首先,对于4k的写,PMEM充当日志盘,将当用户的IO为4k的写请求时,写操作可以直接放到PMEM中,PMEM提供原子写操作,此时即可向客户端返回,此后再异步在NVMe SSD上分配空间,并写到NVMe SSD上。

其次,当用户的IO较大时,比如用户使用fio对高性能SSD云盘进行benchmark的时候,PMEM将会很快耗尽,因为PMEM价格昂贵,不可能在一台服务器上提供过大的PMEM,假设用户的云盘的写吞吐为3GB/s,用户跑1天就能够把全世界的PMEM全部耗尽。所以我们设计了IOSelector,它的目的是尽量减少大IO在PMEM上停留的时间。我们将大IO和小IO存放在两个队列上,并且大IO所在的队列优先级更高,后端开启的回刷线程会快速将PMEM中的大IO刷到NVMe SSD上,以便尽快将占用的PMEM释放出来;
再次,对于当用户的IO为4k的读请求时,可能这个IO还缓存在PMEM中,此时可以从PMEM中读取,否则需要从SSD中读取。
最后,因单台服务器配置的PMEM至少有1TB左右,所以很多元数据都可以存储在PMEM
之中,如对象列表、对象的元数据(对象名、大小、扩展属性等)列表、对象存储的位置(在NVMe SSD上的offset和length等)、部分热点对象的内容(相当于cache在PMEM中)、每个NVMe SSD的extentmap和freelist等。
4.2.5一致性算法选型
作为一种分布式存储,所有的数据都需要复制到多块磁盘上,实现多副本冗余,实现这种复制的算法基本分为两类,一类是朴素的primary/backup算法,一种是基于quorum的复制算法。
ceph的一致性算法是一种朴素的primary/backup复制算法,primaryosd所有的io复制请求都会一直等待所有backuposd的回应之后才能返回给客户端,如下图所示,需要收到Ack(4)和Ack(5)之后才能够回应Client一个Ack(6)。
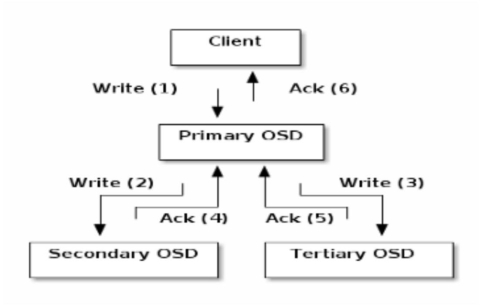
此一致性算法的主要缺点包括:首先,系统延迟取决于最慢的一个OSD,其次,当出现网络故障、服务器宕机等,IO会一直卡住直到,直到心跳机制发现这个OSD故障,心跳机制一般需要30秒才能发现这种故障,这造成的问题就是单个IO的最大延迟可以达到30秒,这在高性能块存储中是不能接受的,可以总结为这种复制算法的可用性较低。
另外一种是基于quorum的复制算法,paxos和Raft都是这类算法的代表。这种算法相比较而言可用性显著提高,因为单个节点故障的时候通常不会影响leader给client进行ack,因为这种方式只需要复制到多数个节点即可。
基于块存储对低延迟的追求,我们会使用Raft进行数据的复制。Raft带来的问题是Raft group过多时,每个Raft Group都会进行心跳,这就会造成整个系统中心跳包过多,所以需要对相同leader、flower的partion进行心跳的合并,如下图所示,有2个partition,在原有Raft Group的情况下,partition0的leader和partion1的leader需要分别向其follower发送heartbeat,而合并之后,只需要发送一个heartbeat即可。

4.2.6 Raft的设计协议与实现
Raft协议依赖其他组件,核心的是RPC子系统、kv子系统、Raftlog子系统、数据状态机子系统等。
Raft模块对外需要提供的是数据复制的接口,实现符合Raft论文的RPC及其消息处理。
4.2.7 kv子系统的设计和实现
kv子系统提供的接口就是下面的几个: start,stop,put,get,remove,empty,transactionalapi等;
4.2.8 log子系统:
log子系统即Raftlog子系统,是为Raft层实现log存储接口的子系统,Raftlog需要支持append、trim、read等接口,对于Raftlog而言,不需要提供随机写功能,只需要支持append,而trim则是因为当某个follower持有与leader的log不匹配的log时,需要将这部分log给trim掉,read则是读取Raftlog,在apply用户数据到数据状态机时,如果在内存中没有缓存,则需要从Raftlog中进行读取。
4.2.9 Raft数据状态机
Raft数据即用户的数据的集合,最理想的情况下,应该是所有的Raftlog都被apply到数据状态机之中(即所有的Raftlog都可以被trim而不丢失数据)。
根据Raft协议,数据首先进入Raftlog,等到多数成员commit到log之后才需要存储到状态机之中。Raft协议需要数据状态机能够支持snapshot,这是一个难点,原因在于,如果我们使用本地文件系统作为数据状态机的存储(即将一个文件系统目录作为一个数据状态机),通常我们使用的文件系统都是不支持快照的,这里除了使用btrfs等支持snapshot的文件系统之外,如果我们不使用文件系统来存储数据状态机(比如直接使用裸盘),则需要我们自行实现snapshot,这将会是一个挑战。
4.2.10客户端封装:
客户端需要跟etcd和storage cluster进行交互,其中通过etcd获取的是集群的元数据信息和集群运行状态,而通过storage cluster进行数据交互。因为Meta Server会将元数据发布到etcd,所以实际上客户端不需要直接与Meta Server进行交互。
5.系统实施
本系统实施基于国产化以及通用硬件进行研发以及验证实施,其中国产化硬件配置如下:
-2*7285 32C 2.0GHz 处理器
-12*32GB 2933MHz 紫光内存
-8*3.2TB NVME SSD硬盘(忆恒D926)
-2*Mellanox MCX4121A 双口 10/25GbE网卡(含两模块 RDMA)
-双电源
通用硬件配置如下:
-2*Intel Xeon Gold 6326 16C 185W 2.9GHz 处理器
-24*16GB TruDDR4 3200 MHz(2Rx8 1.2V)RDIMM内存
-4*256GB TruDDR4 3200MHz(1.2V)Intel Optane 永久内存NVDIMM
-8* P5600 3.2TB 混用 NVMe PCIe 4.0 x4 热插拔固态硬盘
-1*Mellanox ConnectX-6 Lx 10/25GbE SFP28 2 端口 以太网适配器(含模块 RDMA)
-双电源
之后在联通机房落地实施,实施环境如下:
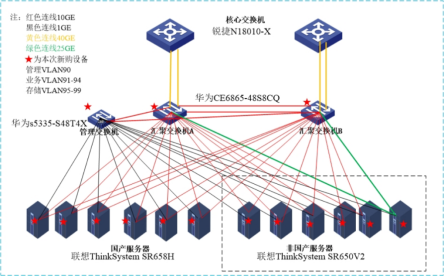
6.验证结果
目前各大存储厂商均推出了全闪存储产品,一般都给出了性能测试。如华为的OceanStorDorado、浪潮HF系列产品、电信的HBlock产品等。
以OceanStorDorado为例,相较传统机械存储,在存储性能委员会(SPC)的SPC-1基准下,业务性能提升了5倍;在数据库场景下,业务性能提升了10倍;在虚拟桌面场景下,在Word/PowerPoint/Excel应用测试中,启动响应时间缩短80%。
通过本次高性能存储系统的系统研究,利用相关工具进行了初步验证,在国产服务器上达到10万IOPS,通用服务器性能达到100万IOPS,详细信息如下:
(1)达到10万以及100万IOPS:在实验室环境下的通用服务器上,达到单云盘百万IOPS,毫秒内的延迟,单盘吞吐达到3GB。在国产设备上达到了单云盘的10万IOPS,延迟在5ms以内,单盘吞吐达到500MB。同时完成了对接QEMU挂载云盘的操作,支持多副本的读写功能。
(2)应用方面,系统初步在联通云盘、COPS平台语音存储、广东产互视频云等业务领域的研发测试区进行了对接探索,经过测试对于网盘的关键业务的读写,可以提升100%左右的读写性能。
7.总结以及展望
通过论文所述的高性能存储系统的开发,攻关了一系列工程上实现高性能存储系统的难点。包括但不限于:
(1)保证分布式存储数据副本的一致性的一致性算法与Raft Group的实现
(2)保证数据均匀的分布在不同磁盘节点上,纯异步的RDMA实现
(3)基于Seastar实现高吞吐,低延迟的RPC系统
(4)使用PMDK实现数据的高速读写
(5)在高性能存储上应用vhost和SPDK技术
(6)在网络云盘产品以及某省的业务系统中进行适当的测试验证等。
(7))实现了百万级别的IPOS操作,达到了业界第一梯队的性能指标。
后续基于本论文成果,根据高性能存储领域的业务需要,在技术上跟踪、持续引入并研发业界领先的高性能存储技术;在研发中重点围绕高性能存储系统的产品能力上下功夫,进一步提升产品的可靠性、可用性,在保证数据可靠性的同时提供更多的产品能力。
8.参考文献
[1]中国信通院《下一代数据存储技术研究报告(2021年)》
[2]魏星达,陈榕,陈海波.基于RDMA高速网络的高性能分布式系统[J].大数据, 2018, 4(4): 3-14
[3]陈游旻,陆游游,罗圣美,舒继武.基于RDMA的分布式存储系统研究综述[J].计算机研究与发展,2019,56(02):227-239.
[4]白子秋,胡怀湘.基于用户态的NVMe驱动设计[J].计算机应用与软件,2019,36(01):28-33+146.
[5]徐城璋. DPDK在虚拟机热迁移中的设计与实现[D].东南大学,2020.DOI:10.27014/d.cnki.gdnau.2020.004407.
[6]SPDK,https://SPDK.io/doc/intro.html
1

客服QQ:30444492琼网文【2021】1550-113号
增值电信业务经营许可证:琼B2-20210322
出版物经营许可证:新出发龙华出字第(2021)009号
广播电视节目制作经营许可证:(琼)字第00779号
版权所有 ©2002-2024 期刊网 琼ICP备2021005105号



