中国铁路北京局集团有限公司北京通信段
摘要:随着铁路通信技术的发展,通信故障分析面临人工分析效率低、出错率高、底层数据量大、故障原理复杂等问题。新一代基于大语言模型的人工智能技术在数据处理方面有较强优势,如数据特征分析、模型微调训练、多业务模型统一等,为通信故障分析及定位问题提供了新思路。本文对新一代人工智能和传统人工智能在通信故障分析及定位的差异进行了详细综述,探讨了新一代人工智能技术的优势和存在问题的解决方式,并对未来发展进行了展望。
关键词:人工智能;故障分析;大语言模型;模型微调
1 引言
随着铁路通信技术的不断发展,故障分析成为确保通信系统稳定运行的重要环节。在传统的故障分析方法中,主要依赖于专业能力强的工程师进行人工分析,这不仅对工程师的技术水平和经验提出了很高的要求,而且在面对复杂和大规模的通信系统时,人工分析的效率较低,容易出错,导致通信故障分析延时较长。
为了提高分析效率和准确性,近年来,研究者尝试引入人工智能技术进行通信系统的故障分析。尤其是基于传统机器学习和深度学习技术的传统人工智能分析方法,它们针对特定的问题建立了具体的故障分析模型。然而,这种方法存在一定的局限性:首先,它需要进行大量的前期特征工程工作;其次,为每个具体问题训练特定的模型,需要做大量的模型训练工作,不仅增加了研发的复杂度,也增大了研发成本。
在这种背景下,新一代人工智能大语言模型的出现为通信系统故障分析带来了新的机遇。利用大语言模型,我们可以训练一个涵盖整个车间甚至整个站段的通信系统故障的通用模型。相较于传统方法,这种方法能够用一个或几个少量的大模型来解决整个通信系统的故障分析问题,从而大幅度降低了系统研发的复杂度和投入成本,为未来的通信系统故障分析提供了新的解决方向。
2 智能化故障分析实现差异
智能化故障分析系统可以细分为两大核心部分:应用系统层与算法模型层。
(1)应用系统层:该层主要承担数据接入与预处理的任务。它从各种网管系统中获取数据,然后进行一系列的结构化处理。这包括关联数据的整合、初步的数据清洗和预处理等操作。数据处理完成后,应用系统层将调用下一层的算法模型进行故障预测和分析。
(2)算法模型层:这一层是整个智能化故障分析系统的决策核心。其中,主要分析模型负责对整体数据进行故障的判断与分析。当主要算法模型对某一故障的预测结果在两个或更多分类的置信度相差无几时,系统会进一步调用个别问题专用算法模型进行深度分析,确保故障的准确性与精度。
通过这两层的协同工作,系统能够实现对故障的高效、准确的预测和分析,满足现代通信网络对故障检测和处理的高标准要求。
2.1 传统人工智能故障分析的局限性
如图2-1所示,为构建一个完善的故障分析系统,首先需要对可能发生的故障进行全面的识别分析。例如,铁路通信可能会遇到的故障类型有:“C3超时降级”、“进路预告异常”、“车机联控故障”等。对于每一种故障,必须进行针对性的分析,构建对应的特征工程,随后将经过特征处理后的数据送入相应的算法中进行模型训练。
若从宏观角度构建一个能够分析整个网络系统的故障智能化分析系统,使用上述方法会带来多重挑战:
(1)模型的数量与复杂度:由于每个模型往往只能针对分析一个具体的故障问题,一个部门的故障分析功能可能需要几十个甚至数百个机器学习模型。这不仅大大增加了系统的复杂度,也对存储和计算资源提出了更高要求。
(2)研发资源消耗:模型的数量众多意味着大量的人力和技术成本投入。每种故障都需要从数据收集、特征工程到模型训练的完整流程。
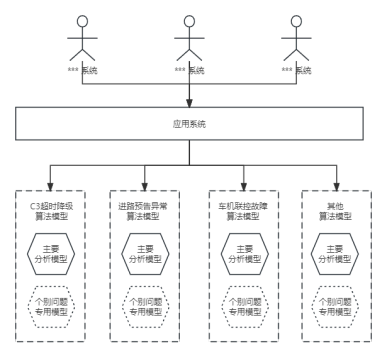
图2-1 传统人工智能故障分析系统
(3)模型融合与扩展性:各个模型之间的融合难度较大,这意味着对于新出现的故障类型,很难直接使用或扩展现有模型,而需重新建模,这大大降低了系统的灵活性和扩展性。
综上所述,对于复杂的通信系统,传统的人工智能故障分析方法在模型数量、研发资源消耗、模型融合与扩展性上都面临着较大的挑战。因此,探索新的方法和技术,以更高效、灵活地解决通信系统的故障分析问题,已成为当务之急。
2.2 基于大语言模型智能故障分析的优越性
现代故障分析系统的创新之处在于采用了“基于大语言的分析算法”,这一变革有效地替代了传统人工智能算法模型层中的多个主要分析模型。这意味着,仅通过一个单一的模型,我们便能够处理众多的故障分析任务。值得注意的是,当系统中新增一种故障时,无需完全重新开发一个新的模型。相反,我们只需在原有的基于大语言的分析算法模型上进行适当的微调,即可适应新的故障类型。
与传统的人工智能算法模型相比,基于大语言的故障分析算法模型带来了以下显著优势:
(1)多功能性:单一模型能够分析多种通信故障,这大大简化了故障分析流程,使其更为高效和稳健。
(2)高度通用性:模型具有广泛的适应性,减少了在不同故障场景中转换和使用不同模型的需求。
(3)简化的实现:基于大语言的模型具有出色的自适应能力,大幅减少了传统的特征工程和模型调优过程,从而简化了系统的实现难度。
(4)成本效益:由于不需要频繁地开发和训练新的模型,这种方法能够明显地降低开发和运营成本。
综上所述,通过采纳基于大语言的分析算法,我们不仅提高了通信故障分析的效率和准确性,而且实现了更为经济、高效的系统开发和维护流程。
3 模型训练过程中的差异
智能算法模型训练流程一般涵盖三大核心环节:数据准备、数据处理、模型训练以及模型评估。
3.1 数据准备
在这一阶段,重点是聚合和组织所需的数据资源。这些数据多来源于不同的网管系统,呈现结构化的形态,同时,也包括了人工进行的故障标注结果,为模型训练提供了基准标签。
3.2 数据处理
数据处理是将原始数据转化为模型可读、可学习的形态的过程。具体来说:
(1)数据预处理:此环节对收集来的数据进行清洗、去噪、填充缺失值等操作,确保数据的质量和完整性。
(2)数据特征分析与构建:依据数据的内在属性和分布特性,选择或构建出有助于模型训练的特征。
(3)数据集拆分:将处理后的数据集按一定比例拆分为训练集、验证集和测试集,为模型的训练和性能评估提供支持。
3.3 模型训练
模型训练是通过选定算法,使用训练数据集使模型学习并优化其预测能力,具体来说:
(1)算法选择:根据训练数据的特性以及预期的任务要求,筛选出适合的学习算法。
(2)模型训练:利用已选择的算法,基于训练集进行模型的学习。
3.4 模型评估
采用验证集对模型的性能进行评估,探索模型在未知数据上的泛化能力,具体来说:
(1)选择评估指标:根据问题的性质选择合适的评估指标。例如:准确率、召回率、精确度、F1分数、AUC-ROC等。
(2)测试集预测:使用训练集对模型进行训练,并使用测试集(有时是验证集)进行预测。
(3)多模型对比:如果有多个模型或算法,对它们的性能进行比较,确定哪一个的性能最佳。
结合模型评估的反馈结果,我们可以决定是否需要对数据处理和模型训练环节进行多次迭代优化,以确保最终的算法模型达到理想的预测水平。
4 传统智能模型的训练过程
以“C3超时降级”分析模型及“进路预告异常”训练为例,我们探究了传统智能模型训练中所面临的问题。在传统的方法中,由于训练数据源自多种网络管理系统,再加上人工标注的差异性,使得数据处理和模型训练的各个环节在对数据操作时具有不同的特性和需求。这种情境下,模型的开发往往呈现出高度的定制化和专用性,给企业和研发团队带来了巨大的挑战。各种不同的故障或异常都要单独为其定制化开发模型,而这无疑增加了整体系统的研发复杂性和经济成本。
5 基于大语言模型的训练过程
如图5-1所示,以“C3超时降级”分析模型及“进路预告异常”训练为例,将两者的数据统一进行数据处理,在数据特征分析和构建时,与传统智能模型的数据处理过程有所区别,在数据特征分析和构建阶段,我们引入了数据故障类型的标注,明确标出了是“C3降级”还是“进路异常故障”,并融合了网络管理系统的网络拓扑图数据,这种方法能够帮助大语言模型深入地分析在不同的网络拓扑状态下导致的不同故障类型。在模型训练环节有较大的改变,这里选择了一些有网络拓扑识别能力的大语言模型,在这个模型基础上使用数据处理阶段产出的数据进行微调训练,这样就可以再训练出一个通用故障分析模型。当新增一个故障类型时,我们不再需要从头开始建模,仅通过对现有模型的微调,便可实现对新故障类型的准确分析。
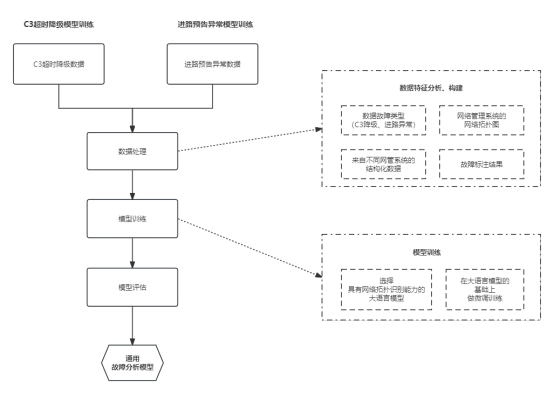
图5-1 大语言模型的训练过程
6 总结
在本文中,我们通过对“C3超时降级”和“进路预告异常”这两种故障模式进行了深入的研究,发现基于大语言模型的故障分析方法在处理这些复杂问题时具有明显的优越性。
首先,与传统的人工智能模型相比,大语言模型允许我们在统一的框架内对多种故障模式进行处理。这种统一化的处理避免了为每种故障单独开发模型的繁琐过程,从而大大减少了开发的难度和成本。
其次,大语言模型在模型训练环节也有其独特之处。它允许我们在一个预先训练好的模型上进行微调,从而迅速适应新的通信故障分析。这种方法不仅缩短了模型的研发周期,还为模型提供了更高的适应性和灵活性。
总之,基于大语言模型的故障分析方法与传统的人工智能模型相比,不仅具有更高的精准度、更大的通用性,还显著降低了系统的开发难度和成本。这为铁路通信系统的故障分析提供了一种更为高效和经济的解决方案。
参考文献
【1】Long Ouyang, Jeff Wu, Xu Jiang, Diogo Almeida, Carroll L. Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schulman, Jacob Hilton, Fraser Kelton, Luke Miller, Maddie Simens, Amanda Askell, Peter Welinder, Paul Christiano, Jan Leike, and Ryan Lowe. Training language models to follow instructions with human feedback, 2022.
【2】Wayne Xin Zhao, Kun Zhou, Junyi Li, Tianyi Tang, Xiaolei Wang, Yupeng Hou, Yingqian Min, Beichen Zhang, Junjie Zhang, Zican Dong, Yifan Du, Chen Yang, Yushuo Chen, Zhipeng Chen, Jinhao Jiang, Ruiyang Ren, Yifan Li, Xinyu Tang, Zikang Liu, Peiyu Liu, Jian-Yun Nie, and Ji-Rong Wen. A Survey of Large Language Models, 2023.

客服QQ:30444492琼网文【2021】1550-113号
增值电信业务经营许可证:琼B2-20210322
出版物经营许可证:新出发龙华出字第(2021)009号
广播电视节目制作经营许可证:(琼)字第00779号
版权所有 ©2002-2024 期刊网(www.qikanchina.com) 琼ICP备2021005105号



