2工程应用
2.1 数据来源与选取
本次选取呼和浩特回民区万达广场基坑监测点E1的竖直位移累计数据来作为本文的研究数据,选取前6天的竖直位移累计数据作为输入变量,当天的竖直位移累计数据作为输出变量。
2.2 数据预处理
2.2.1 EEMD分解
采用EEMD分解将原始数据分为4个IMF分量和一个剩余分量如图1所示,IMF1-IMF4的频率从高到底,表明其复杂程度越来越小,分量越来越稳定,RES是EEMD分解的剩余向量,代表了原始数据随时间的变化趋势,说明基坑的竖直位移累计量总体上是上升的。
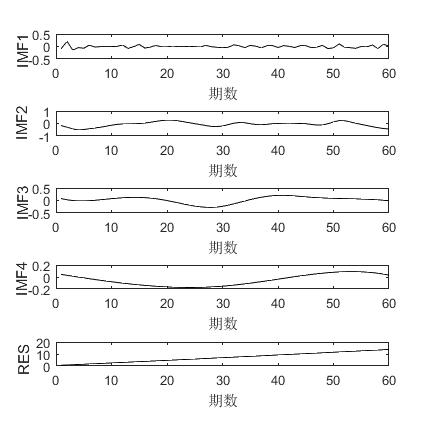
图1 EEMD分解结果
2.2.2 归一化处理
为了消除由于各输入变量不在一个量纲所导致预测精度降低的影响,需对输入变量进行归一化处理。本文采用mapminmax函数将输入变量归一化的[-1,1]之间,其公式为:
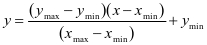 (1)
(1)
2.3 模型参数初始化
经反复试验确定种群数量50,种群最大迭代次数300,学习因子c1和c2分别为1.5和1.7,惯性权重w采用公式(2)确定
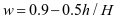 (2)
(2)
式(2)中h代表当前种群更新次数,H代表种群最大更新次数,粒子的最大更新速度Vmax为1,SVM的参数c和g取值范围分别为[2
-8,28]和[2-8,28]。
2.4 预测结果及分析
以各分量前50期数据为训练样本,后10期数据为测试样本,分别利用PSO-SVM模型对各分量进行建模预测,从而得到EEMD-PSO-SVM对各分量的仿真结果,仿真结果如图2所示。由图2可以看出,本次整体仿真精度较好,各分量越稳定,预测精果越好。对各分量的后10期数据进行叠加重构,得到最终的预测结果。
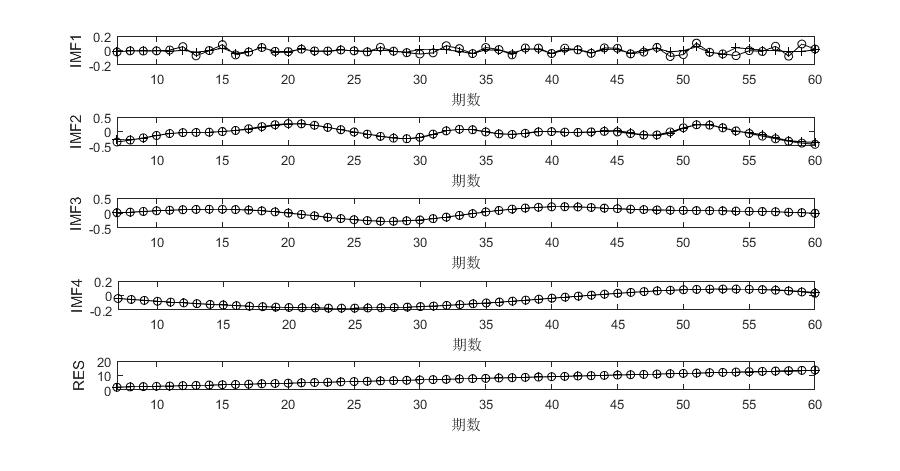
图2 EEMD-PSO-SVM各分量仿真结果
与此同时,为了体现优化后的模型在预测结果上的优越性,分别采用SVM模型和PSO-SVM模型对原始基坑监测数据进行建模预测,对比结果如表1所示。由表1数据可知,EEMD-PSO-SVM模型在基坑变形预测上的精度是最高的,其最大相对误差出现在第59期为3.685%,最小相对误差出现在第54期为0.621%;SVM模型最大相对误差出现在第60期为7.472%,最小相对误差出现在第54期为4.141%;PSO-SVM模型最大相对误差出现在第60期为5.866%,最小相对误差出现在第54期为2.823%。为了更好的说明EEMD-PSO-SVM模型在对基坑变形预测的有效性,通过平均绝对值误差(MAE)和均方根误差(RMSE)来评定3种模型的预测精度。经计算EEMD-PSO- SVM模型预测样本的平均绝对值误差0.237 mm,均方根误差为0.276 mm;PSO-SVM模型预测样本的平均绝对值误差为0.542 mm,均方根误差为0.561mm;SVM模型预测样本的平均值绝对误差为0.706 mm,均方根
误差为0.723 mm。因此,本文所采用的预测模型相较于SVM模型和PSO-SVM模型在基坑变形预测的精度上有了一定的提高,可以较好的应用于基坑的变形预测。
表1 3种模型预测结果对比表
观测期数 | 期望值 | SVM模型 | PSO-SVM模型 | EEMD-PSO-SVM模型 | |||
预测值 | 相对误差 | 预测值 | 相对误差 | 预测值 | 相对误差 | ||
/mm | /(%) | /mm | /(%) | /mm | /(%) | ||
51 | 12.2 | 11.488 | 5.833 | 11.581 | 5.075 | 12.073 | 1.043 |
52 | 12.3 | 11.690 | 4.962 | 11.842 | 3.722 | 12.203 | 0.783 |
53 | 12.4 | 11.852 | 4.419 | 12.020 | 3.066 | 12.254 | 1.176 |
54 | 12.5 | 11.982 | 4.141 | 12.147 | 2.823 | 12.422 | 0.621 |
55 | 12.7 | 12.079 | 4.886 | 12.234 | 3.670 | 12.533 | 1.312 |
56 | 12.8 | 12.171 | 4.912 | 12.327 | 3.694 | 12.616 | 1.434 |
57 | 13 | 12.240 | 5.849 | 12.401 | 4.609 | 12.667 | 2.562 |
58 | 13 | 12.299 | 5.390 | 12.484 | 3.972 | 12.707 | 2.253 |
59 | 13.3 | 12.339 | 7.227 | 12.527 | 5.814 | 12.810 | 3.685 |
60 | 13.4 | 12.399 | 7.472 | 12.614 | 5.866 | 12.939 | 3.439 |
3 结 语
本文针对传统SVM模型预测能力很大程度上依赖其参数的选取以及基坑监测数据存在非平稳、非线性等问题,采用EEMD对原始基坑监测数据进行分解,同时利用PSO算法对SVM模型的参数进行优化,建立起了EEMD-PSO-SVM基坑变形预测模型。实验表明,相较于SVM模型和PSO-SVM模型,EEMD-PSO-SVM模型在预测精度上有了一定的提高,为基坑变形预测提供了一种新的思路。
参考文献
薛贝,蔺小虎,刘长星,等.基于回归模型的广场基坑沉降预测分析[J].地理空间信息,2018,16(9):107-109.
赵利民,高昂,齐永波,等.基于时间序列分析的露天矿边坡沉降预测模型[J].测绘工程,2017,26(9):46-50.
吴飞宇.基于灰色神经网络模型的基坑变形预测研究[J].测绘通报,2013(S1):189-191.
董雁萍.支持向量机预测模型的构建及其应用[D].西安理工大学,2010.
陈继光.基于支持向量机模型的建筑物沉降预测[J].数学的实践与认识,2013,43(12):137-140.

客服QQ:30444492琼网文【2021】1550-113号
增值电信业务经营许可证:琼B2-20210322
出版物经营许可证:新出发龙华出字第(2021)009号
广播电视节目制作经营许可证:(琼)字第00779号
版权所有 ©2002-2024 期刊网(www.qikanchina.com) 琼ICP备2021005105号



