(江南机电设计研究所 贵州贵阳 550009)
摘要:针对传统方法难以处理动态目标分配同时深度强化学习方法动作空间不匹配问题,本文提出了多维离散动作近端策略算法,从实验结果可以看出,该方法适应于解决多维动态目标分配问题,能够显著提升全局结果。
关键词:动态目标分配;深度强化学习
1.引言
动态目标分配问题是考虑如何通过多次决策分配从而取得最优结果的问题,传统的求解方式是利用以遗传算法为代表的各类优化算法进行求解,但是其问题在于使用该类算法只能考虑单步的分配,难以达到全局最优的结果。针对于此,本文提出了多维离散动作近端策略算法(DMDP),该方法利用深度强化学习理论,通过对网络结构的调整使其具备高效的多维离散动作处理能力。试验证明该方法极大地提升了动态目标分配的效果。
2.深度强化学习概述
人工智能领域一个非常重要的目标就是创造一个可以和环境交互,能够在试错过程中学习的完全自主的智能体。强化学习普遍被认为是通往这个目标的重要途径。强化学习也称为再励学习或者增强学习,用以解决智能体和环境交互过程中通过反馈信息进行学习从而实现从环境中获得最大奖励回报的问题,根据奖励的定义不同可用来实现特定的问题达成指定的目标。但是该方法缺乏扩展性,只能用于解决一些低维的问题。同时,强化学习算法也同其它算法一样,受限于记忆复杂性、计算复杂性以及抽样复杂性等问题。这些问题在很长的一段时间里限制了强化学习的发展,令其处于停滞的状态,一直到深度学习的崛起。深度学习中所使用的多层神经网络具有强大的函数拟合能力以及强大的表征学习能力。而这些能力也正是强化学习为克服上述种种问题所必须的能力。通过与深度学习的结合,强化学习的发展获得了新的动力源,同时二者的结合也产生了深度强化学习这样一个新的方向。其可以看作是人工智能中连接主义与行为主义的交叉,通过深度学习强大的表达能力与强化学习的决策能力的结合,深度强化学习得以通过端到端的方式实现从原始输入到输出的直接控制,大大增强了强化学习的灵活性以及复杂性。现在,深度强化学习技术已经延伸向各个领域,也改变了这些领域的传统格局,包括自动驾驶、机器人、推荐系统甚至是核聚变控制。
3.多维离散动作近端策略算法设计
3.1近端策略优化方法
首先回顾一下策略梯度方法。策略梯度方法通过梯度上升调整策略网略的参数![]() 以最大化目标
以最大化目标![]() 。更进一步,在此基础上,改变得到
。更进一步,在此基础上,改变得到![]() 的方式,可以得到Actor-Critic方法,其Actor网络的梯度一般形式为
的方式,可以得到Actor-Critic方法,其Actor网络的梯度一般形式为![]() 。其中,
。其中,![]() 为优势函数,是对动作
为优势函数,是对动作![]() 优劣更具体的估计,具有多种形式。
优劣更具体的估计,具有多种形式。
Schulman在文献[1]中提出了置信区间策略优化方法(Trust Region Policy Optimization, TRPO),其主要指出在对策略网络做策略梯度时,具有一个策略的置信区间,如果当前策略与获取数据的策略差异过大,那么此时所做的梯度上升不具有可信度,甚至会对网络效果有所损害。随后,在文献[2]中提出了裁剪替代目标(Clipped Surrogate Objective),以解决TRPO理论无法实际应用的问题。其具体形式为:![]() 。
。
3.2多维离散动作近端策略算法
对于本文面对的目标分配问题来说,想要运用强化学习的方法,最大的问题在于如何设定智能体的动作。本文提出使用多维离散动作,并针对实际应用中存在的非法动作进行遮掩(mask)。
1)多维离散动作
传统强化学习中的单纯离散动作空间并不适用于目标分配问题。首先可以确定,该问题的动作空间仍应归为离散动作空间,在基于策略的强化学习中,Actor网络输出为“单一动作”![]() 。在动态目标分配场景中,“单一动作”意味着一个分配组合。最终输出动作为
。在动态目标分配场景中,“单一动作”意味着一个分配组合。最终输出动作为![]() ,
,![]() ,也就是说我们的“单一动作”
,也就是说我们的“单一动作”![]() 代表了最终输出的动作
代表了最终输出的动作![]() ,在当前场景中
,在当前场景中![]() 就会有
就会有![]() 种可能。此时神经网络输出层就需要具有
种可能。此时神经网络输出层就需要具有![]() 个神经元。这样的方式会导致神经网络具有过于庞大的参数量。算力难以支持,其次动作空间太大难以收敛。再者将输出的单值与实际动作进行对应也会非常复杂。这样的方式效率极其低下,也会导致根本无法应用于实际问题。
个神经元。这样的方式会导致神经网络具有过于庞大的参数量。算力难以支持,其次动作空间太大难以收敛。再者将输出的单值与实际动作进行对应也会非常复杂。这样的方式效率极其低下,也会导致根本无法应用于实际问题。
针对上述问题,本文采取使用多维离散动作取代“单一动作”的方式。用动作组合![]() 来表示“单一动作”
来表示“单一动作”![]() 。其中
。其中![]() 表示了第
表示了第![]() 个火力单元的动作。
个火力单元的动作。
于是,原本的![]() 就由10个维度更低的“单一动作”组合而成。回溯到神经网络的输出层,此时只需要
就由10个维度更低的“单一动作”组合而成。回溯到神经网络的输出层,此时只需要![]() 个神经元。
个神经元。
对于一般的Actor-Critic方法,以离散动作空间为例,其动作输出为单一动作,其Actor网络的梯度为![]() ,Masked多维离散近端策略以自动作组合的方式取代式子中的动作。此时Actor网络的梯度变为了:
,Masked多维离散近端策略以自动作组合的方式取代式子中的动作。此时Actor网络的梯度变为了:![]() 。
。
2)遮掩
关于动作空间的另一个问题是,在具体执行中,会有许多动作为非法动作。需要避免策略网络输出这样的非法动作。本文中通过对策略网络输出值做遮掩的方式,把非法输出值的位置遮挡住。通过遮掩处理,大大降低了训练难度,提升了效率。
经过多维离散以及遮掩之后,所得到的动作,维度足够低并且符合目标分配的合法表达。为了实现上述方法,设计多维离散动作近端策略算法的网络结构如图1所示。
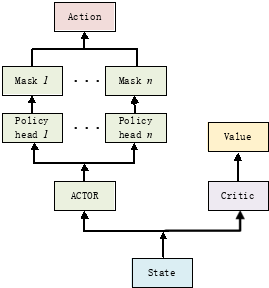
图1多维离散动作近端策略算法的网络结构
Actor接收状态信息State输出向量![]() ,随后将输出切分为
,随后将输出切分为![]() ,把
,把![]() 输入对应的策略头Policy head i。策略头可以看做更具体到了每一分配单元。在策略头得到输入后,根据当前情况做遮掩,遮挡住不合法的维度。最后每个头输出当前分配单元所有合法动作的概率的对数。并据此选取每个分配单元的动作,最后将所有动作组合得到最终的动作
输入对应的策略头Policy head i。策略头可以看做更具体到了每一分配单元。在策略头得到输入后,根据当前情况做遮掩,遮挡住不合法的维度。最后每个头输出当前分配单元所有合法动作的概率的对数。并据此选取每个分配单元的动作,最后将所有动作组合得到最终的动作![]() 。
。
具体算法步骤如下:
算法1DMDP |
for iteration=1,2,... Run policy If buffer_size=update_size do for update=1,2,...,update_times do Input buffer Compute advantage estimates Compute Update end for Clear buffer end for |
3.3实验
本文使用某动态目标分配场景用以对算法进行验证,用以对比的是经过调整的遗传算法(TGA),通过对比已证明了该方法相比于其它寻优算法对于动态目标分配具备最优的效果。令TGA算法在动态目标分配场景中运行10次,并令DMDP算法在场景中训练5次,绘制结果如图:
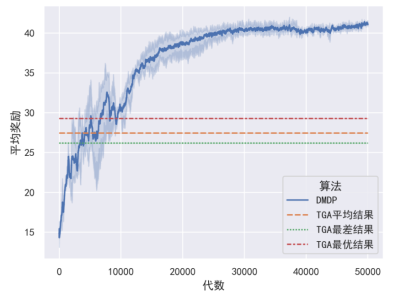
图2试验结果对比结果
可以看到由于DMDP算法的结果在短暂训练后远远超过TGA方法的最优结果。证明了DMDP算法适应于处理动态目标分配问题。
4.结论
本文针对动态目标分配的难点以及深度强化学习处理动态目标分配动作空间无法适应的问题。通过调整网络结构构建新的学习方式,设计多维离散动作近端策略算法,为解决多维动态目标分配问题提出了新的解决思路。
参考文献:
[1]Schulman J , Levine S , Moritz P , et al. Trust Region Policy Optimization[J]. Computer Science, 2015:1889-1897.
[2]Schulman J , Wolski F , Dhariwal P , et al. Proximal Policy Optimization Algorithms[J]. 2017.

客服QQ:30444492琼网文【2021】1550-113号
增值电信业务经营许可证:琼B2-20210322
出版物经营许可证:新出发龙华出字第(2021)009号
广播电视节目制作经营许可证:(琼)字第00779号
版权所有 ©2002-2024 期刊网(www.qikanchina.com) 琼ICP备2021005105号



