中南林业科技大学涉外学院,湖南 长沙 410004
【文章摘要】:在大数据时代,电商平台出现了海量的评论数据,提取用户反馈进行数据挖掘,以直观的方式展现出来,可以帮助商家更好地了解客户需求,改进产品质量,从而提高客户满意度。本文爬取了京东平台上联想笔记本5万多条消费者评论数据,并基于LDA模型进行主题分析。研究结果表明,该品牌笔记本具有速度快、外观美观、轻薄等优点,但散热、包装、屏幕清晰度方面还需要改进,本研究所得结论可以为商家提供决策支持。
【关键词】:用户反馈;主题模型;可视化
一、引言
随着电子商务的迅速发展和网络购物的流行,人们对于网络购物的需求变得越来越高,电商交易背后产生海量评价数据,给商家带来的信息过载、检索低效等问题。查看电商评论数据可以掌握客户的购物体验,使商家及时掌握客户反馈信息,从而提升产品和服务。因此迫切需要一种技术,充分挖掘客户评论数据的价值。本文以京东平台商品的评论数据为例,以联想笔记本为目标商品,采用LDA模型分析评论数据,从评论文本中挖掘出用户的需求,通过可视化的方式进行展示,根据模型结果给出改善产品的建议。
二、主题模型
“LDA全称隐含狄利克雷分布(Latent Dirichlet Allocation, LDA), 是一种主题模型,它可以自动分析每个文档,统计文档中的词语,根据统计的信息判断当前文档包含哪些主题以及各个主题所占比例各为多少。该模型认为文档是主题的概率分布,而主题是词汇的概率分布。基于该思想,模型从文档—主题、主题—词汇两个方面建模,描述文档、词汇以及主题三层结构之间的生成关系[1],如图 1 所示。
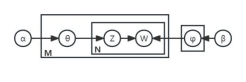
图1 LDA主题模型[2]
其中,M 表示语料库的评论数量,N 表示每条评论的词汇量,α、β 分别服从狄利克雷分布。LDA主题模型是文档生成的逆过程,对于评论 D,从先验概率分布抽样产生其在主题上的概率分布 θ,并根据文档—主题分布采样获得评论 D 中第 k 个词汇的主题 Z; 对于主题 Z,从先验概率分布 β 抽样产生其词汇分布φ,并根据主题—词汇分布φ抽样生成词汇W。
三、主题模型在电商平台的应用
1、评论文本数据采集
以京东联想笔记本电脑为数据源,通过Python的Scrapy框架采集销量最高的前12页数据,每页30台,每台每页10条评论,共15页评论,预处理后,总共搜集了累计4万多条消费者评论,每条评论信息包括2个字段:评论ID、评论文本,爬取数据保存到csv文件中。
2、评论文本数据预处理
获取评论原始数据后,文本评论数据中存在大量的无价值信息,所以对反馈文本评论先进行预处理是必不可少的一步。通过预处理提高数据的有效性、可靠性和真实性,主要包括以下4个步骤:
(1)文本清洗。首先进行文本去重,去除评论文本中反复出现的数据,买家没有评论时,系统默认好评,对于重复评论,使用drop_duplicates()方法删除重复评论。原始评论数量为56307,清洗后评论数量为43385,数据有效率为77.05%。
(2)分词。利用jieba对京东联想笔记本评论文本进行分词。
(3)去停用词。根据停用词表去除“许多”“比如”“&”等停用词。
(4)去高频词/无意义词。“京东”“京东商城”“联想笔记本”和“非字母数字”字符等文本对分析目标毫无意义,如果不处理这些文本将会影响结果的准确性。首先,使用content.apply(lambda x: str.sub('',str(x)))去除出现频率较大的京东、联想、笔记本、数字字母等无意义文本,使用lambda s : [[x.word,x.flag] for x in psg.cut(s) if len(x.word)>1]过滤掉长度为1的文字,其次删除标点符号和动词,最后人工去除无意义的高频词。
3、评论文本分析和可视化
(1)评论数据情感倾向分析。首先匹配情感词。情感倾向是指用户对商品持支持、反对还是中立的态度。分为正面情感、负面情感和中性情感。本实验使用知网发布的“情感分析用词语集”,给正面情感词语赋予初始权重1,作为正面评价情感词表。给负面情感词语赋予初始权重-1,作为负面评价情感词表。网络购物评论中出现的“超值”“好评”“差评”“五分”“满意”“超好”等词添加至对应的情感词表中。其次,修正情感倾向。根据情感词前面两个位置的词语是否存在否定词而去判断情感值的正确与否,出现奇数次是否定,出现偶数次表示肯定。否定词包括“不、没、无、非、莫、未、否、别、不是“等19个。从而提高计算情感分析的准确率。最后,提取正面评论与负面评论,情感值大于0表示正面评论类型,情感值小于0表示负面评论类型。
(2)LDA主题模型。首先,建立词典和语料库。Corpora.Dictionary类为每个出现在语料库中的单词分配一个独一无二的整数编号id,以便收集单词计数及其他相关的统计信息。需要从大量语料中提取特征,计算机只认识数据,所以需要将这些文本特征变换为数值特征。转换结果,如(8,3)表示文档中id为8的单词出现了3次。其次,寻找最优主题数。本实验是基于余弦相似度确定主题数并进行主题分析。训练模型时使用的最大单词数量设置为5,正面情感的第一个主题结果为(0, '0.054*"速度" + 0.050*"外观" + 0.036*"很快" + 0.021*"不错" + 0.021*"轻薄" ),负面情感的第一个主题结果为(0, '0.118*"效果" + 0.053*"包装" + 0.047*"清晰" + 0.044*"散热" + 0.043*"画面" )。
(3)pyLDAvis可视化。
通过pyLDAvis库进行可视化分析。首先调用gensim库的prepare(pos_lda,pos_corpus,pos_dict)方法,然后通过display方法以网页的形式呈现。正、负面情感分别如图2、图3所示。

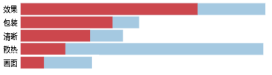
图2 正面情感评价 图3 负面情感评价
四、结语
大数据技术为电商赋能。本文针对电商平台的用户反馈数据提出了基于LDA模型的数据可视化方法,助力商家快速掌握用户评论的关键内容。理论上,创新性地引入LDA对用户评论进行分析,实践上,本研究得出结论,笔记本电脑应注重包装、屏幕清晰度、散热等方面的改进,该研究结果可以为电商网络营销提供依据。
文献参考:[1]颜端武,梅喜瑞,杨雄飞等.基于主题模型和词向量融合的微博文本主题聚类研究[J].现代情报,2021,41(10):67-74.
[2]Blei D M,Ng A Y,Jordan M I. Latent Dirichlet Allocation [J]. Journal of Machine Learning Research,2003,( 3) : 993-1022.
基金项目:基于市场反馈的可视化分析系统(项目编号20220102)。

客服QQ:30444492琼网文【2021】1550-113号
增值电信业务经营许可证:琼B2-20210322
出版物经营许可证:新出发龙华出字第(2021)009号
广播电视节目制作经营许可证:(琼)字第00779号
版权所有 ©2002-2024 期刊网(www.qikanchina.com) 琼ICP备2021005105号



